
Model Training in Deep Learning: Explained in Detail
Updated at Jun 30, 2026
3 min to read

Model training serves as AI's foundation to harness machine learning's power.
It encompasses the process through which a machine learns patterns and relationships within data.
A study by Gartner found that 50% of organizations will use AI for model training by 2025.
Did you know that 94% of organizations believe improving their data-driven decision-making capabilities is the key to success? Model training is the process that transforms raw data into smart decision-making algorithms.
Model training involves a series of intricate steps where algorithms analyze vast datasets. The model adjusts its internal mechanisms as data flows in, honing its predictive accuracy and problem-solving prowess. This process refines their parameters to improve performance.
In today's data-driven world, understanding how to train models is invaluable.
So, in this guide, you will find the fundamentals of model training, data preparation techniques, selecting the perfect model, and how to set up your model training pipeline.
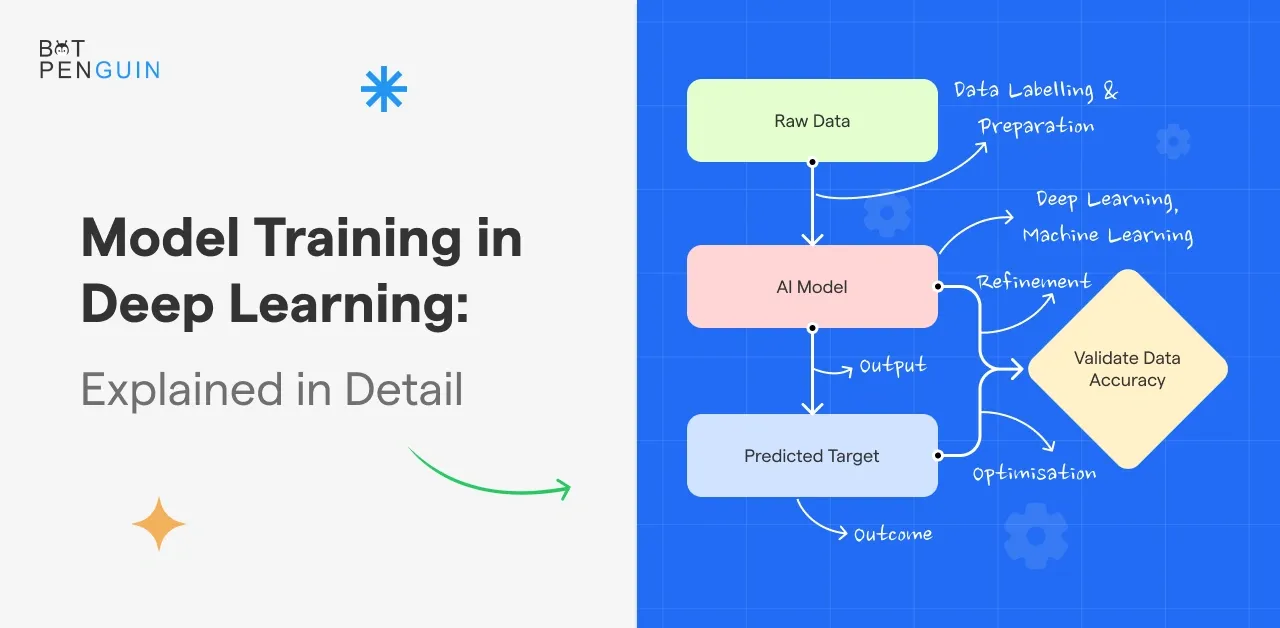
Model training teaches a machine learning model to recognize patterns in vast amounts of data. The process involves feeding vast amounts of example data to an algorithm. It allows the algorithm to learn and identify patterns it can apply when faced with new, unseen data.
Model training is crucial when building accurate and reliable machine-learning models. In this process, optimization techniques like gradient descent guide models toward optimal predictions with actual outcomes.
Model training is an invaluable asset for businesses that wish to remain competitive and harness the power of data-driven insights.
