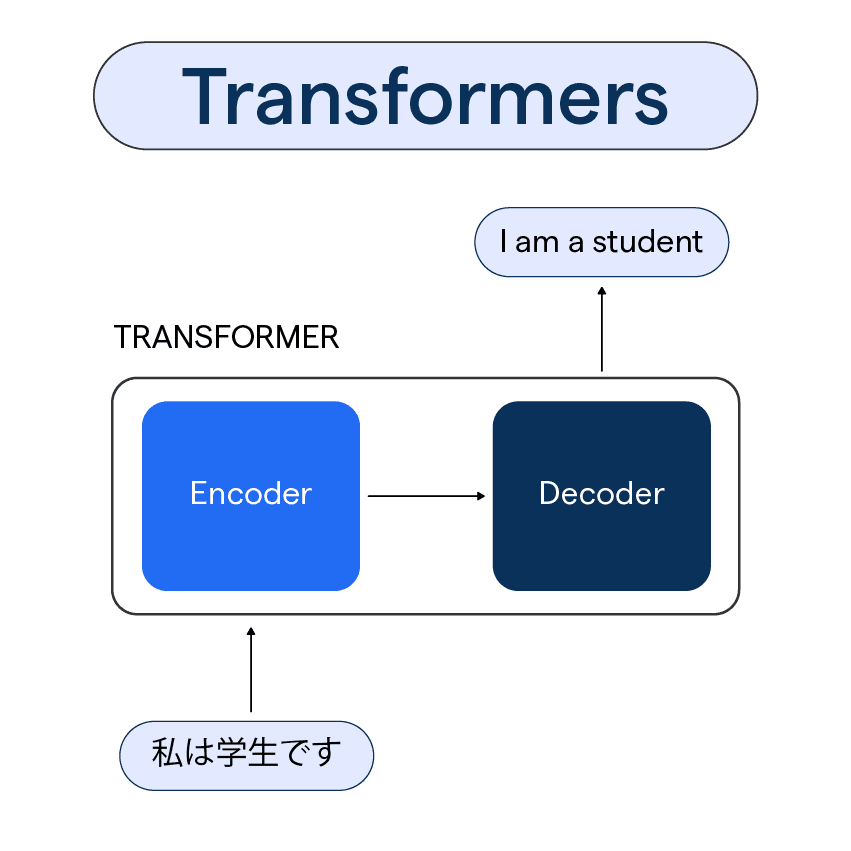
Transformers in NLP: An Overview
Transformers are models in NLP that take on language processing tasks with a novel approach. They focus on the context of words in a sentence, providing a more accurate understanding of the text compared to traditional methods.
Why are Transformers Important?
Transformers models in Natural Language Processing (NLP) are incredibly important for several reasons:
- Advances in language comprehension: They have made significant improvements in how machines understand language, including generating coherent responses, answering questions, and enhancing machine translation.
- Outperforming previous models: Models like GPT and BERT, which are based on transformer architecture, have surpassed the performance of earlier state-of-the-art networks, bringing substantial improvements in efficiency and accuracy to the NLP field.
- Large-scale language models: Transformer models like GPT-3 have shown that increasing their scale leads to remarkable improvements, producing human-like text virtually indistinguishable from that written by an actual person.
- Inspiring new model variations: Transformers have also paved the way for various model variations like RoBERTa, ALBERT, and XLNet, contributing to the steady progress of NLP task performance.
Where are Transformers Used?
Transformers are used in an array of applications. Whether it's machine translation, syntactic parsing, text summarization, or chatbots, Transformers are revolutionizing the way these systems understand and generate human language.
Training Methods for Transformers in NLP
In this section, we'll delve into the training methods commonly employed for training transformer models in natural language processing tasks.
Pretraining with Masked Language Modeling
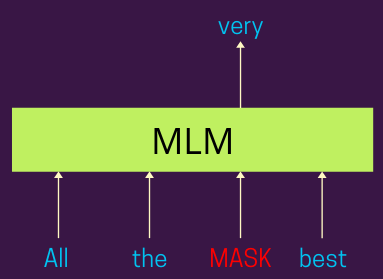
Masked Language Modeling (MLM) is a pretraining technique where the model learns to predict masked words in a sentence. The model is trained on a large corpus of text and encouraged to understand linguistic patterns, relationships, and semantics in a self-supervised manner.
Fine-tuning on Task-specific Data
After pretraining, transformers are fine-tuned on labeled data specific to the target task. This supervised process enables the model to adapt its general language understanding to the nuances and requirements of the specific problem it needs to solve.
Teacher-Student Distillation
Training large transformer models can be resource-intensive. Teacher-Student Distillation is a method where a compact student model learns from a larger pretrained teacher model. The student model imitates the behavior of a teacher model, achieving comparable performance with less computational requirements.
