What is Machine Learning?
Machine learning is a branch of artificial intelligence that provides computers with the ability to learn from data without being explicitly programmed. It enables computers to improve their performance on specific tasks over time as they gain experience. Machine learning is transforming various industries, including healthcare, finance, e-commerce, and much more.
Why is Machine Learning Important?
Efficient Data Analysis

Machine Learning is instrumental in analyzing enormous volumes of data quickly and effectively. It's becoming increasingly important as the world is generating more data than ever before, and quick data analysis is necessary to make important decisions.
Enhancing Decision Making
Machine Learning algorithms can help organizations make data-driven decisions, predict trends, and optimize results. It not only improves business operations but also leads to better strategies and business models.
Personalization at Scale
Machine Learning is the engine behind personalized experiences. It enables companies to provide tailored services to a large number of customers, enhancing customer satisfaction and loyalty.
Predictive Capabilities
Machine Learning's ability to forecast future trends and behaviours is critical in many industries. For instance, it can predict stock market trends, customer behaviours, disease outbreaks, and even weather patterns.
Automation of Tasks
From self-driving cars to voice recognition systems, Machine Learning is the key to automation. By implementing Machine Learning, repetitive and time-consuming tasks can be automated to enhance efficiency and productivity.
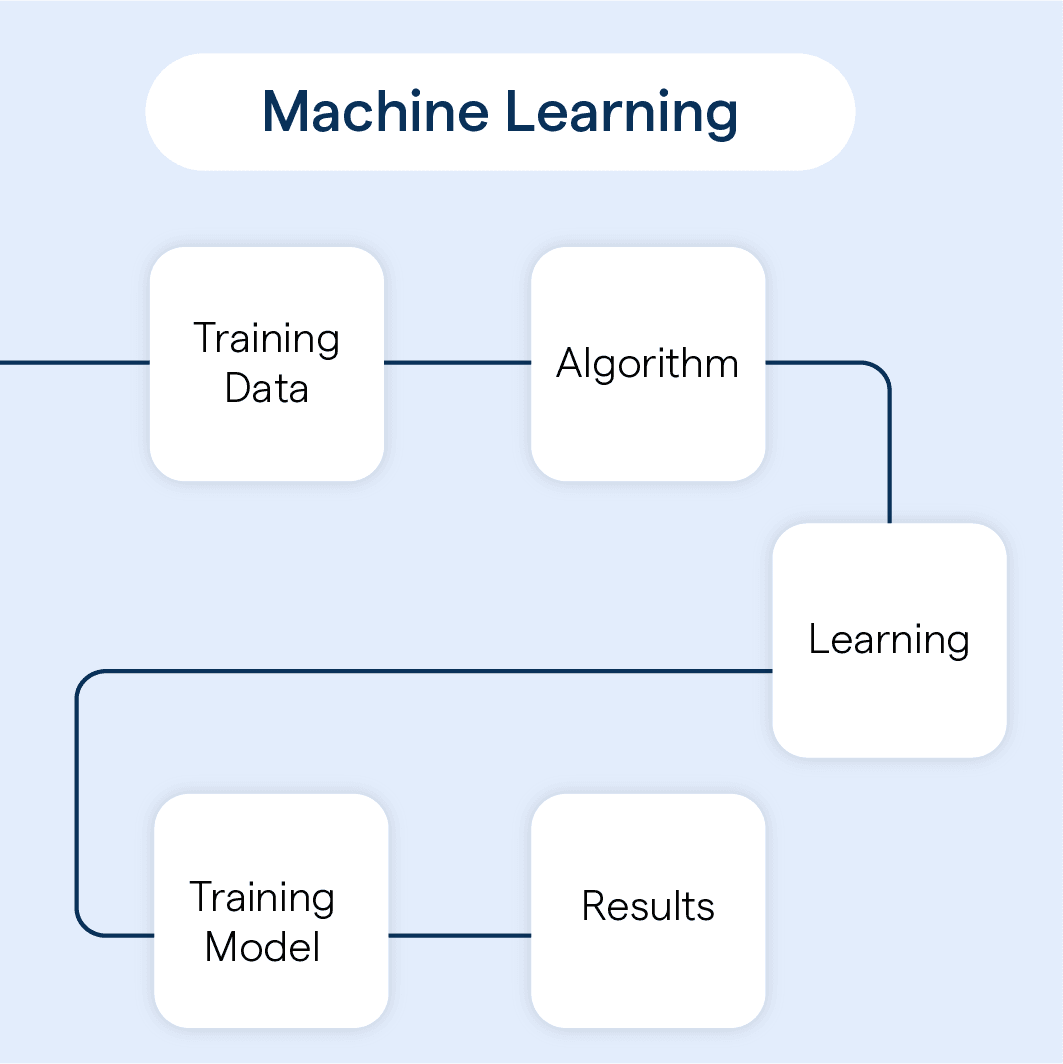
How does Machine Learning Work?
Acquiring Data
Machine learning begins with collecting data. This data is the basis on which models learn. The dataset should be large, diverse, and representative of real-world scenarios for effective learning.
Preparing and Cleaning the Data
The quality of machine learning depends largely on the quality of the data used. Irrelevant or missing data needs to be addressed and cleaned. Normalization, handling of missing values, and outlier detection are examples of data cleaning steps.
