
What is Language Detection?
Language detection is the process of identifying the natural language in which a text or content is written. In NLP, it is considered a special case of text categorization.
By categorizing the language, developers can apply language-specific preprocessing techniques to filter out non-target languages and focus on the target language for further analysis.
Why is Language Detection Important?
Language detection has several important applications in NLP. One such application is working with multilingual datasets, where determining the language beforehand can save time and resources.
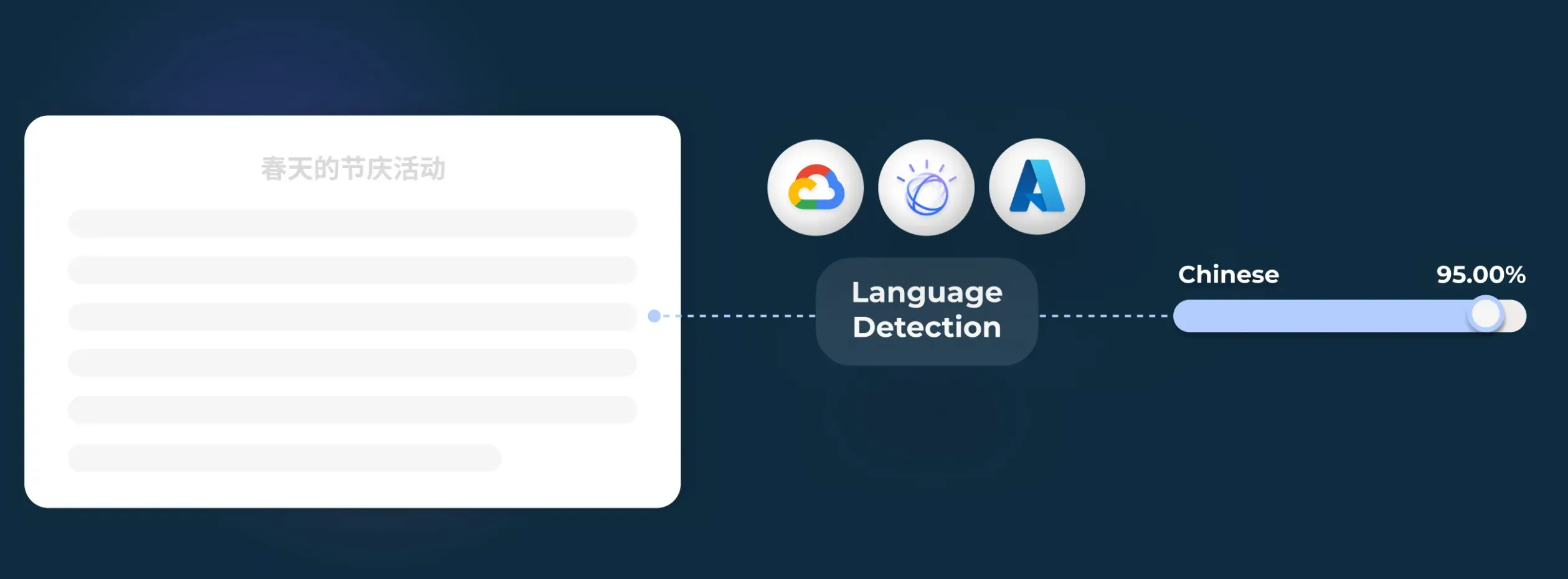
For instance, many NLP algorithms are built to work with specific languages, and by identifying the language of the dataset, developers can select the appropriate algorithms for further processing.
Another important application of language detection is in web search. When a web crawler processes pages in different languages, language detection helps ensure that search results are relevant to the user's language preference. This functionality is particularly important for websites with multilingual content.
Spam filtering services also benefit from language detection as they need to identify the language of emails, online comments, and other user inputs before applying spam filtering algorithms.
By determining the language, they can adequately eliminate content suspected of generating spam from online platforms.
Language Detection in SEO and Content Optimization
Language detection plays a crucial role in optimizing content for different languages and catering to international audiences.
