What is a Similarity Measure?
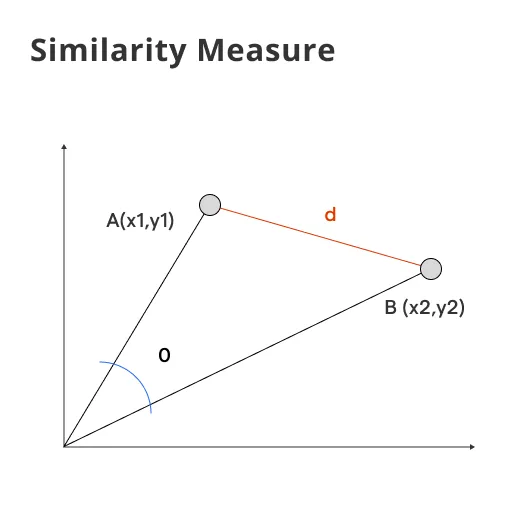
The Similarity Measure, also known as a similarity function or similarity coefficient, quantifies the degree of similarity between two entities.
Definitions in Various Fields
In different fields, the similarity measure takes on different definitions: in biology, it might be genetic similarity while in text analysis, it could be the overlap of words in two documents.
Mathematical Representation
Mathematically, the similarity measure is represented as a function that computes a numerical value indicating the relative likeness of two data objects in a model.
Role in Machine Learning and Data Mining
In machine learning and data mining, similarity measures help algorithms learn from data by comparing features, enabling efficient data classification, clustering, and retrieval.
Key Attributes for a Good Similarity Measure
A good similarity measure should be flexible, effective, efficient, and scalable. It should also be able to handle the complexities of real-world data.
Who Uses Similarity Measures?
Anyone who deals with data in various fields makes use of Similarity Measures.
Use in Data Science
In data science, professionals often use similarity measures to determine patterns and identify clusters within complex data sets.
Role in Machine Learning
Machine learning practitioners use similarity measures to teach algorithms how to learn from data by identifying patterns and relationships.
Application in Bioinformatics
In bioinformatics, specialists use similarity measures to draw a comparison between biological sequences such as DNA and proteins.
Significance in Information Retrieval
In the field of information retrieval, similarity measures are crucial in finding, sorting, and presenting relevant data to users.
Use in Social Sciences Research
In social sciences research, similarity measures can be used in various ways, including comparing responses from surveys or questionnaires.
When are Similarity Measures Used?
Similarity Measures are used when there’s a need to compare, cluster, or classify entities in a dataset.
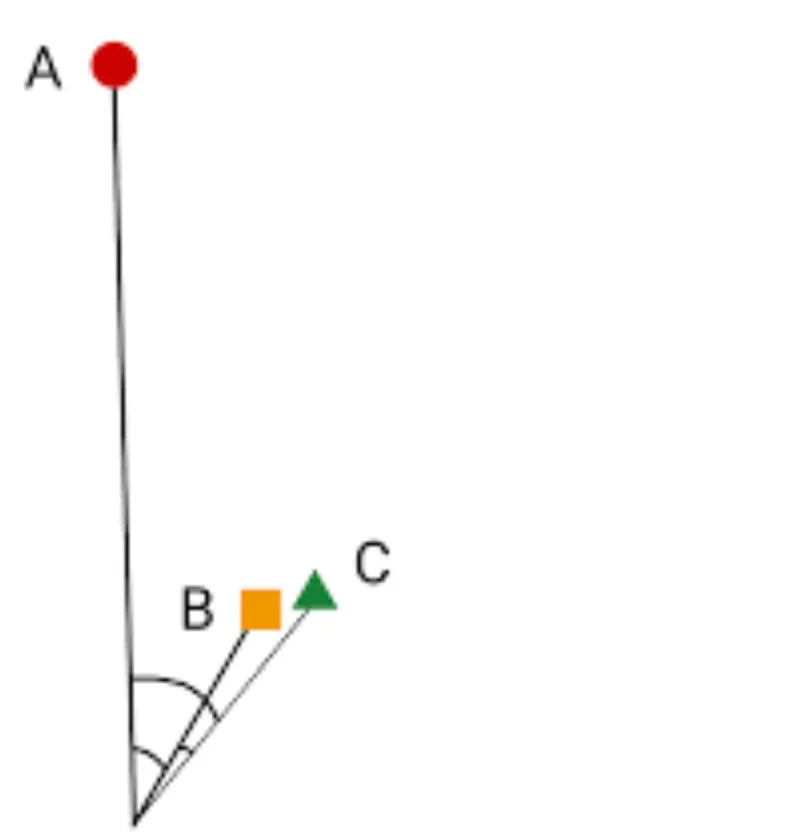
During Data Preprocessing
They are used during data preprocessing when raw data is being transformed into a form that algorithms can understand.
In Clustering and Classification Tasks
In machine learning, similarity measures are particularly important for clustering and classification tasks where the likeness of various entities forms the basis of groupings.