Choosing the Right Algorithm
Depending on the objective of the task (prediction, classification, anomaly detection, etc.) an appropriate machine learning algorithm is selected. Each algorithm has its strengths and weaknesses, and the choice often depends on the nature of the data and the specific use-case scenario.
Training the Model
Once the algorithm is selected, the model is trained using the cleaned and prepared dataset. The model attempts to find patterns or learn from the data, creating its own 'understanding' to make future predictions or decisions.
Evaluating and Optimizing the Model
After training, the model’s performance is evaluated using a testing set. If the results are unsatisfactory, the model parameters are optimized or tuned, and the model may be retrained. The final product is a machine learning model that can make accurate predictions or decisions on new, unseen data.
Machine Learning Algorithms
Supervised Learning: Regression and Classification
In supervised learning, an algorithm learns from labeled data. Regression predicts continuous outcomes like the population growth rate, while classification algorithms predict categorical outcomes, such as determining whether an email is spam.
Unsupervised Learning: Clustering
Unsupervised learning deals with unlabeled data and tries to identify underlying patterns. Clustering categorizes data into different groups or clusters based on similarity. It's used for exploratory data analysis, customer segmentation, and anomaly detection.
Reinforcement Learning
Here, agents learn to make decisions by interacting with an environment. Performed actions either receive rewards or penalties, and the goal of the agent is to optimize the total rewards. Applications range from game playing (like chess) to robotics.
Decision Tree Algorithm
Decision trees are easy-to-understand algorithms used for both regression and classification tasks. They create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features.
Neural Networks: Deep Learning
Neural networks are a subset of machine learning inspired by human brains, and are particularly effective for tasks involving unstructured data. Deep learning, a more sophisticated version of neural networks, works well for complex tasks like image and speech recognition.
Machine Learning Techniques
Supervised Learning
Supervised Learning is a popular Machine Learning technique where an algorithm learns from labeled training data, and makes predictions based on that acquired knowledge. It's often used for tasks such as email spam filtering, fraud detection, and predicting customer behavior.
Unsupervised Learning
In Unsupervised Learning, an algorithm identifies patterns within a dataset without any pre-existing labels. It's used for complex tasks such as clustering, anomaly detection, and understanding and reducing dimensionality in large datasets.
Semi-Supervised Learning
Semi-Supervised Learning, a hybrid method, uses a small amount of labeled data with a larger pool of unlabeled data for training. It combines the strengths of supervised and unsupervised learning, and is particularly useful when labeling data is costly or time-consuming.
Reinforcement Learning
Reinforcement Learning involves an agent learning the best actions to take in an environment to maximize a reward through trial and error. It's particularly suited to situations where there's a clear interaction between the environment and the model making the decisions, such as in game playing and robotics.
Deep Learning
Deep Learning, a subfield of machine learning, is inspired by the structure and function of the human brain and is particularly effective in dealing with large and complex datasets. Deep learning techniques excel in tasks such as image and speech recognition, and natural language processing.
Machine Learning Applications
Personalized Marketing with Machine Learning
Machine learning algorithms can analyze customer data to deliver personalized marketing campaigns. By predicting customer behavior, preferences, and purchasing patterns, businesses can target individual customers with highly relevant content and product recommendations.
Predictive Maintenance in Industries
Machine learning can predict system failures or defects in industrial equipment. Through continuous monitoring and by learning from historical data, machine learning can predict and prevent unexpected downtime, saving significant maintenance costs.
Enhancing Healthcare Diagnostics
Machine learning has transformative potential in healthcare diagnostics. From analyzing medical images to predicting disease progression, machine learning models can assist professionals in diagnosing a wide variety of conditions accurately and rapidly.
Improving Traffic Management
Machine learning can enhance traffic management systems by predicting traffic flow and detecting accidents or congestion in real-time. This results in better route recommendations, smoother traffic flow, and reduced travel time.
Fraud Detection in Financial Services
Machine learning can enhance security in financial services by identifying and preventing fraudulent transactions. By analyzing transaction patterns, machine learning techniques can quickly detect anomalies and flag potential fraud, protecting businesses and consumers alike.
Challenges and Limitations of Machine Learning
Handling Imbalanced Data
Imbalanced datasets, where the distribution of classes is uneven, can lead to biased machine learning models. This affects the performance of the model, particularly in tasks like anomaly detection or fraud prediction, where the minority class is crucial.
Feature Engineering
Identifying the right features for training a model is challenging. The model's performance largely depends on the relevance of the features used, and selecting or creating meaningful features requires expertise in both the domain and machine learning algorithms.
Scalability and Computation
Large datasets and complex algorithms require significant computational resources, posing challenges in terms of time, energy, and infrastructure. Scaling machine learning models to work efficiently with massive datasets is an ongoing challenge for developers and organizations.
Interpretability and Explainability
Many machine learning models, particularly deep learning techniques, function as "black boxes." Their inner workings are challenging to understand and communicate. Ensuring interpretability and explainability is vital for user trust, ethical considerations, and regulatory compliance.
Ethical and Privacy Concerns
Machine learning techniques can inadvertently perpetuate existing biases in the data or invade user privacy. Addressing these concerns while preserving model accuracy and usefulness is a significant challenge in the development and deployment of machine learning systems.