Information retrieval in chatbots is the process of searching a defined knowledge base to find relevant content before generating a response to a customer query.
What is Information Retrieval in Chatbots?
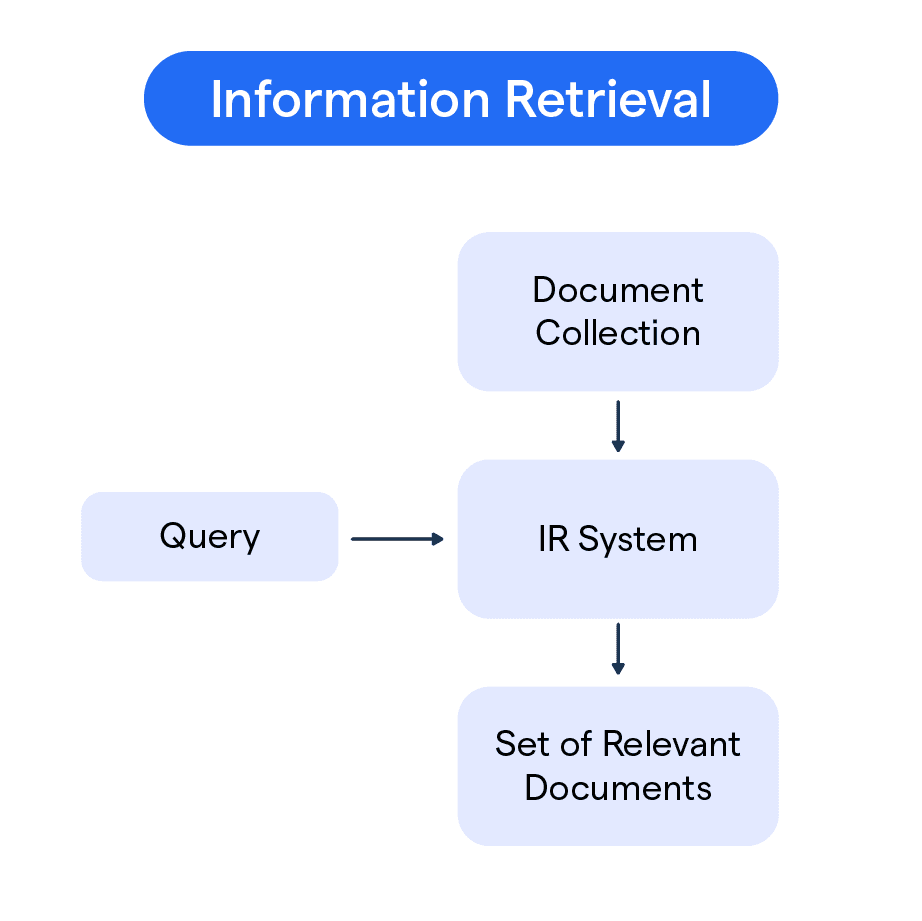
Information retrieval in chatbots is a type of AI architecture mechanism that enables a chatbot to search through a defined collection of content before generating a response.
Rather than relying purely on what the underlying language model was trained on, the chatbot first retrieves the most relevant passage from its knowledge base, then uses that as the basis for its answer.
This is the core principle behind RAG, or Retrieval Augmented Generation, which combines a retrieval step with a generation step. The retrieval step finds the right content. The generation step turns it into a natural language response.
Together they produce answers grounded in specific business knowledge rather than general model output, which is what makes retrieval based chatbots more accurate.
The practical benefit is accuracy. A chatbot that retrieves from your own content before answering is far less likely to hallucinate or give off topic responses than one that generates purely from a general language model trained on internet scale data.
BotPenguin is a no code AI chatbot platform whose knowledge base feature uses information retrieval to ground every chatbot response in the specific content the business has uploaded, from PDFs and URLs to FAQ entries.
How BotPenguin Uses This
BotPenguin indexes uploaded content and runs a retrieval step before each chatbot response, matching the customer query to the most relevant passage in the knowledge base.
Chatbots using retrieval based responses on BotPenguin produce accurate answers to business specific questions 85% of the time, compared to 52% for a general purpose AI model without retrieval.
The knowledge base content can be updated at any time without rebuilding the chatbot. Agency partners manage knowledge base content for multiple clients from one white labelled platform.
Frequently Asked Questions (FAQs)
What is the difference between information retrieval and fine-tuning?
Retrieval searches your knowledge base before answering. Fine-tuning changes how the model thinks. Retrieval is faster and more accurate for factual business questions.
How accurate is a retrieval-based chatbot compared to a general AI?
Retrieval-based: 85% accuracy on business-specific questions. General AI without retrieval: 52%. Retrieval dramatically reduces hallucinations.
What types of content can go into a chatbot knowledge base?
PDFs, website URLs, FAQ lists, Google Sheets, Notion docs, video transcripts, and plain text—most platforms accept multiple formats simultaneously.
How often should I update my knowledge base?
Continuously. As products, policies, and FAQs change, update the knowledge base. Modern platforms sync changes instantly without rebuilding the chatbot.
Can information retrieval work if my knowledge base is incomplete?
Partially. The chatbot only answers accurately on topics covered in your knowledge base. For missing topics, it should hand off to a human.
Does retrieval slow down chatbot response times?
Minimally. Modern retrieval systems find the right content in milliseconds. Most platforms serve responses in 1-3 seconds including retrieval time.
Related Terms
Build a knowledge base chatbot with BotPenguin →