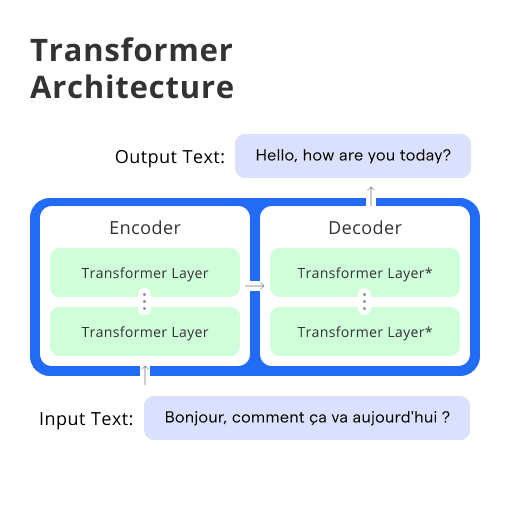
What is the Transformer Architecture?
Transformer architecture is a model architecture used predominantly in Natural Language Processing (NLP). Introduced in the ground-breaking paper "Attention is all you need" by Vaswani et al., the model leverages attention mechanisms to capture different kinds of relationships in input data without depending on time-series data.
Origins of Transformer Architecture
The architecture was introduced as a solution to the limitations of Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs), which were commonly used for NLP tasks. The transformer model provides more efficient and context-sensitive language understanding than its predecessors.
Components of Transformer Architecture
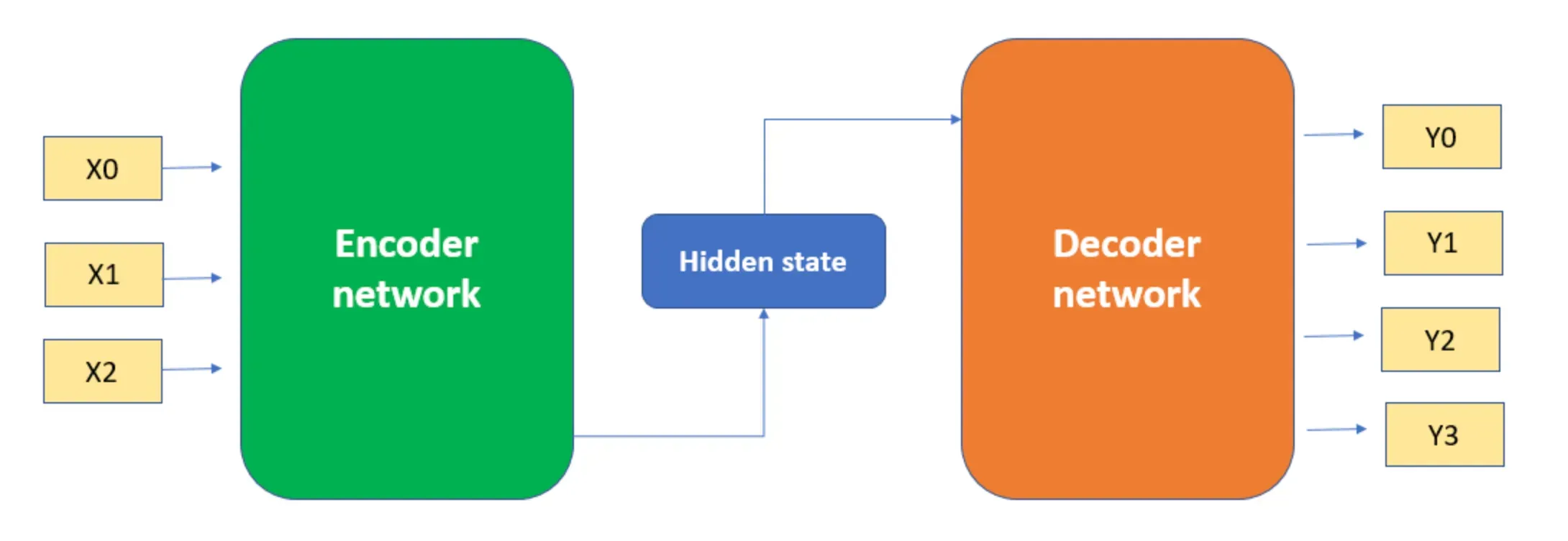
The transformer model is composed of an encoder and a decoder, each of which is made up of several identical layers. The ability to process all words or symbols in parallel while capturing the context gives the architecture its edge.
