What is Semantic Relatedness?
Semantic relatedness is the degree to which two concepts or entities share meaningful connections or associations. It encompasses semantic similarity (words with identical or similar meanings) and encompasses more general associations or connections.
For instance, "car" and "road" are not synonyms, but they are semantically related because cars drive on roads.
The Significance of Semantic Relatedness
Semantic relatedness plays a vital role in several natural language processing (NLP) and artificial intelligence (AI) applications, such as:
- Text mining and analytics: Understanding semantic relatedness can help derive meaningful insights from unstructured text data in fields like social media analytics, sentiment analysis, and market research.
- Information retrieval (IR): Search engines use semantic relatedness to improve search results and recognize the user's search intent.
- Recommendation systems: Recognizing semantic closeness between items enables a more accurate recommendation of relevant content and products for users.
- Text summarization: Identifying semantically related words and phrases is crucial for creating coherent and concise summaries of longer texts.
Techniques for Measuring Semantic Relatedness
There are numerous ways to calculate semantic relatedness. We'll discuss the most popular techniques and their relevance.
Knowledge-Based Techniques
Knowledge-based techniques involve leveraging structured knowledge sources, such as ontologies, thesauri, or other organized lexical databases, to quantify the relatedness between concepts.
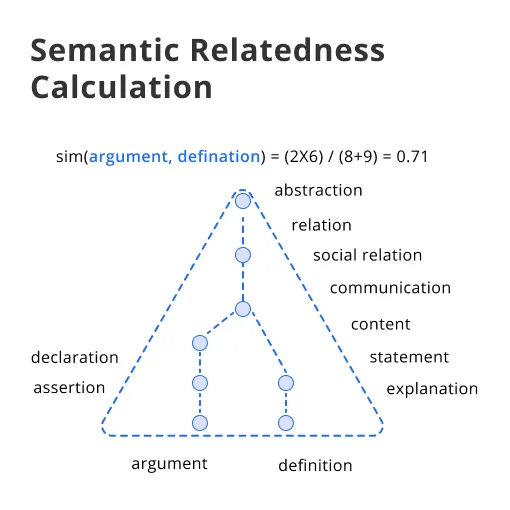
- Path Length or Link-based Techniques: These techniques calculate the distance between the two concepts inside the knowledge source. For instance, WordNet uses path length based on hypernymy (is-a relationships) to measure semantic relatedness.
- Information Content-based Techniques: These strategies compute the relatedness based on the information content (IC) of the concepts. It typically involves leveraging concepts' common subsumers (shared ancestors) to gauge the IC. The information content is determined by the frequency or specificity of a concept.
- Feature-based Techniques: These methods assess the relatedness by comparing the properties (features) of the concepts, mainly derived from lexical databases. Jaccard Similarity Coefficient, for example, measures the similarity between two sets based on overlapping features.
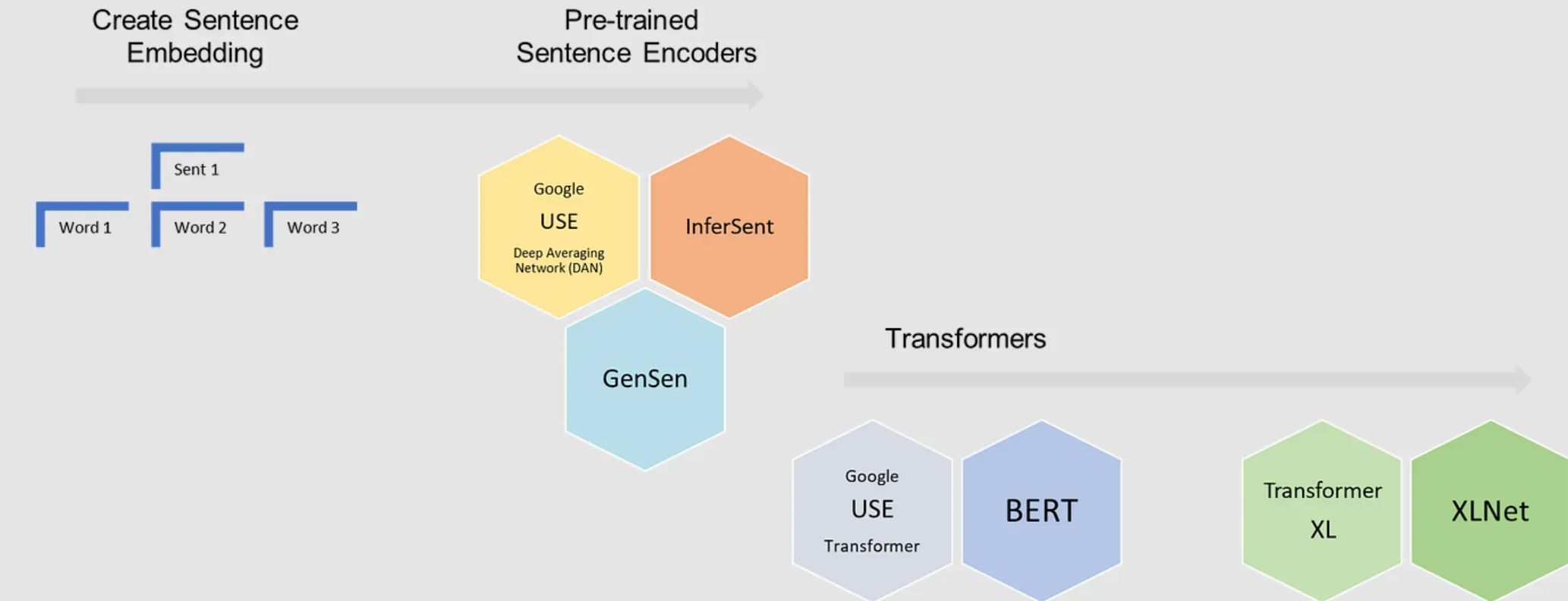
Distributional Semantics Techniques