Model training holds immense importance, like:
Enhanced Performance: Model training refines algorithms, boosting their predictive accuracy and decision-making capabilities.
Adaptation to Data: Through exposure to diverse data, models adapt and generalize, accommodating new scenarios.
Complex Pattern Recognition: Training empowers models to recognize intricate patterns, unlocking insights in large datasets.
Real-World Applicability: Trained models enable practical healthcare, finance, and autonomous systems solutions.
Continuous Improvement: Iterative training cycles allow models to improve continually, staying relevant in dynamic environments.
In this section, we will explore some key concepts and techniques of model training:
Data Preparation: Collect, clean, and preprocess data for consistent input, aiding effective learning.
Feature Engineering: Select or create relevant features to extract meaningful patterns from the data.
Algorithm Selection: Choose suitable algorithms based on the problem, complexity, and interpretability.
Training and Testing: It means splitting data into training and testing sets to evaluate model performance.
Hyperparameter Tuning: Fine-tune model settings to optimize performance through iterative experimentation.
Loss Function: Define a loss function to quantify model error and guide parameter adjustments.
Optimization Techniques: Use methods like gradient descent to minimize errors during training.
Regularization: Apply techniques to prevent overfitting and enhance generalization.
There are various model training techniques, each with its characteristics and use cases. Here are some common types of model training:
Curriculum learning is a concept in machine learning that mimics how humans learn. It involves:
Sequential Complexity: Gradually introduce data from simpler to more complex examples.
Knowledge Ordering: Prioritize training examples based on informational value.
Concept Building: Master simpler concepts before tackling intricate relationships.
Reduced Overfitting: Mitigate overfitting by controlled exposure to complexity.
In supervised learning, the model gets trained using labeled data, where the input data gets paired with the corresponding desired output (labels). The model aims to learn a mapping between inputs and outputs.
Common algorithms for supervised learning include:
decision trees
random forests
support vector machines
neural networks
Unsupervised learning involves training a model on unlabeled data to discover underlying patterns, structures, or relationships in the data.
Common techniques include clustering, where data points are grouped based on similarity. Another one is dimensionality reduction, which reduces the number of features while preserving important information.
Reinforcement learning is about training models to make decisions to maximize a cumulative reward. The model learns by interacting with the environment and receiving feedback through bonuses or penalties. It's commonly used in applications like game playing and robotics.
Regarding machine learning, choosing the right training model is like choosing the perfect outfit. There are a few parameters to select the right training model.
Just like fashion trends, machine learning models come and go. However, a few tried and tested ones have stood the test of time. Some of the popular models include:
Linear Regression
Logistic Regression
Random Forests
Support Vector Machines
Neural Networks
Each model has its strengths and weaknesses, and it's essential to understand these nuances before deciding.
There are various techniques to evaluate the performance of a training model, such as:
Accuracy: It measures how well the model predicts the correct outcome.
Precision: Assessing the proportion of true positives to the total predicted positives.
Recall: Determining the proportion of true positives to the total actual positives.
F1-Score: Combining precision and recall to give an overall performance metric.
Receiver Operating Characteristic (ROC) Curve: The ROC curve visually represents the model's performance by plotting the true positive rate of the data against the false positive rate.
By evaluating these metrics, you can see how well your model performs.
Now that you know about popular models and evaluation techniques, it's time to choose the perfect model for your specific use case. Consider the following factors:
Data Size
If you have a large dataset, models like random forests or neural networks may be a good fit. Simpler models like logistic regression or decision trees could be sufficient for smaller datasets.
Interpretability
If explaining your model's decisions is essential, linear or logistic regression may be more suitable. As these models provide transparent explanations.
Complexity
Complex models like neural networks may yield higher accuracy, but they can be computationally expensive and harder to train. Consider the trade-offs based on your available resources.
Domain Expertise
If you have domain expertise or prior knowledge, leverage it to choose a model that aligns with your understanding of the problem.
By considering these factors and experimenting with different models, you can pick the one that best meets your requirements.
This section explores the steps to set up a model training pipeline.
Data preparation is the first step in setting up a data pipeline. So, let's see what to do here.