Role in NLP
Transformer Architecture plays a highly significant role in a multitude of NLP tasks, including machine translation, text generation, named entity recognition, and more. Its remarkable feature of considering context through self-attention makes it apt for language processing tasks.
Core Components of The Transformer
Moving a step further, let's explore the key components that construct the amazing Transformer Architecture.
Encoders
Each encoder in the architecture consists of a self-attention layer and a feed-forward neural network. The encoders consume the input sequence and encode the information into a continuous representation which carries throughout the model.
Decoders
The decoders use the encoder's entire output to focus the attention mechanism at appropriate places in the input sequence. The target output sequence is generated using the encoded input and its own input.
Self-Attention Mechanism
At the core of the Transformer's success is the self-attention mechanism. It is through this mechanism that the model computes context-aware representations of words or symbols in the sequence by considering all words for every word.
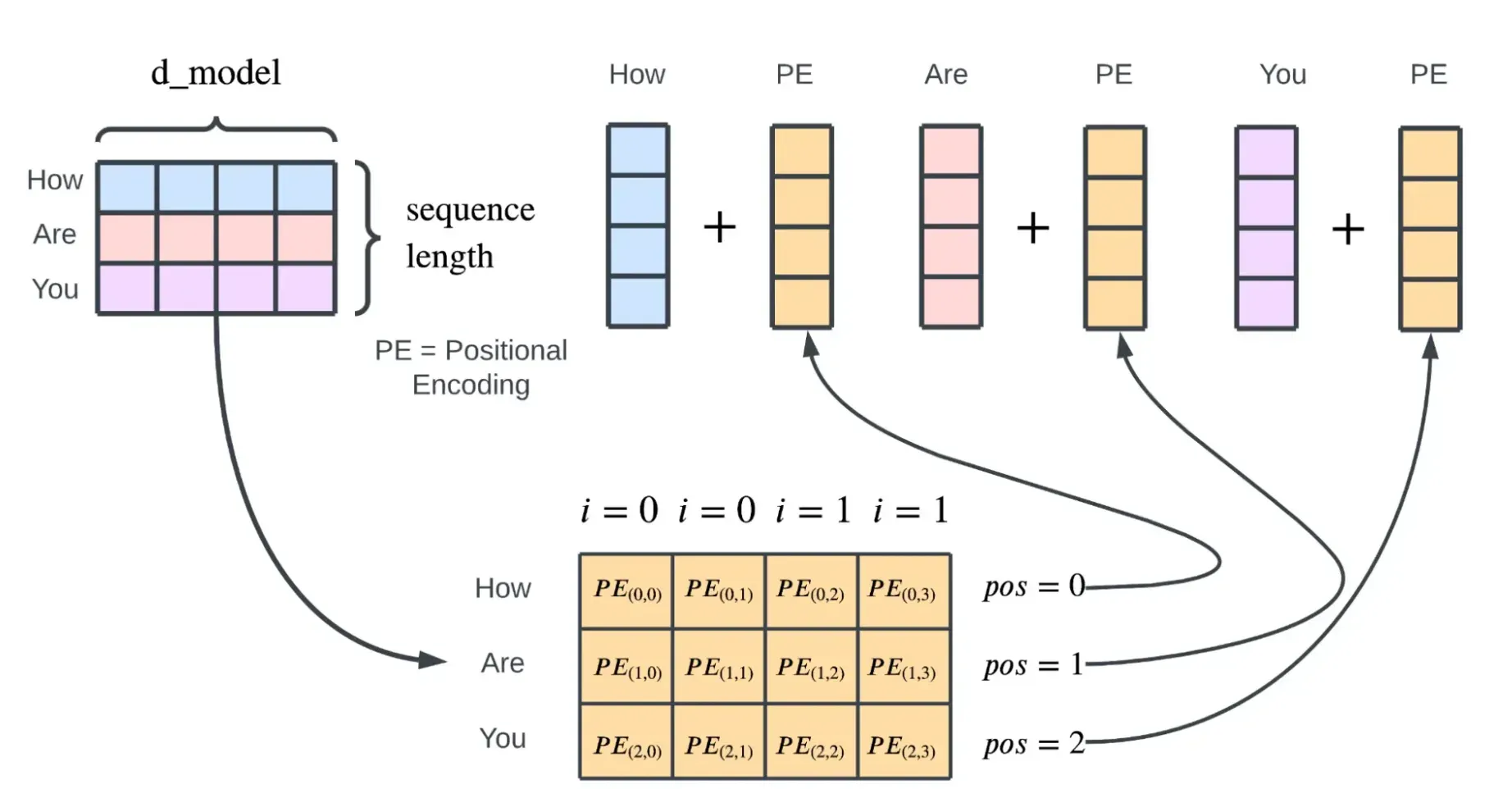
Positional Encoding
Despite its many strengths, the Transformer inherently lacks knowledge of the order or position of words. Positional encoding is embedded in the sequence to retain the order of words, effectively compensating for the model's shortcomings.
Salient Features of Transformer Architecture
To truly understand the Transformer, we need to unearth the unique features that truly make it stand out amongst others.
Parallelization Capabilities
Unlike RNNs, Transformers deal with entire sequences at once, allowing model training to be parallelized. This feature significantly reduces training durations, making Transformers a preferred choice for large-scale language models.
