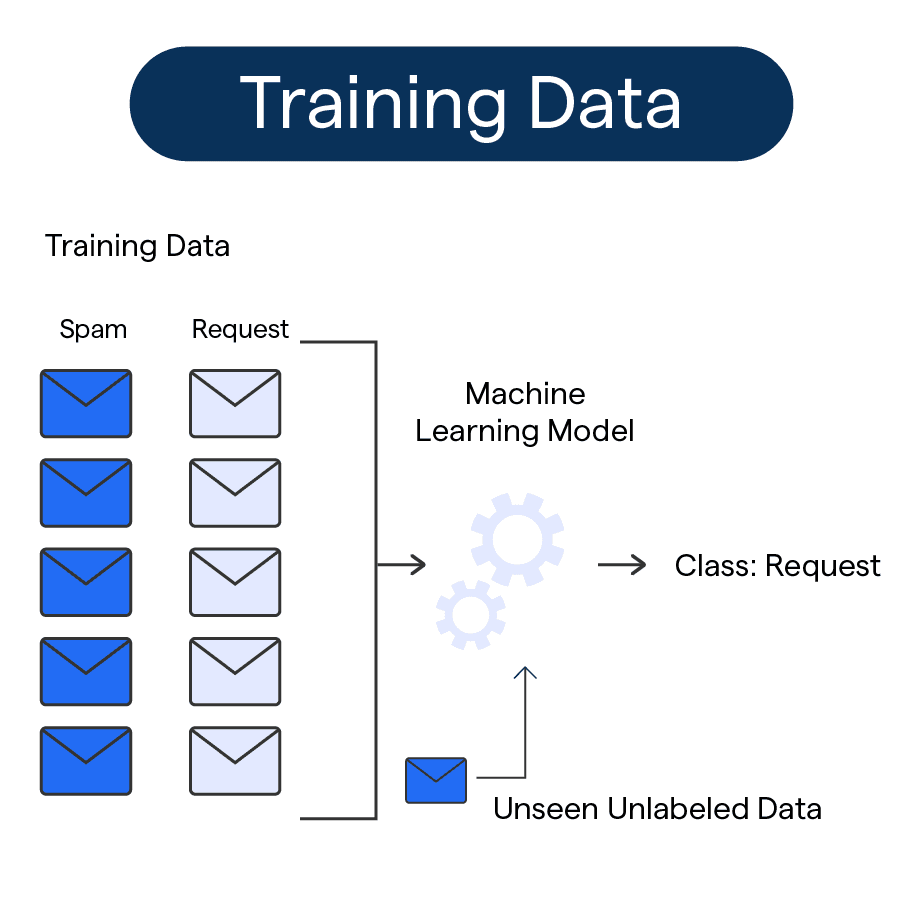
What is Training Data?
Training data is a set of examples that are used to teach a machine learning algorithm how to make predictions or decisions. There are two main types of training data: labeled and unlabeled. Labeled data includes examples that have been annotated with their correct output values, while unlabeled data does not have any annotations.
Sources of training data can come from a variety of places, including public datasets, proprietary data sources, and crowdsourcing platforms. Good training data should be representative, diverse, and balanced.
Why is Training Data Important?
Building Accurate Models
High-quality training data enables machine learning algorithms to learn patterns effectively, resulting in accurate and reliable models that can make precise predictions.
Enhancing Generalization
A diverse and representative training dataset helps models generalize better, allowing them to perform well on unseen data and reducing the risk of overfitting.
Reducing Bias
By ensuring that training data is balanced and unbiased, machine learning models can make fair predictions and avoid perpetuating existing biases in real-world applications.
Improving Efficiency
Well-prepared and high-quality training data can reduce the time and resources required to train machine learning models, leading to more efficient development processes.
Enabling Customization
Tailored training data allows businesses to develop customized machine learning models that cater to their specific needs, providing targeted and relevant insights for their unique use cases.
Who Provides Training Data?
Data providers, data collectors, data labelers, and data scientists all play a role in providing training data. Data providers can be individuals or organizations that share their data with others. Data collectors are responsible for collecting data from various sources, such as sensors, surveys, or social media. Data labelers annotate data with the correct output values, while data scientists use the training data to build and evaluate machine learning models.
How is Training Data Collected?
Gathering Data from Public Sources
Training data can be collected from public databases, repositories, or open-source platforms that provide access to large datasets for various domains and industries.
Utilizing User-Generated Content
User-generated content, such as social media posts, reviews, and comments, can be a valuable source of training data, offering insights into customer preferences, behaviors, and trends.