During Data Analysis Process
Similarity measures come in handy during exploratory data analysis, making it easier to discern patterns and insights.
In Recommender Systems
In designing and building recommender systems, similarity measures are used to analyze consumer behavior, preferences, and attributes to present personalized recommendations.
For Information Retrieval Tasks
They play a significant role in information retrieval tasks where relevant documents need to be extracted based on a certain query.
Where are Similarity Measures Used?
Similarity Measures find their application in a wide range of fields where data is a critical element.
Machine Learning
In machine learning, they are used as foundational elements for many tasks, including classification, clustering, and anomaly detection.
Information Retrieval
In information retrieval, similarity measures enable powerful search engines to return search results that closely match a user's query.
Recommender Systems
In recommender systems, such as those used by e-commerce websites or streaming services, similarity measures help suggest items based on a user’s past behavior or preferences.
Bioinformatics
In bioinformatics, similarity measures are used for comparing genomic sequences, determining the evolutionary relationships between species, and identifying disease markers.
Natural Language Processing
In natural language processing, similarity measures allow algorithms to detect similarities in text data, enhancing tasks like document clustering, sentiment analysis, and topic modeling.
Why are Similarity Measures Important?
The importance of Similarity Measures lies in their extensive utility in understanding, processing, and extracting insights from data.
Understanding Data Relationships
By evaluating likeness between data entities, similarity measures enable us to comprehend relationships and patterns in data, which is crucial for data analysis.
Enhancing Machine Learning Tasks
Better similarity measures often translate to improved performance in machine learning tasks, making them pivotal in optimizing algorithms.
Improving Information Retrieval
They play a significant role in personalizing and improving the user experience in information retrieval systems by fetching the most relevant information.
Amplifying Predictive Modeling
In predictive modeling, similarity measures help to construct models that can identify trends, understand behaviors, and predict future outcomes.
Facilitating Human-Like Cognition in AI
Similarity measures help give AI systems an element of 'human-like' cognition, allowing them to draw correlations and make associations akin to a human brain.
How Are Similarity Measures Calculated?
The calculation of similarity measures depends on the types of features in the data and the domain in which they are applied.
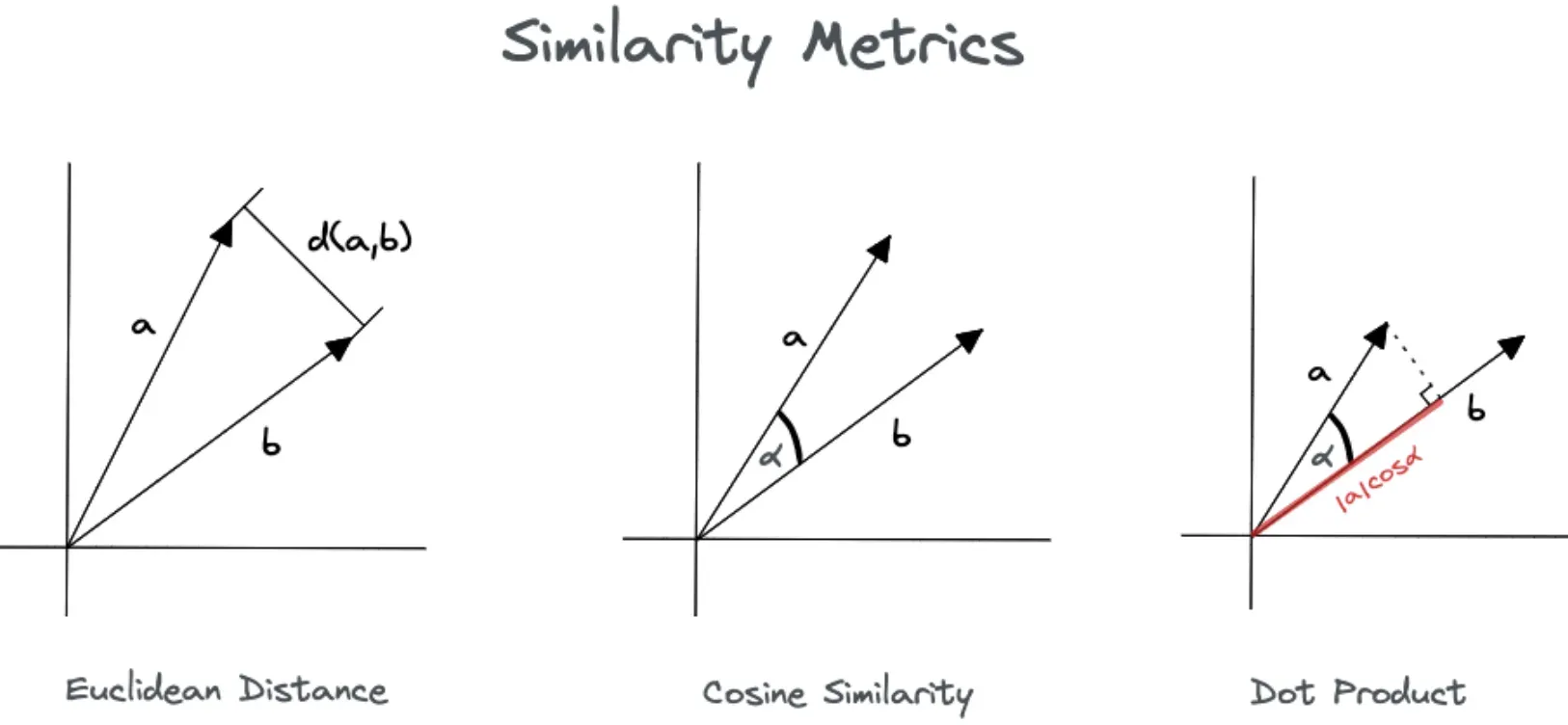
Euclidean Distance
The simplest method is Euclidean Distance, which computes the straight line distance between two points in a space.