Handling of Long-Term Dependencies
Transformers, with their self-attention mechanism, can manage long-term dependencies much better than RNNs can. The architecture efficiently highlights relationships between words irrespective of their positions in the sequence.
Scalability Advantage
Large-scale language models like GPT-3 and BERT utilize the Transformer architecture, demonstrating its excellent scalability. These models have achieved impressive results on several NLP tasks, including translation and text completion.
Flexibility for Various Tasks
Transformers can be used for various tasks in machine translation and beyond. With slight alterations, Transformer models can be fine-tuned for text classification, sentiment analysis, summarization, and more.
The Inner Workings of the Transformer
Let's dive deep into the inner mechanisms of the Transformer architecture and understand its working.

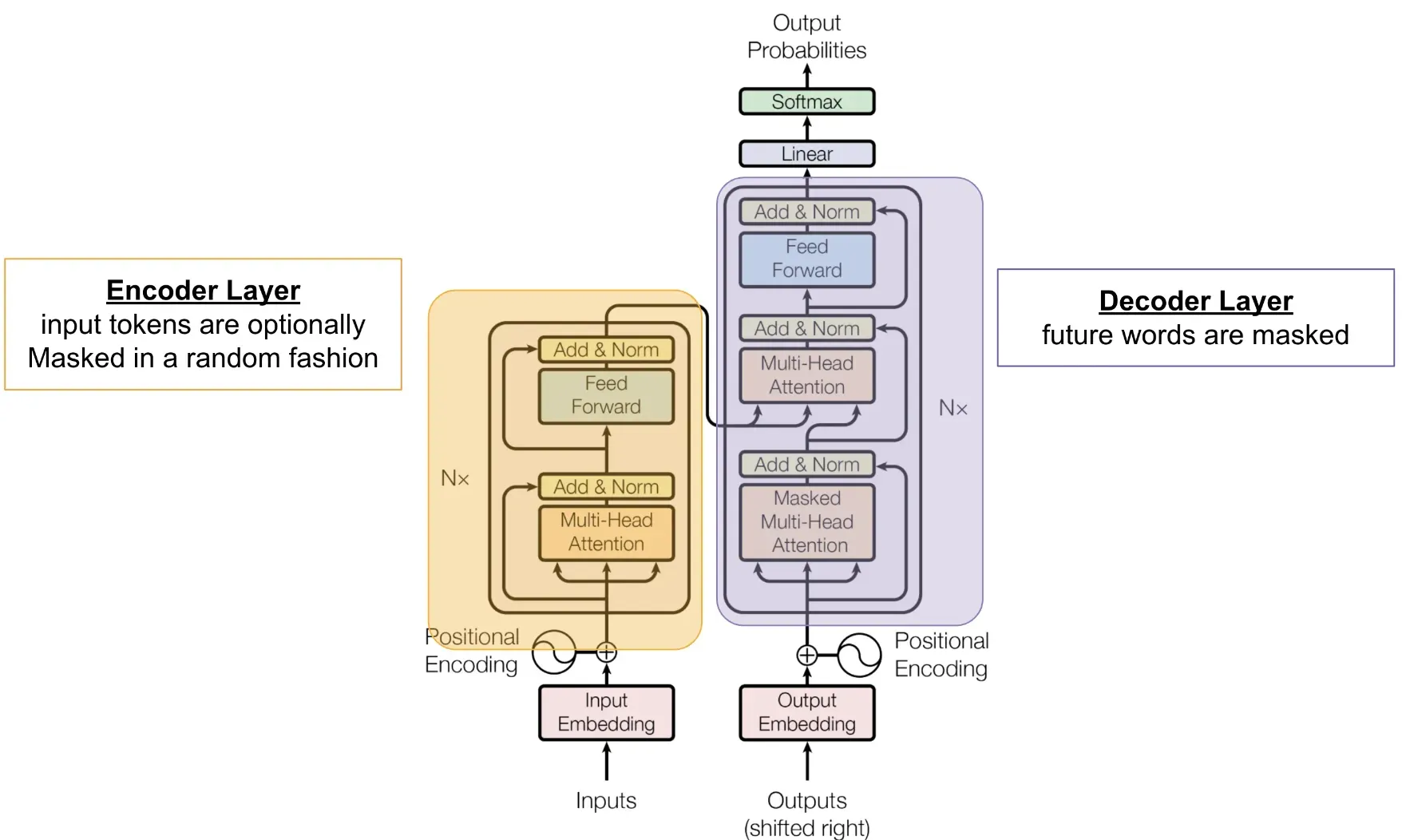
1. Input Representation
Transformers process input data in the form of sequences. Each word or token in the sequence is converted into a fixed-size vector representation using an embedding layer. These vectors serve as the input for the encoder layers.
2. Positional Encoding
A crucial step in the Transformer's workings is incorporating positional information, as the model doesn't have inherent knowledge of word order. Positional encodings, usually sine and cosine functions, are added to the input word embeddings to capture word positions and enable the model to learn sequence patterns.
3. Multi-Head Self-Attention Mechanism