Distributional semantics techniques rely on the observation that semantically related words tend to occur in similar contexts. These techniques usually leverage large text corpora to analyze the distributional properties of words.
- Vector Space Models (VSM): VSMs represent words as multi-dimensional vectors in a high-dimensional space, with each dimension corresponding to a contextual feature (e.g., co-occurring words or documents). The cosine similarity or Euclidean distance between vectors can serve as a measure of semantic relatedness.
- Latent Semantic Analysis (LSA): LSA is a popular VSM that uses singular value decomposition (SVD) to reduce the dimensionality of the vector space, capturing latent relationships between words and contexts.
- Word Embeddings: Word embeddings, such as Word2Vec, GloVe, or FastText, are powerful techniques that learn dense, lower-dimensional vector representations for words from large text corpora. These models capture intricate semantic relationships and can provide high-quality semantic relatedness calculations.
Challenges in Semantic Relatedness Calculation
Calculating semantic relatedness can be fraught with challenges. Let's take a closer look at some of the most pressing problems and how they can be addressed.
Polysemy and Ambiguity
Words with multiple meanings can complicate semantic relatedness calculations. For example, "bat" refers to both a flying mammal and sports equipment. To tackle this issue, some techniques involve sense disambiguation methods that leverage context and external knowledge sources to pinpoint the intended meaning.
Homonymy and Synonymy
Homonyms (words with the same spelling but different meanings) and synonyms (words with different spellings but the same meaning) pose challenges for semantic relatedness calculation, especially for distributional approaches. Techniques like Word Sense Induction or methods leveraging knowledge-based sources can alleviate these challenges by considering word senses and exploiting relational information.
Evaluation Metrics for Semantic Relatedness
Measuring the effectiveness of semantic relatedness calculations is essential for choosing the right technique for your specific application. We'll discuss various evaluation metrics and their utility.
Human Judgment Correlation
One popular method for evaluating semantic relatedness computation involves comparing system-generated scores with human-generated relatedness rankings found in benchmark datasets, such as WordSim353, SimLex-999, or MEN. Metrics like Pearson correlation coefficient, Spearman rank correlation coefficient, or Mean Squared Error (MSE) can assess the agreement between human and system judgments.