Transfer Learning
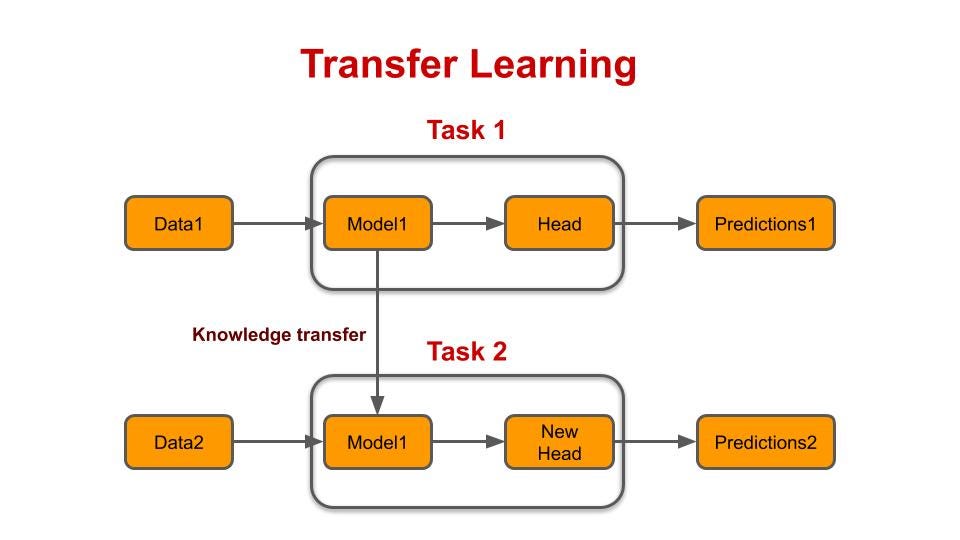
Transfer learning is a common approach in NLP where the knowledge acquired by a pretrained model on a large corpus is leveraged to solve a different but related task. This reduces training time and computational resources while achieving high performance on the target task.
By employing these training methods, transformer models can be effectively taught to handle diverse natural language processing tasks, ensuring high performance and adaptability across different domains.
Continuous Pretraining
Some transformers follow continuous pretraining, where the model is iteratively updated with more data or newer versions of the original data. This allows the model to continuously improve and adapt to changing contexts and requirements.
The Architecture of a Transformer Model in Natural Language Processing (NLP)
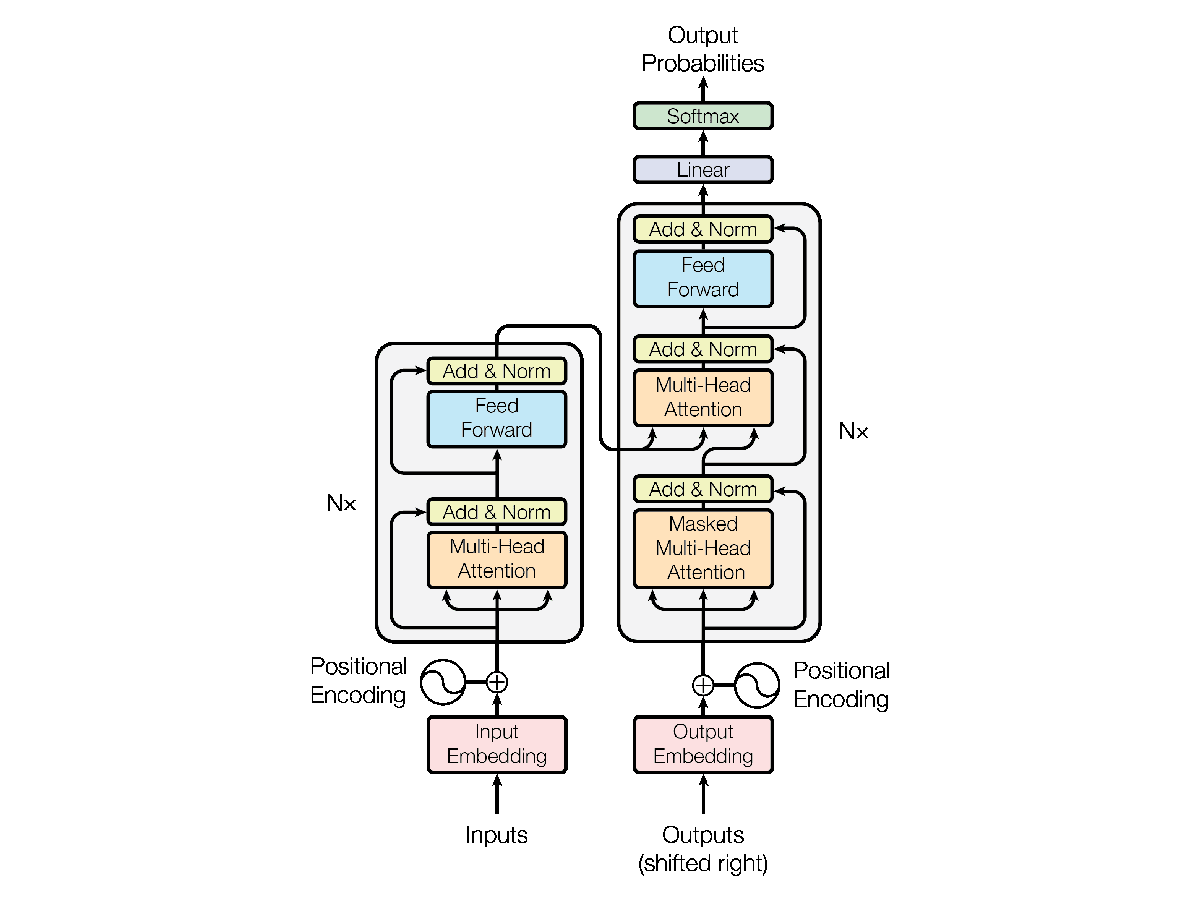
In this section, we're going to delve deep into the architecture of a commonly used transformer model in NLP, a significant leap in the field, facilitating a more meaningful and contextual understanding of language.
Conceptual Overview
The Transformer model, introduced in the paper "Attention is All You Need", is a type of architecture that leverages attention mechanisms predominantly in NLP tasks such as machine translation, text generation, and sentiment analysis.
The Encoder-Decoder Structure
The transformer model follows an encoder-decoder architecture. The encoder part takes in the input text and converts it into a list of vectors—each representing a learned representation of the input text. The decoder part then generates the output text by feeding off these learned representations and its own input state.
Self-Attention Mechanism
One of the key components of transformer models is the Self-Attention mechanism. This allows the model to weigh and prioritize different words in an input sentence based on their relevance, adding a layer of context to the parsing of textual information.
Positional Encoding
Since transformer models do not inherently capture the sequence information present in the input data, they employ a technique called Positional Encoding. This adds information about the position of the words in the sentence, granting the model knowledge about the order of words, which is a crucial aspect in language understanding.
Layered Architecture
A typical transformer model is stacked with multiple layers of encoders and decoders, each having their own self-attention and feed-forward neural network components. More layers mean that the model can capture complex relationships and dependencies in the input data, enabling higher comprehension of the language structure.
Multi-Head Attention in Transformer Models