By detecting the language of a user's search query or content, search engines can deliver more relevant results and improve the user experience.
Language detection also helps websites with multilingual content align their SEO strategies and improve search engine rankings.
Benefits of Language Detection
Language detection offers several benefits in various domains:
- Multilingual Applications: Language detection improves user experience in applications that support multiple languages, ensuring that content and functionality are tailored to the user's language preference.
- Time-saving: By detecting the language of a dataset or input text, language-specific algorithms can be applied directly, saving time and resources in the overall processing pipeline.
- Content Moderation and Spam Filtering: Language detection helps identify the language in which content is written, allowing for effective moderation, spam filtering, and targeted content analysis.
How Does Language Detection Work?
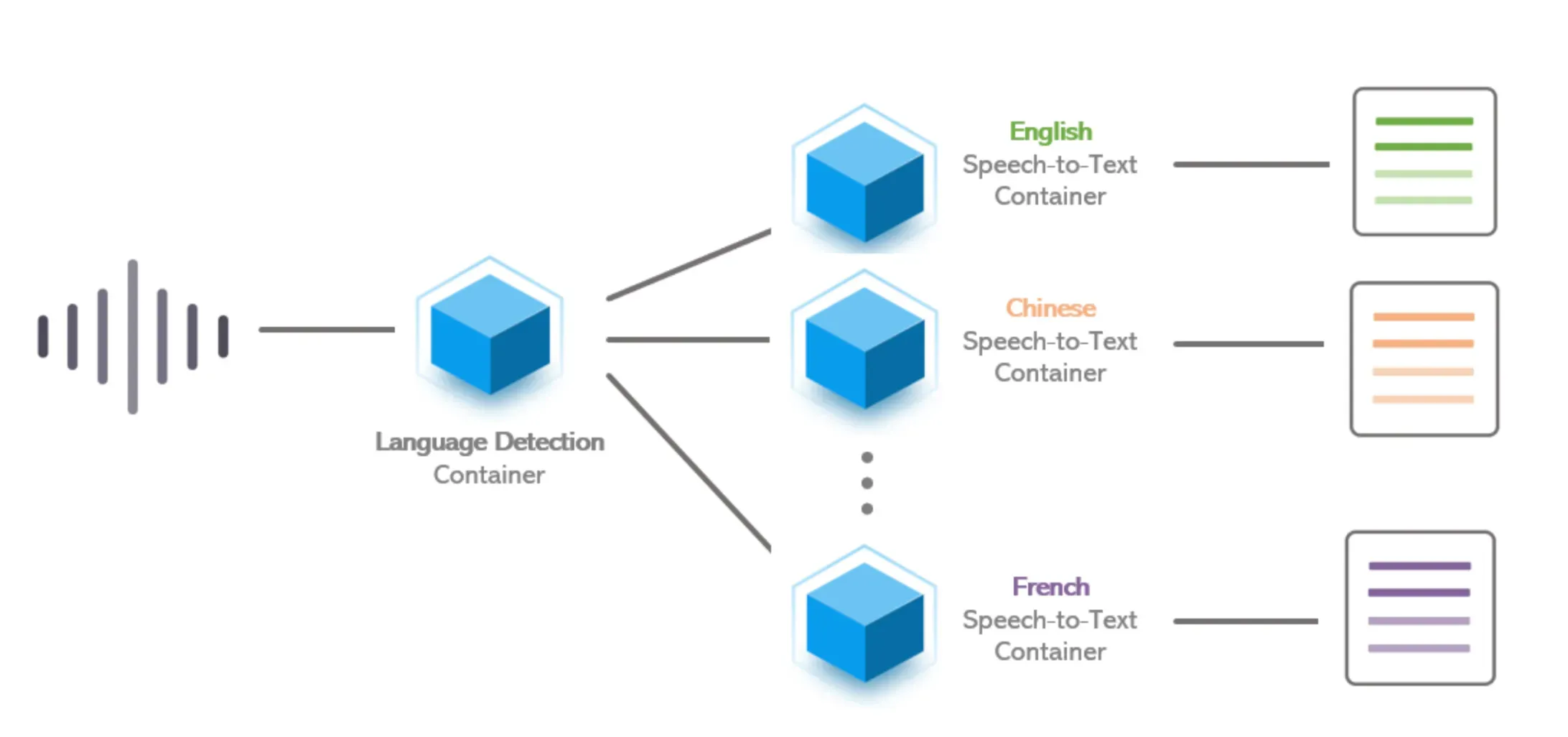
Language detection works by comparing the given text with language-specific training corpora using statistical algorithms. Here is a more detailed explanation of how language detection works:
Training Corpus
Language detection algorithms require a training corpus, which is a collection of texts in various languages.