Data Collection
Gather the data you need for training your model. It could be from various sources like databases, APIs, or manual labeling.
Data Cleaning and Preprocessing
Clean the data by removing any irrelevant or noisy information. Preprocess the data by transforming it into a suitable format for training.
Data Splitting
Split your dataset into training and validation sets. It allows you to assess the performance of your model on unseen data.
Feature Engineering
Feature engineering is selecting and transforming your data to make it as useful as possible for model training. It could involve scaling numerical data, creating new features based on existing ones, etc.
Encoding Categorical Variables
If your data includes categorical variables, you'll need to encode these variables in a way that your model can understand. Depending on the nature of your data, it could involve one-hot or label encoding.
Scaling the Data
Another critical step in data preparation is scaling your data. It ensures that numerical features are on a similar scale so that no one feature dominates the others.
Now that data preparation is over, let's build the training model and the steps to train it.
Model Selection
Choose the right model for your problem. Consider factors like the complexity of the problem, the available resources, and your data size.
Model Architecture
Define the structure of your model by selecting the appropriate layers, activation functions, and optimization algorithms.
Model Training
Train your model using the training dataset. It involves feeding the data through the model and adjusting its parameters to minimize the loss function.
You need to evaluate and optimize your model's performance in this step. So, let's see that:
Model Evaluation
Assess how well your trained model performs on the validation dataset. Measure the model's performance using accuracy, precision, recall, and F1-score metrics.
Model Fine-tuning
If your model is not performing as expected, tweak the hyperparameters, adjust the model architecture, or try different optimization techniques.
Regularization
Prevent overfitting by applying regularization techniques like dropout or L1/L2 regularization.
Finally, it's time to deploy your model to make predictions on new, unseen data.
Model Deployment
Package your trained model into a format easily used in production systems.
Model Monitoring
Continuously monitor your deployed model's performance to ensure accuracy and reliability.
Model Iteration
As new data becomes available or new requirements arise, iterate on your model training pipeline to improve the model's performance.
Following these steps, you can set up a robust model training pipeline that takes your data and turns it into a powerful, predictive mode.
Feature engineering is creating new features that accurately represent your problem while minimizing noise and maximizing information gain. It's about selecting and manipulating data attributes that help predict the target variable. As data is the foundation of machine learning models, feature engineering is vital to the entire workflow.
Feature selection identifies the essential features contributing to your model's accuracy. It's about removing redundant or irrelevant attributes that might add noise to your model. Univariate feature selection, recursive feature elimination, or tree-based feature selection are common techniques used for this purpose.
Feature extraction involves the creation of new features from existing ones to maximize information gain. It's about finding patterns in your data that accurately describe your problem. Principal component analysis (PCA), latent Dirichlet allocation, or singular value decomposition (SVD) are popular techniques for dimensionality reduction and feature extraction.
Feature transformation revolves around modifying existing features to reveal new insights. It's about changing your data's scale, distribution, or shape to expose hidden relationships. Normalization, log transformations, or quantile transformations are the techniques for feature transformation.
Feature scaling is the process of standardizing the range of your features to improve model convergence. It's about balancing the ingredients to create a more harmonious and accurate result. Min-max scaling, standardization, or robust scaling are popular techniques for feature scaling.
Sometimes, creating new features requires a bit of creativity. It's about adding domain expertise or additional information to develop insightful and informative attributes that weren't present in the raw data. Text feature extraction, image feature extraction, or domain-specific transformations are good examples of creative feature creation.
Hyperparameters fine-tune your models' behavior and improve performance. But finding the best hyperparameter values can be difficult. That's where hyperparameter tuning comes in!
When it comes to hyperparameter tuning, there's no one-size-fits-all approach. Let's explore some popular methods to help you navigate the vast landscape of hyperparameters.
Manual Tuning
Sometimes, the best way to find the correct hyperparameters is to roll up your sleeves and rely on your intuition. It involves manually tweaking the hyperparameter values and evaluating the model's performance. It requires patience, expertise, and a touch of luck.
