Have you ever wondered how powerful language models like GPT-3 understand and generate human-like text? This blog will take you on a journey into the fascinating world of language model training.
We'll start by exploring the massive amounts of data collected from the internet to teach these training models about real-world language patterns.
Then, dive into the intricate neural network architectures like Transformers that allow models to learn from data.
You'll learn how techniques are used in the iterative training process to continuously improve performance.
You will also see the challenges of preventing model training from simply memorizing data and how to efficiently process massive amounts of information.
By the end of this blog, you'll have a comprehensive understanding of the complex yet impressive process behind developing these powerful language models. So, let’s begin our blog with LLM model training data.
Training Data
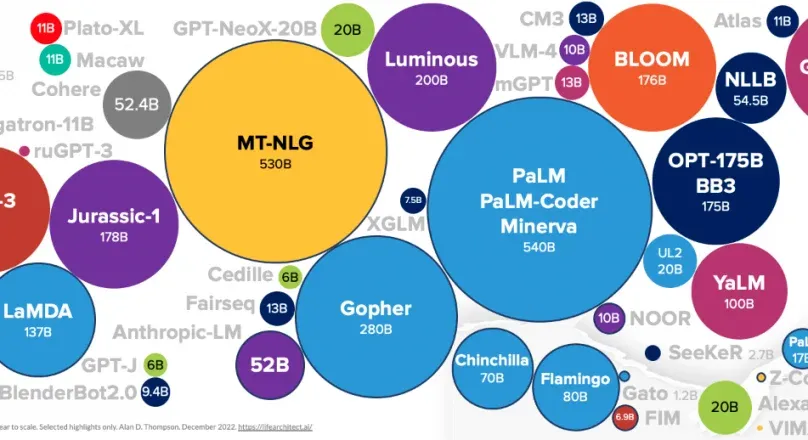
The selection and preparation of the LLM training model data is a crucial first step. Model training needs diverse, relevant, clean data to learn and generate language accurately.
Sources and Types of Data Used for Training
Many public text sources, including books, articles, websites, and social media are used for training large language models. Text corpora from domains like news, research, and forums are also used.
Researchers combine different data sources and types to capture various language patterns, contexts, and meanings.
Preprocessing and cleaning the data
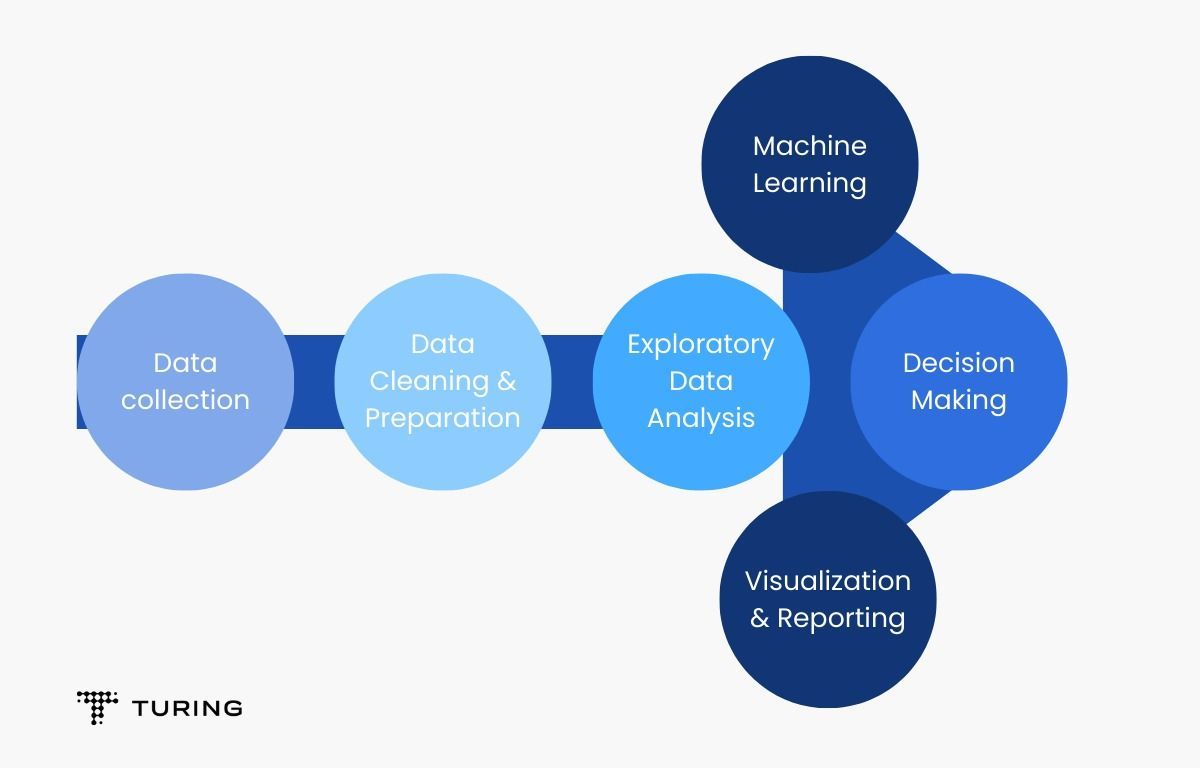
Before the LLM training model, The data must be preprocessed and cleaned. It undergoes tokenization, splitting text into tokens like words and punctuation.
Various cleaning techniques remove irrelevant elements such as HTML tags and special characters. Text normalization standardizes word forms.
Additional cleaning removes duplicate, corrupted, or outlier data points to reduce biases and noise, improving the model training quality and effectiveness.
Model Architecture
The LLM training model generally uses deep learning techniques such as neural networks to learn the statistical relationships and patterns in language data.
Typically, these model training are trained to handle various tasks related to natural language processing, including question answering, sentiment analysis, text categorization, and language synthesis.