Cosine Similarity
Cosine similarity measures the cosine of the angle between two vectors, making it most suitable for high-dimensional positive spaces often used in text analysis.
Jaccard Index
The Jaccard Index calculates the size of the intersection divided by the size of the union of two sets, frequently used with Boolean or binary data.
Hamming Distance
Hamming Distance determines the positions at which two strings of equal length differ, commonly used in genetics and information theory.
Pearson Correlation
Pearson Correlation measures the linear relationship between two datasets, widely used in statistics.
Best Practices for Using Similarity Measures
As powerful as Similarity Measures can be, implementing them correctly is critical to ensuring accurate insights and outcomes.
Selection of the Right Measure
Choosing the correct similarity measure is pivotal for the task at hand. Understand your data and your task, then choose a similarity measure suitable for them.
Data Preprocessing
Proper preprocessing of data, including normalization, dealing with missing values, and adjustment for outliers, is vitally important before applying any similarity measure.
Testing and Validation
Comprehensively validating and testing the chosen measure's performance against actual outcomes is a good practice to ensure reliable results.
Ongoing Maintenance and Refinement
Analyzing data is not a one-time task. As new data enters, adjusting and refining similarity measures is necessary to ensure relevance and accuracy over time.
Inclusion of Domain Knowledge
Including domain knowledge when formulating measures can help increase effectiveness, as it brings valuable context that a simple mathematical formula can't provide.
Challenges in the Use of Similarity Measures
While Similarity Measures are of great use, they aren’t without challenges, which makes their effective utilization a complex task.
Demand for High Computational Resources
The need for high computational resources can be a significant challenge, especially with large datasets and real-time applications.
Difficulty in Interpreting Results
Sometimes, measures can be difficult to interpret, leading to challenges in understanding the results or communicating them to others.
Sensitivity to Parameter Choices
Several measures come with parameters that require care in their choice and adjustment, with the risk of significant changes in results based on these parameters.
Subjectivity in Definition
The concept of similarity can be somewhat subjective, leading to challenges in defining exactly what constitutes 'similar' entities in certain contexts.
Computation of Dissimilarity
While calculating similarity measures seems straightforward, computing dissimilarity can be tricky, especially in high-dimensional spaces.
Examples of Similarity Measures in Action
Understanding Similarity Measures theoretically is one thing, but seeing them in action often lends a more comprehensive understanding.
Recommender Systems
Netflix recommends movies based on your watching habits. A similarity measure like Cosine Similarity or Pearson Correlation is calculated between you and all other users to suggest the most similar users, and hence their preferred movies.
Document Clustering
Google News uses similarity measures to cluster news articles into coherent groups. By treating each article as a high-dimensional vector, it employs measures like Cosine Similarity to group similar ones together.
Face Recognition
In facial recognition systems, the distances or similarities between facial feature vectors are calculated using various measures like Euclidean distance or Mahalanobis distance.
Detecting Plagiarism
Similarity Measures are used in plagiarism detection software. Texts are broken into shingles or n-grams, and a measure like Jaccard similarity is used to find overlaps.
Predicting Disease
In bioinformatics, similarity measures often assist in identifying genes associated with diseases. For example, sequence alignment algorithms use measures like Levenshtein distance to recognize disease-linked genetic markers.
Frequently Asked Questions (FAQs)
What is the Role of Similarity Measures in Machine Learning?
Similarity measures are key in many machine learning algorithms, such as clustering or nearest neighbor search, to quantify the similarity between instances.
How Does Cosine Similarity Work?
Cosine similarity measures the cosine of the angle between two vectors, effectively comparing their direction, making it useful for high-dimensional data.
What is Jaccard Similarity?
Jaccard similarity quantifies similarities between finite sample sets and is used in areas such as information retrieval and text mining.
How is Euclidean Distance Used as a Similarity Measure?
Euclidean Distance, a common similarity measure, quantifies the straight-line distance between two points, ideal for points in a Euclidean space.
Are There Different Similarity Measures for Different Types of Data?
Yes, data type dictates the choice of similarity measure. For example, text data often uses cosine or Jaccard, while numeric data may use Euclidean or Manhattan distance.