Conducting Surveys and Interviews
Surveys and interviews can be conducted to gather specific information and opinions from a targeted group of individuals, providing tailored training data for specific use cases.
Manual Data Annotation and Labeling
Human experts can manually annotate and label raw data, such as images, text, or audio, to create high-quality training datasets for machine learning algorithms.
Collaborating with Data Partners
Businesses can collaborate with data partners or third-party providers who specialize in collecting, annotating, and delivering training data tailored to specific industries or machine learning tasks.
How is Training Data Labeled?
Training data can be labeled using various techniques, such as manual labeling, semi-supervised labeling, or active learning. Manual labeling involves annotating data by hand, while semi-supervised labeling uses a combination of labeled and unlabeled data to train the model. Active learning involves selecting the most informative examples for labeling to improve the model's performance.
How is Training Data Used?
Building AI Models
Training data is used to teach AI models how to recognize patterns, make decisions, and perform tasks by providing examples of inputs and corresponding outputs or actions.
Fine-Tuning Model Parameters
During the training process, the AI model adjusts its internal parameters to minimize the difference between its predictions and the actual outputs in the training data, improving overall accuracy.
Evaluating Model Performance
Training data is split into subsets, with one subset used for validation to assess the model's performance during training and help prevent overfitting.
Identifying Areas for Improvement
By analyzing the model's performance on the training data, developers can identify areas where the model struggles and make adjustments to improve its accuracy and generalization capabilities.
Guiding Feature Selection
Training data helps developers determine the most relevant features to include in the AI model, ensuring that the model focuses on the most important aspects of the input data for accurate predictions.
How to Evaluate Training Data?
Assessing Data Quality
Evaluating the quality of training data involves checking for inconsistencies, missing values, and potential biases, ensuring that the data is clean and reliable.
Ensuring Data Diversity
A diverse training dataset should include a wide range of examples and scenarios, enabling the machine learning model to generalize well to new, unseen data.
Confirming Data Representativeness
Training data should be representative of the real-world situations the model will encounter, ensuring that it can effectively handle various inputs and make accurate predictions.
Evaluating Data Labeling Accuracy
Assess the accuracy of data annotations and labels, as these directly impact the model's learning process. Inaccurate labels can lead to poor model performance and incorrect predictions.
Splitting Data for Validation
Divide the dataset into training, validation, and test sets. This allows for proper evaluation of the model's performance during training and helps prevent overfitting or underfitting.
Best Practices for Training Data
Enhance Data Quality
Ensure your training data is accurate, consistent, and free from errors. Clean and preprocess the data to remove any noise, inconsistencies, or missing values that could negatively impact model performance.
Increase Data Diversity
Collect a diverse set of training data that represents various scenarios, edge cases, and user inputs. This helps the AI system generalize better and adapt to different situations within its domain.
Balance Class Distribution
Address class imbalance by ensuring an equal or near-equal distribution of samples across different classes. This prevents the model from being biased towards the majority class and improves overall performance.
Augment Data
Use data augmentation techniques, such as image rotation, flipping, or text paraphrasing, to create additional training samples. This increases the size of your dataset and helps the model learn more robust features.
Regularly Update Training Data
Continuously update and expand your training data with new samples and user inputs. This ensures your AI system stays up-to-date with evolving trends and maintains optimal performance over time.
Tl;DR
Training data is a critical component of machine learning, and it is essential to have high-quality, representative, and diverse training data to build accurate and reliable models. As the field of machine learning continues to evolve, new techniques and approaches for collecting, labeling, and evaluating training data will emerge. By understanding the importance of training data, we can ensure that machine learning models are trustworthy and beneficial for society.
Frequently Asked Questions

What is training data?
Training data is a set of labeled examples used to train machine learning algorithms, helping them learn patterns and make predictions based on input features.
Why is training data important?
High-quality training data is essential for developing accurate and reliable machine learning models, as it directly impacts the model's ability to generalize and make accurate predictions.
How is training data collected?
Training data can be collected from various sources, such as user-generated content, public databases, or through manual data annotation and labeling by human experts.
What is data preprocessing?
Data preprocessing is the process of cleaning, transforming, and organizing raw training data to make it suitable for machine learning algorithms, improving model performance and accuracy.
How can I ensure the quality of training data?
To ensure training data quality, use diverse and representative samples, validate and clean the data, employ proper data annotation techniques, and continuously evaluate model performance.