The transformer architecture is a well-known kind of design for big language models. To analyze sequential input, such as text written in natural language, the transformer is a deep learning architecture that combines attention mechanisms with feedforward neural networks.
Particularly in language production and translation tasks, the transformer architecture has demonstrated promising performance in various natural language processing applications.
Deep dive into the components and layers of the model
At a high level, the transformer architecture consists of an encoder and a decoder.
The encoder processes the input text to extract useful features and representations, while the decoder uses those representations to generate new text.
The encoder comprises a stack of identical layers, each containing a multi-head self-attention mechanism and feedforward neural network.
The decoder also comprises a stack of identical layers, each with an attention mechanism over the encoded input and a feedforward neural network.
This lets the decoder focus on important input parts to generate the output sequence.
Training Process
The training process of the LLM training model involves careful data preparation, parameter initialization, optimization techniques, and fine-tuning and transfer learning.
The process is iterative, adjusting parameters until the desired performance is achieved.
Data preparation and batching
The raw data is first preprocessed, tokenized, and cleaned. Once prepared, it is divided into batches for more efficient processing during model training by feeding the model multiple examples simultaneously.
Batching helps parallelize computations and optimize memory usage, important considerations for the LLM training model on vast amounts of data.
Parameter initialization and optimization techniques
Before the LLM training Model, parameters are initialized, commonly using random initialization or pre-trained word embeddings like Word2Vec or GloVe, which capture semantic relationships and help the model generalize better.
During training, optimization techniques like stochastic gradient descent (SGD) are used to update parameters to minimize loss.
SGD iteratively computes gradients of the loss function with respect to parameters and adjusts them in a direction that reduces loss.