In this section, we'll explore the concept of Multi-Head Attention in Transformer Models in Natural Language Processing.
Understanding the Attention Mechanism
At its core, the attention mechanism assigns different levels of importance to elements in a sequence, allowing models to focus on relevant portions while processing information. It boosts the Transformer model's ability to handle dependencies between words, irrespective of their distance in a sentence.
Introduction of Multi-Head Attention
Multi-Head Attention is an extension of the attention mechanism in Transformers, designed to expand the model's capacity to focus on different positions. It enables the model to simultaneously focus on different parts of the sentence, capturing various aspects of the information conveyed.
How Does Multi-Head Attention Work
In Multi-Head Attention, the input is initially divided into multiple subsets. Each subset then independently undergoes the attention process, generating multiple output vectors instead of a single one. This promotes a diversified understanding of context and word associations from multiple perspectives.
Aggregation of Information
The multiple output vectors derived from each "head" in the Multi-Head Attention stage are then concatenated and linearly transformed into the final output. This combined information represents various detected patterns or relationships in the sentence, offering a richer interpretation.
Enhancing Model's Capability
Incorporating Multi-Head Attention serves to enhance the model's ability to understand complex language nuances by tracking different types of contextual relationships. It improves the model's flexibility, allowing it to adapt to various tasks in NLP with improved performance, notably in areas such as translation, summarization, and sentiment analysis.
Frequently Asked Questions (FAQs)

Why are transformers important in NLP?
Transformers are crucial in NLP as they revolutionized language understanding, handling long-range dependencies effectively, and excelling in various tasks like machine translation and text generation.
What is the benefit of using Transformers in NLP?
Transformers offer faster training, outperform traditional models, and allow fine-tuning for specific NLP tasks with minimal data.
How do transformers handle long-range dependencies?
Transformers use attention mechanisms to capture relationships between distant words, preserving context throughout the text.
Can transformers generate human-like text?
Yes, transformers can generate human-like text through language modeling and conditional generation.
Are transformers the only models used in NLP?
While transformers are popular, traditional models like RNNs and CNNs are still used in specific scenarios.