The heart of the Transformer is the multi-head self-attention mechanism. In this step, the model calculates attention scores by comparing each world against all others in the sequence. The attention scores are then used to weigh the importance of individual words and compute a context-aware representation for each position.
The self-attention mechanism is performed multiple times in parallel within the architecture, known as the multi-head setup. This setup allows the model to capture different types of relationships between words and better understand the context.
4. Normalization and Feedforward
After multi-head self-attention computation, layer normalization is applied in both the encoder and decoder branches. It stabilizes the layer inputs and accelerates the training process. Then, each normalized output enters a position-wise feedforward neural network that further refines the representation and helps the model learn high-level features of the input text.
5. Decoder in Action
In the decoder, a masked multi-head self-attention mechanism prevents the model from attending to the "future" tokens in the target sequence. Then, a second multi-head attention layer connects the output of the decoder's self-attention layer with the encoder's outputs, forming a bridge between the context from the source text and the generated target text. This is followed by another layer of normalization, position-wise feedforward, and normalization steps.
6. Output Generation
The final step in the Transformer's workings is generating the output sequence. Utilizing a linear layer followed by a softmax function, the transformer assigns probabilities to words in the target vocabulary. The highest probability word is selected as the next word in the output sequence. This process continues until a designated end-of-sequence token is generated or a maximum sequence length is reached.