The training corpus is used to create language models that represent the unique characteristics of each language.
Text Preprocessing
Before language detection can take place, the input text is typically preprocessed to remove any unwanted characters, punctuation, or special symbols.
This ensures that the language detection algorithm focuses on the actual text content.
Feature Extraction
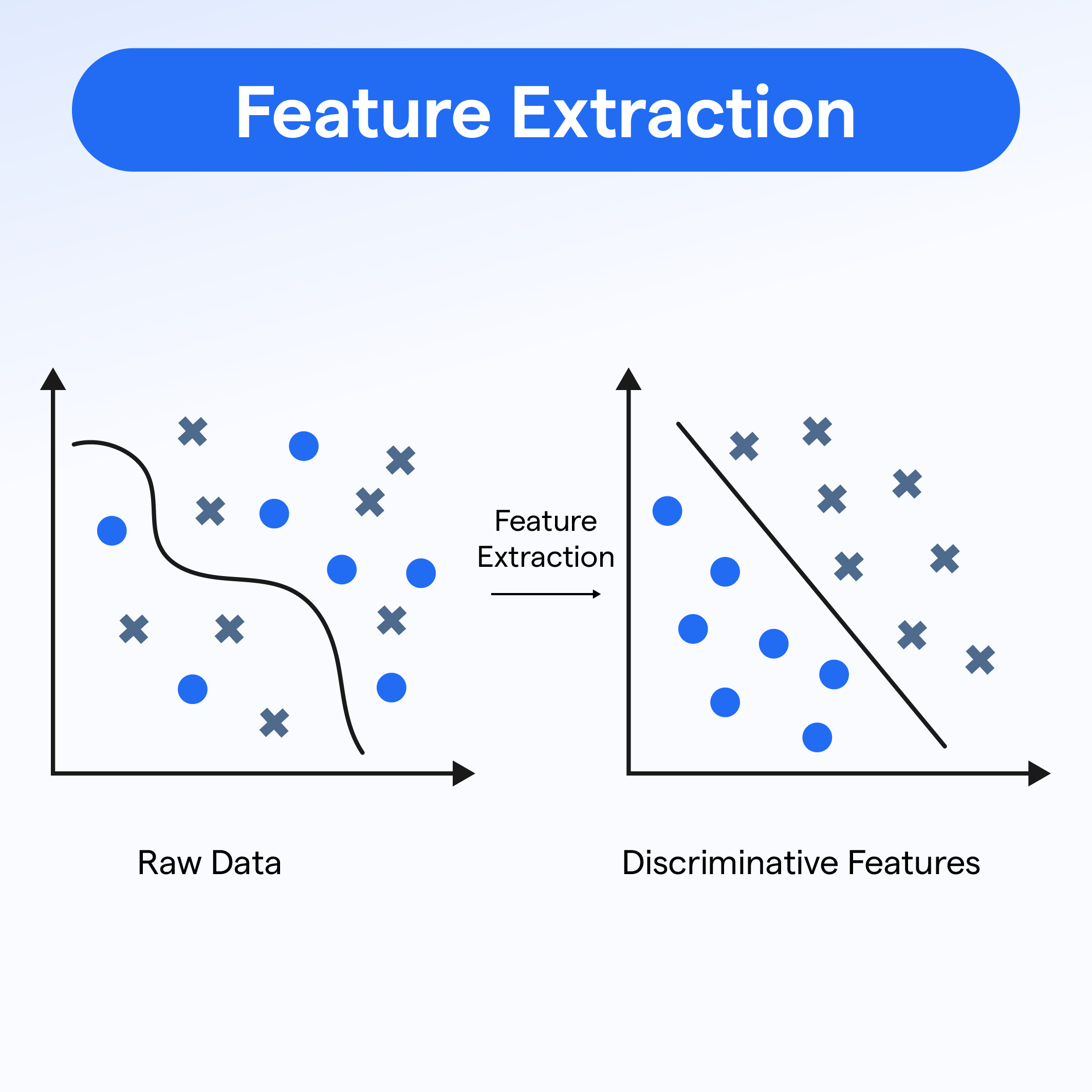
Language detection algorithms use feature extraction techniques to capture important aspects of the text.