Suggested Reading:
Gradient Descent and Backpropagation
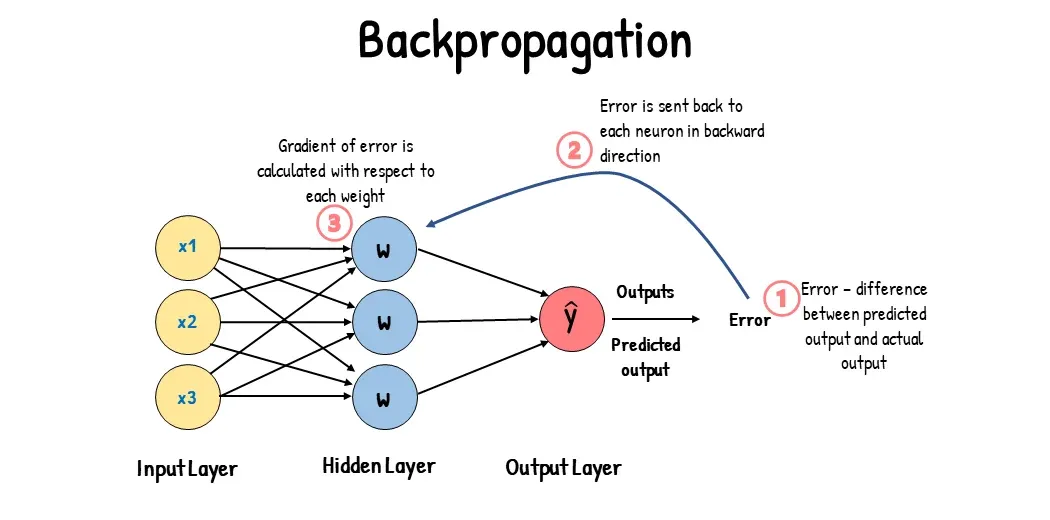
Gradient descent involves computing gradients of the loss function with respect to parameters, representing the direction to minimize loss.
Backpropagation efficiently computes these gradients by propagating them backward through the network.
In backpropagation, gradients are computed from the output layer to the input layer, updating parameters layer by layer and gradually improving performance over time.
Fine-tuning and transfer learning
Fine-tuning involves taking a pre-trained model and further training it on a smaller, domain-specific dataset, helping the model adapt to specific language patterns and contexts of the target task.
Transfer learning leverages a pre-trained model as a starting point instead of model training from scratch, allowing the model to apply learned general language patterns to a wide range of NLP tasks while reducing data and computing needs.
Scaling and Parallelization
Training giant language models demand serious computing power. Distributing work across multiple machines can share the load.
Different strategies exist - splitting data, parameters, or computations. Parallel processing spreads work simultaneously. Combine distributed and parallel techniques to accelerate the training of the largest models. Simple approaches, immense impact.
Keep reading to learn more!
Strategies for Training Large Models on Multiple Machines
The LLM training model can be computationally intensive, requiring significant computational resources.
To tackle this, strategies for large training models on multiple machines can be employed.
One approach is model parallelism, where the model's parameters are distributed across multiple machines, with each machine responsible for computing a portion of the model's operations.
Another approach is data parallelism, where each machine is assigned a subset of the training data, and the gradients are computed independently on each machine before being aggregated and used to update the model's parameters.
These strategies help distribute the computational workload and accelerate the training process.
Distributed Training and Parallel Computing
Distributed model training involves training a large model on multiple machines simultaneously.
In this approach, the data is divided across the machines, and each machine processes its portion independently. Gradients and updates are then shared between the machines to synchronize the model's parameters.
Large language models can be trained much quicker using distributed training since it parallelizes the calculations over numerous computers, allowing for better scalability and faster convergence.
Parallel computing, on the other hand, involves executing multiple computations simultaneously.
This can be achieved through hardware architectures designed for parallel processing, such as graphics processing units (GPUs) or tensor processing units (TPUs).
These specialized hardware units can perform computations in parallel, allowing for faster training and inference of large language models.
Parallel computing techniques, combined with distributed training strategies, can speed up the training process and enable the training of even larger models.
Now let us see the challenges and solutions for the LLM training model.
Suggested Reading:
Challenges and Solutions
Addressing challenges of the LLM training model, such as overfitting, exploding and vanishing gradients, and efficient memory management, is essential to ensure successful training and optimal performance of large language models.
Overfitting and Regularization Techniques
When an LLM training model performs well on data but badly on fresh, untested data, this is known as overfitting.
Preventing overfitting and permitting generalization are two challenges in training big language models. Regularization strategies can assist in resolving this issue.
The model training may be regularized and overfitting reduced by using strategies like weight decay, which adds a penalty term to the loss function to discourage excessive weights, and dropout, which randomly removes a fraction of the model's units during training.
Exploding and Vanishing Gradients
Another challenge in training models is the issue of exploding and vanishing gradients.