Applications of Transformer Models
The applications of Transformer models illustrate their utility in real-world scenarios. Let's uncover some of these applications.
Machine Translation
The inaugural application of Transformer architecture was in machine translation. Here, it excels with its ability to address long-distance relationships between components of language.
Text Summarization
Transformers have proven to be an extraordinary tool for text summarization tasks. By understanding the context and prioritizing salient points, they generate coherent and informative summaries.
Text Generation
Technologies like chatbots, autocompletion tools, and AI writing assistants use Transformer models for text generation, leveraging their ability to predict the next word in a sequence based on context.
Question-Answering Tasks
In a question-answering setup, Transformers shine due to their proficiency in understanding the context. Models fine-tuned on SQuAD, an expansive question-answering dataset, have achieved human-level accuracy on these tasks.
Limitations of Transformer Architecture
No systems are perfect, and the Transformer is no exception. Let's consider some of the limitations of this architecture.
Struggle with Sequential Data
Although Transformers have their strengths, they aren't the best fit for tasks that require understanding the precise timing and sequence of events, such as in music classification or generative tasks.
High Resource Requirement
Transformers, especially larger models, tend to have a high demand for computational resources, making them expensive and difficult to train.
Lack of Transparency
Like many deep learning models, Transformers are often considered black-box models, and their decision-making process can be hard to interpret.
Possibility of Overfitting
With a larger number of parameters, Transformers bear the risk of overfitting, especially when dealing with limited training data.
Addressing the Limitations
In spite of the limitations, with the right strategies, the benefits of Transformers can still be harnessed effectively.
Hybrid Models
For tasks where sequential understanding is crucial, hybrid models incorporating both Transformers and RNNs are being explored.
Efficient Training Practices
Practices like model pruning, knowledge distillation, and hardware optimization can mitigate resource concerns while training Transformers.
Visualization Tools
To address transparency issues, different tools are being developed to visualize the attention mechanism within Transformers.
Regularization Techniques
Implementing regularization techniques during model training can help ward off overfitting and improve the model's stability and robustness.
Future of Transformer Architecture
Having covered numerous aspects of the present-day Transformer, it's time to ponder about its future prospects.
Heralding Bigger Models
With continued advancements in hardware, expect to see even larger Transformer models that house more parameters and deliver richer language understanding.
Leveraging in Other Domains
While NLP has been the primary playground for Transformers, there is significant potential for their application in other domains, such as image recognition and genomic sequence prediction.
Aiding Low-Resource Languages
Transformers could be instrumental in enhancing NLP tasks for low-resource languages. By deploying techniques like cross-lingual training, their comprehensiveness can be improved significantly.
Exploring Local Attention Mechanisms
While current Transformers use global attention, in the future, models with local attention mechanisms could provide efficiency gains in tackling large sequences of data.
In conclusion, the Transformer architecture, a relatively new entrant in the NLP landscape, has revolutionized language understanding and NLP tasks. With its fascinating design and promising results, it certainly holds a thrilling future.
Frequently Asked Questions (FAQs)
How do Transformers capture long-range dependencies in data?
Transformers leverage the self-attention mechanism to assign different weights to different words, allowing them to focus on relevant parts of the sequence and capture long-range dependencies effectively.
Are Transformers faster than recurrent neural networks?
Yes, Transformers are faster than recurrent neural networks as they process the entire sequence in parallel. This parallelization speeds up training and inference times, making them more efficient for large-scale applications.
Can Transformers handle non-sequential data?
While Transformers are optimized for sequential processing, they can be adapted to handle non-sequential data. However, additional adaptations or hybrid models might be needed to ensure their effectiveness in such cases.
How much data do Transformers require for optimal performance?
Transformers typically require large amounts of data to achieve optimal performance. Pre-training on large-scale datasets has been found to significantly improve their performance, making them less suitable for tasks with limited labeled data.
What are the limitations of Transformer architecture?
Some limitations of Transformer architecture include its computational complexity, data requirements, and potential challenges in handling non-sequential data. Understanding these limitations is essential when considering the suitability of Transformers for specific applications.