Common features include character n-grams, word n-grams, or even more complex linguistic features. These features help in distinguishing one language from another.
Model Creation
Once the features are extracted, the language detection algorithm creates language models based on these features. The models capture the statistical patterns and characteristics of each language.
There are several methods for creating language models, including short word-based approaches, frequent words methods, and N-gram based methods.
Statistical Analysis
The language detection algorithm uses statistical analysis techniques to compare the input text with the created language models.
This analysis involves calculating probabilities or scores for the input text belonging to each language based on the extracted features. The language with the highest probability or score is considered the detected language.
Language Identification
Once the statistical analysis is complete, the algorithm identifies the language with the highest probability or score as the detected language.
This language identification can be performed using various classifiers, such as decision trees, support vector machines, or neural networks.
It's important to note that the accuracy of language detection depends on factors such as the availability and diversity of the training data, the characteristics of the languages being analyzed, and the length and structure of the input text.
Despite these limitations, continuous improvement and refinement of language detection algorithms can enhance accuracy over time.
Language Modelling Methods
Language detection involves creating language models that represent distinct characteristics of each language.
These models include entities like words or N-grams and their occurrences in the training set. There are several methods for creating language models:
Short Word-Based Approach
The short word-based approach focuses on the significance of common short words like determiners, conjunctions, and prepositions.
These words typically have small lengths, ranging from 4 to 5 letters. By considering the frequency and presence of these short words, language models can identify the language of a given text.
Frequent Words Method
The frequent words method uses words with higher frequencies as indicators in language models. Following Zipf's Law, which states that certain words appear more frequently than others, this approach selects commonly occurring words as language indicators.
By including these frequently used words in the language model, the detection process becomes more accurate and efficient.
N-Gram Based Approach
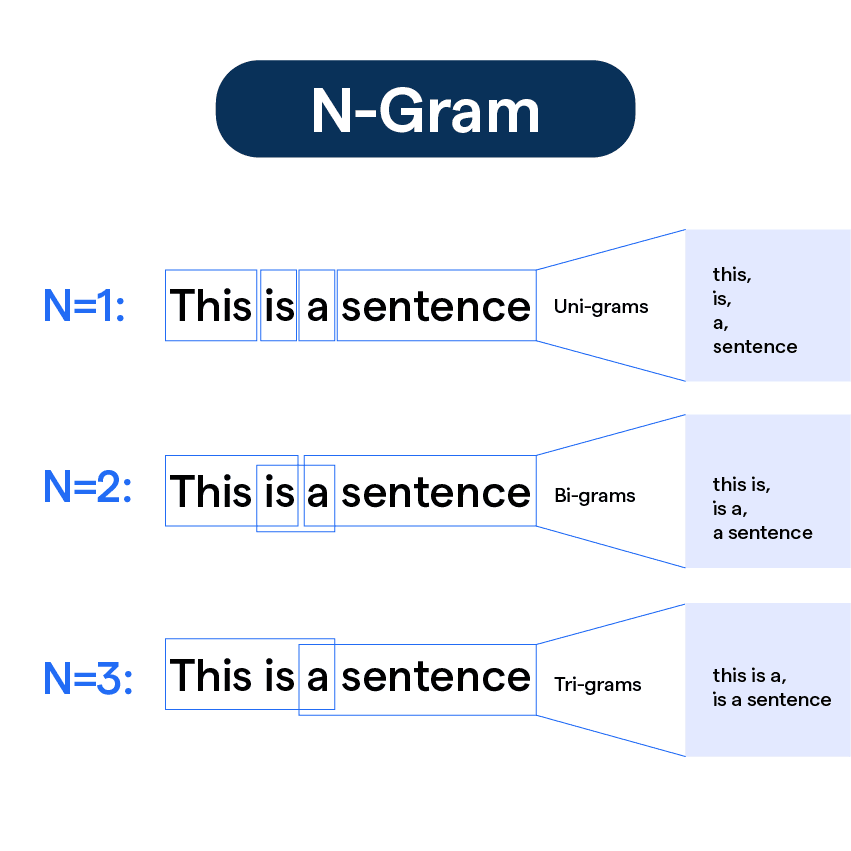
The N-gram-based approach generates language models using N-grams instead of complete words. N-grams are contiguous sequences of N items, such as characters or groups of words.