Grid Search
If you prefer a more systematic approach, grid search is your go-to method. It involves defining a grid of possible hyperparameter values. And then it searches through all combinations. While it may be computationally expensive, it ensures no stone is left unturned.
Random Search
For adventurous souls, random search offers a breath of fresh air. Instead of searching through a predefined grid, random search randomly selects hyperparameter values from a given distribution. This approach can be more efficient when only a few hyperparameters significantly impact the model's performance.
Bayesian Optimization
If you believe in leveraging past experiences to make better decisions, Bayesian optimization is an excellent choice. This method builds a probabilistic objective function model and intelligently selects the next set of hyperparameters based on previous evaluations. It's like having a personal assistant who learns your preferences over time.
Once you've tuned your hyperparameters, it's time to evaluate your model's performance. But how do you know if your tuning efforts were successful? So here the methods to know:
Holdout Method
The holdout method involves splitting your dataset into training and validation sets. You train your model on the training set with the tuned hyperparameters and evaluate its performance on the validation set. It gives you an estimate of how well your model might perform in the real world.
Cross-Validation
Cross-validation comes to the rescue for a more comprehensive assessment of your model's performance. This method involves splitting your dataset into multiple folds and iteratively training and validating your model. It provides a robust estimate of your model's performance and helps reduce the impact of sampling bias.
Model validation determines how well your machine-learning model generalizes to unseen data. It's like the final exam that tests the true capabilities of your model beyond the training phase. With proper validation, your model's performance may be reliable and lead to disastrous results. So, let's take this critical step!
Cross-validation is a popular technique to validate your models effectively. It involves dividing your dataset into multiple folds and iteratively training and testing your model on different combinations of these folds. This technique provides a robust estimate of your model's performance and helps mitigate the impact of sampling bias.
K-Fold Cross-Validation
K-Fold Cross-Validation is the classic technique that splits your dataset into K equal-sized folds. It trains and tests your model on K-1 folds on the remaining fold.
The process is repeated K times with a different fold as the test set. The results are then averaged to obtain a reliable estimate of your model's performance.
Stratified K-Fold Cross-Validation
When dealing with imbalanced datasets, Stratified K-Fold Cross-Validation comes to the rescue. It ensures that each K-fold maintains the same class distribution as the original dataset. This technique helps prevent overfitting on the majority class and provides a fair evaluation of your model's performance.
Leave-One-Out Cross-Validation
When you have a small dataset and want to squeeze every bit of information, Leave-One-Out Cross-Validation is your best friend. It leaves out just one instance as the test set and trains your model on the rest. This process gets repeated for every example in the dataset. While computationally expensive, this technique provides the most accurate estimate of your model's performance.
Model validation isn't just about testing your model; it's also about selecting the right evaluation metrics to measure its performance accurately. The choice of metrics depends on your problem domain and the specific goals of your model. Let's explore some popular evaluation metrics:
Accuracy
Accuracy evaluation metrics measure the percentage of correctly classified instances by your model. It's a widely used metric but may not be suitable for imbalanced datasets.
Precision and Recall
Precision calculates the proportion of true positives among the predicted positive instances, while recall measures the proportion of true positives among the actual positive instances. These metrics are crucial when dealing with imbalanced datasets. It is often used together as the F1 score.
ROC-AUC
When dealing with unbalanced datasets, the Receiver Operating Characteristic (ROC) and Area Under the Curve (AUC) are reliable measures. The true positive and false positive rates are plotted on ROC curves, and AUC shows how well your model has performed overall.
In this section, we'll explore the challenges, strategies, and techniques to deploy machine learning models effectively and achieve scalability in their implementation.
Deploying machine learning models to production comes with its fair share of challenges. Let's dive into some common hurdles and learn how to overcome them.
Data Drift: Embracing Change
Data drift is the distribution of the input data changes over time, impacting your model's performance. To overcome this challenge, continually monitoring and updating your model using fresh data is crucial. Embrace change, adapt, and ensure your model remains accurate and reliable despite evolving data.