These phenomena occur when the gradients during backpropagation become too large or too small, making it difficult for the model to learn effectively.
To mitigate this problem, gradient clipping can be employed, which involves scaling the gradients to a predefined threshold.
Additionally, activating functions like the rectified linear unit (ReLU), which helps propagate gradients more effectively, can help alleviate the problem of exploding and vanishing gradients.
Efficient Memory Management During Training
Training models require careful memory management, as the size of the model and the amount of data can quickly exceed the available memory capacity.
One approach to overcoming this challenge is to use techniques such as gradient checkpointing, where the intermediate activations and memory are stored on disk or in a slower memory medium during training, to save memory.
Additionally, mixed-precision training, which utilizes lower-precision data types for certain computations, can help reduce memory usage while maintaining acceptable training performance.
Efficient memory management is crucial for training large models, and employing techniques such as gradient checkpointing and mixed-precision training can help optimize memory utilization and enable the training of even larger language models.
Now let us see some ethical considerations for the LLM training model.
Ethical Considerations
Evaluating language models using appropriate metrics is critical to ensuring their quality and effectiveness.
Fine-tuning techniques can improve the model's performance on specific tasks while considering ethical concerns such as bias and fairness, as well as privacy and data protection, which is essential to building ethical and trustworthy language models.
Bias and Fairness in Language Models
One significant ethical concern in language models is the potential for bias and unfairness.
Language models learn from the data they are trained on, and if that data is biased, the model will reflect that bias in its predictions.
For example, suppose a language model is trained on a biased corpus against specific communities or minorities.
In that case, it may produce biased or unfair results when applied to natural language processing tasks.
Addressing bias in language models requires careful consideration of the data and the evaluation of the model's predictions to ensure fairness and avoid perpetuating harmful stereotypes or prejudices.
Privacy Implications and Data Protection
Another ethical concern in language models is the potential for privacy implications and data protection.
Language models collect and process vast amounts of data, including personal information, which may be used for unintended purposes.
Data protection and privacy requires strict data management policies, including data minimization, secure storage, and appropriate consent procedures.
Additionally, transparency and open communication regarding data collection and usage are essential to building user trust and ensuring ethical behavior in language model development and deployment.
Conclusion
We explored the fascinating process behind how powerful language models like GPT-3 are trained - from the vast data collection phase to the intricate neural network architectures and optimization techniques involved.
We learned about the iterative training process using gradient descent and backpropagation to improve model performance continuously.
We also addressed key challenges in scaling training to multiple machines and discussed critical considerations around bias, fairness, privacy, and ethics when developing language models.
We hope this guide gave you valuable insights into the complex yet impressive journey of training large language models to understand human language at scale.
Suggested Reading:
Frequently Asked Questions (FAQs)
What are large language models, and how are they trained?
Large language models are transformer-based neural networks that learn to represent language by processing vast amounts of text data. The model training are using techniques such as stochastic gradient descent, backpropagation, and adaptive learning rates.
What is parallelization, and how does it help train large language models?
Parallelization is a technique that distributes the computational workload across multiple machines, enabling faster and more efficient training of large language models. This includes model parallelism and data parallelism, each with its unique advantages.
What challenges arise when training large language models, and how are these challenges overcome?
Model training presents challenges, such as overfitting, gradient vanishing and explosion, and memory optimization. These are addressed through regularization, gradient clipping, and memory optimization.
How is the performance of large language models evaluated?
The performance of a large language model is evaluated using metrics such as perplexity, accuracy, precision, recall, and F1 score. These metrics provide valuable insights into the model's predictability and effectiveness.
What is fine-tuning, and how does it improve the performance of large language models?
Fine-tuning is the process of adapting a pre-trained model to a specific task or domain. This involves adjusting the model's architecture, adding task-specific layers, or adjusting learning rates. It can significantly improve the model's performance on specific tasks.
What ethical considerations should be taken into account when training large language models?
Ethical considerations when model training include potential bias and fairness issues, data protection, and privacy implications. Addressing these ethical concerns requires careful data management policies, transparency, and open communication regarding data usage, and responsible implementation and deployment.