By creating N-grams from a collection of documents, language models can capture language-specific patterns and characteristics. This approach is particularly useful for short texts or analyzing languages without clear word boundaries.
Applications of Language Detection
Language detection finds wide-ranging applications in various domains:
Simplifying Content Translation
Language detection can make the process of translating content from one language to another a breeze.
When an application knows what language text is in, it can automatically translate it to a language of choice, making things smoother and faster!
Boosting Customer Service
Language detection strikes gold in customer service too! It can help provide better, personalized experiences by determining a customer's preferred language and replying in the same.
This way, we can keep communication clear, effective, and friendly.
Enhancing Social Media Analysis
In the world of social media analysis, language detection is an absolute game-changer.
By identifying the language of posts, comments, or tweets, data analysts can better understand sentiment, trends, and behaviors across different languages.
Streamlining Multilingual Websites
Multilingual websites can benefit significantly from language detection. On detecting the viewer's language preference, the website can automatically present content in that language.
Say goodbye to the hassle of manual language selection!
Improving Security and Compliance
Language detection can also play a pivotal role in security and compliance.
It can help in detecting inappropriate content in different languages, ensuring the safety of online platforms and adherence to legal guidelines.
Accuracy and Limitations of Language Detection
While language detection models strive for accuracy, there are certain limitations to be aware of. Factors that influence accuracy include the availability and diversity of the training dataset, the specific characteristics of the language being analyzed, and the length and structure of the input sentence.
The accuracy of language detection models also depends on the similarity between languages. Similar languages, such as Portuguese and Spanish, or French and Italian, can pose challenges in distinguishing between them accurately.
It is important to note that despite these limitations, continuous improvement and refining of language detection algorithms can enhance accuracy over time.
Frequently Asked Questions (FAQs)
What tools and libraries are available for implementing language detection?
There are several tools and libraries available for implementing language detection, including language detection libraries in various programming languages, such as Python, Java, and JavaScript. Some popular tools include LangID, TextBlob, and NLTK.
Can language detection handle short or incomplete texts?
Language detection algorithms can handle short texts, but the accuracy may be affected as shorter texts provide less information for analysis.
Incomplete texts may pose challenges as there may not be enough context to accurately determine the language.
What languages are supported by language detection algorithms?
Language detection algorithms typically support a wide range of languages, including commonly spoken languages like English, Spanish, French, German, Chinese, Japanese, Arabic, and many others. The specific set of supported languages depends on the language detection tool or library being used.
Can language detection handle multilingual texts?
Language detection algorithms can handle multilingual texts to some extent. However, when the text contains multiple languages, it becomes more challenging to accurately determine the dominant language or identify each language precisely. Specialized techniques like language switch detection can help in such cases.
Can language detection be used for language identification in spoken conversations?
Language detection is primarily designed to identify the language of written text. While it can be adapted for language identification in spoken conversations, additional techniques like audio processing and language recognition methods are usually employed to accurately identify spoken languages.