Intrinsic and Extrinsic Evaluation
Intrinsic evaluation tests semantic relatedness computation in isolation, while extrinsic evaluation embeds it into a larger task (e.g., information retrieval). Comparing the performance of different techniques in their intended application (extrinsic evaluation) is vital for making informed choices, as metrics from intrinsic evaluation do not always indicate actual utility.
Approaches to Enhance Semantic Relatedness Computation
Continual advancements in AI and NLP provide new opportunities to improve semantic relatedness calculation. Let's explore some cutting-edge techniques.
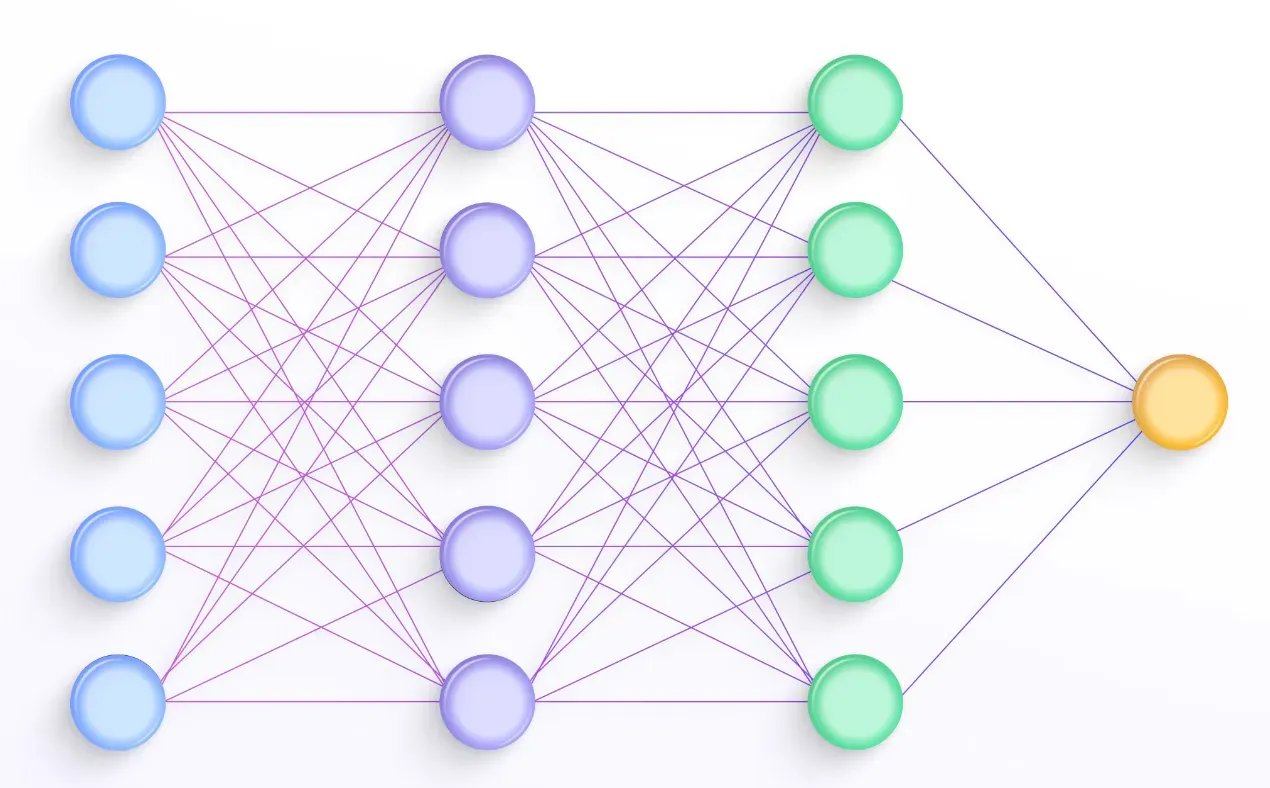
Leveraging Neural Networks
Deep learning models, such as recurrent neural networks (RNNs) and Transformer-based models (e.g., BERT, GPT-3), can provide high-quality embeddings and representations that capture semantic relatedness effectively. These models have demonstrated impressive performance in various NLP tasks.