Deployment Delays: From Lab to Live
Moving machine learning training models from experimentation to real-world production can be complex and time-consuming. Streamlining this transition is essential by establishing efficient deployment pipelines and automating repetitive tasks. Let's transform your models from laboratory wonders to operational powerhouses!
Feature Engineering: Engineering Brilliance
Creating compelling features is an essential aspect of model deployment. Feature engineering involves selecting, transforming, and engineering the input variables to enhance your model's performance. It requires domain knowledge, creativity, and careful consideration of the problem.
Deploying machine learning models to production is an art that requires careful planning and execution. Let's explore the crucial steps involved in this process.
Model Versioning: Keeping Track
Effective model versioning ensures that changes and improvements are appropriately documented and tracked. By using version control systems, you can maintain a history of your models, understand their progression, and quickly roll back if necessary. Let's keep track of your models and ensure seamless transitions!
Testing and Quality Assurance: Building Confidence
Thorough testing and quality assurance are vital before deploying your models to production. It helps identify potential issues, validate their performance, and ensure they meet the desired quality standards. Let's build confidence in your models by subjecting them to rigorous testing and quality assurance processes!
Monitoring and Maintenance: Keeping an Eye
Deploying models is not a one-time event; it's an ongoing endeavor. Monitoring their performance, detecting anomalies, and applying timely updates are crucial to maintain their accuracy and reliability. Let's watch your models, ensuring they remain at their optimal best for the long haul!
Scalability ensures your machine learning models can handle increasing workloads and deliver consistent performance. Let's explore some strategies to achieve scalability.
Distributed Computing
Distributed computing involves distributing the workload across multiple machines or processors for faster and more efficient processing. By leveraging frameworks like Apache Spark, you can scale your models to process and analyze vast amounts of data in parallel.
Cloud Computing
Cloud computing provides scalable computing resources on demand. By leveraging cloud platforms like AWS, Google Cloud, or Azure, you can dynamically allocate resources based on your model's needs, ensuring scalability and cost-effectiveness.
Containerization: Simplifying Deployment
Using tools like Docker, containerization simplifies deployment by encapsulating your models and their dependencies into lightweight, portable containers. These containers can be easily deployed across different environments, allowing for seamless scalability and reproducibility.
Understanding the training model process is crucial for building robust and accurate models. As the cornerstone of AI, model training teaches algorithms to learn from data patterns to make insightful predictions.
Understanding model training unravels the fusion of mathematics and algorithmic innovation. It enables users to construct systems that can navigate the complex landscape of real-world information.
Throughout this comprehensive guide, we've uncovered the key steps, from data preprocessing to model evaluation. By demystifying complex concepts, we've ensured you are well-equipped with the knowledge needed to embark on your modeling journey.
So, put on your data scientist hat and dive into the fascinating world of model training. Happy coding, my fellow data explorer! May your models always be accurate and your insights always be illuminating.
What is model training in machine learning?
Model training teaches a machine learning model to make accurate predictions by feeding relevant data and adjusting its parameters through algorithms.
How does model training work?
During training, the model uses training data to learn data patterns and relationships between inputs and outputs. The model adjusts its internal parameters through optimization techniques like gradient descent.
How do you evaluate the performance of a trained model?
Model evaluation involves using metrics like accuracy, precision, recall, and F1-score to assess how well the model performs on unseen data.
Can model training be accelerated with GPUs or TPUs?
Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs) can significantly speed up model training, especially for deep learning models.
What are some common tools and libraries for model training?
Popular tools and libraries for model training include TensorFlow, PyTorch, scikit-learn, and Keras. It provides robust frameworks and functionalities for training various machine learning models.
Subscribe to Our Newsletter
Get the latest business insights straight into your inbox.
Checkout our related blogs you will love.
Updated at Jun 30, 2026
3 min to read

Updated at Mar 3, 2024
11 min to read
Updated at Feb 17, 2024
11 min to read
Updated at Feb 11, 2024
11 min to read

Updated at Nov 8, 2023
4 min to read

Updated at Sep 3, 2023
7 min to read
Table of Contents