Multimodal Approaches
Recent advancements in multimodal AI include models that combine information from different data sources, such as text and images, to obtain comprehensive semantic representations. Techniques like Multimodal Word Embeddings and Vision-Language Models (e.g., CLIP) can significantly improve semantic relatedness computations in domains that involve multiple data types.
Applications of Semantic Relatedness Calculation
The potential applications of semantic relatedness calculation are broad. We'll shed light on a few prominent sectors where it proves highly valuable.
Information Retrieval and Search Engines
Search engines rely on semantic relatedness to maximize their understanding of user queries and deliver relevant search results. By leveraging advanced techniques to quantify relatedness, search engines can cater to individual user intent more effectively.
Text Summarization and Keyphrase Extraction
Sentence extraction-based summarization techniques involve selecting the most relevant sentences to form the summary. Semantic relatedness measures can prioritize sentences that share semantic closeness with the main themes or topics of the document. Similarly, keyphrase extraction techniques can leverage semantic relatedness to compile and prioritize pertinent terms that best represent the document's content.
This extensive glossary on semantic relatedness calculation should serve as your one-stop guide to understanding everything related to this critical concept in NLP and AI. As you explore the world of semantic relatedness, use this glossary to help steer you in the right direction.
Best Practices For Semantic Relatedness Calculation
Here are the seven best practices that can help you in enhancing semantic relatedness computations.
Leverage High-Quality Datasets
The accuracy of semantic relatedness calculation depends greatly on the data it was trained on. Utilizing large-scale, high-quality datasets can enhance the detection of semantic relationships between concepts. For example, datasets such as WordNet or Wikipedia can be great resources for training.
Use Context-Aware Word Embeddings
A common practice is to leverage word embeddings like Word2Vec, GloVe, or BERT. They consider the context of a word in a sentence, which is pivotal for understanding semantic relatedness. For instance, "apple" in the context of "computers" and "fruit" would have different embeddings, enabling better relatedness computations.
Try Different Similarity Metrics
Depending on the use case, experiment with different similarity metrics like cosine similarity, Jaccard index, Euclidean distance, or others. It helps in finding the most optimal metric for capturing the semantic relatedness in your specific case.
Implement Dimensionality Reduction
Dimensionality reduction techniques such as PCA (Principal Component Analysis) can help cope with the high dimensionality of semantic vectors, making the computation of relatedness more manageable and efficient.
Employ Deep Learning Techniques
Deep learning methods like Convolutional Neural Networks (CNNs) or Recurrent Neural Networks (RNNs) can drastically improve semantic relatedness calculations. For instance, they can model subtle complexities in language that increase the accuracy of semantic relatedness.
Account for Synonyms and Antonyms
Ensure your system can distinguish between synonyms (words with similar meanings) and antonyms (words with opposite meanings). Although antonyms may appear contextually similar, reversing their polarity is crucial for accurate semantic relatedness calculation.
Regularly Update Your Models
Language evolves over time and so does its semantic associations. Make sure to update your models and embeddings regularly with fresh data to keep up with the changes and improve the accuracy of semantic relatedness calculations.
Frequently Asked Questions (FAQs)
Are there common applications for Semantic Relatedness Calculation?
Semantic relatedness calculation is used across various domains, including information retrieval, natural language processing, and data mining, as it helps quantify the relationship between different concepts or entities.
Which methods are popular for Semantic Relatedness Calculation?
Semantic relatedness is often calculated using techniques such as word embeddings, cosine similarity, and ontology-based methods, which help in understanding the relationship between two concepts through their semantic features.
How do Semantic Similarity and Semantic Relatedness differ?
Semantic similarity specifically refers to concepts sharing common attributes or being synonymous, while semantic relatedness encompasses a broader range of relationships like antonymy, is-a relations, and frequently co-occurring entities.
What role does Semantic Relatedness Calculation play in SEO?
By comprehending the context of website content, semantic relatedness aids search engines in identifying and ranking relevant content for a given query, which leads to better search engine performance and optimization.
Can you provide an example demonstrating Semantic Relatedness Calculation?
Consider the phrase "I walk with my cat on the beach." Semantic relatedness calculation can establish a connection between "walk" and "beach" because of their frequent co-occurrence, indicating walking activities often happening at the beach.