What Is Speech Synthesis?
Speech synthesis is technology that turns written text into spoken words. It is also called text-to-speech or TTS.
Every time you hear a navigation app give you directions, a screen reader speak a web page, or an AI voice agent answer a call, speech synthesis is working.
It is the voice behind the machine, the engine that makes devices speak.
Explore Voice AI | See How AI Voice Agents Work
How Does Speech Synthesis Work?
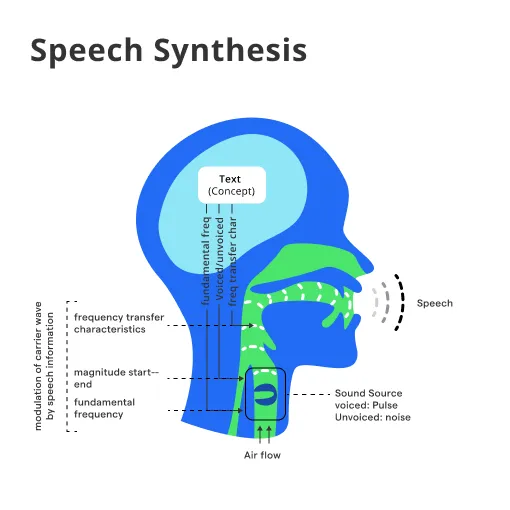
Text-to-speech works in three steps: clean up the text, decide how it should sound, and generate the audio.
Text Analysis and Normalization
First, the system reads the text and expands things like numbers and abbreviations.
"2026" becomes "twenty twenty-six" and "Dr." becomes "doctor." The system breaks text into sound units it can process.
Acoustic Model and Waveform Generation
Next, a model predicts pitch, timing, and stress, deciding how the words should sound.
Finally, the audio waveform is generated, creating the actual spoken voice you hear.
What Are the Different Types of Speech Synthesis?
There are three main types, ranging from older to newer approaches.
Older Approaches vs Neural TTS
Old methods stitched together recorded voice fragments, or used statistical rules to sound out words.
Modern neural text-to-speech uses AI trained on real human voices to generate natural, expressive speech. It sounds far more human than earlier approaches.
How Do AI Voice Agents Use Speech Synthesis?
When an AI voice agent answers a phone call, speech synthesis is what makes it speak.
The agent first listens using speech recognition, figures out an answer, then uses speech synthesis to voice that answer.
This happens fast enough that a conversation feels natural. The caller barely notices it is automated.
Explore Voice AI | See How AI Voice Agents Work
Agencies can offer white-label AI voice agents using speech synthesis.
Frequently Asked Questions (FAQs)
What is speech synthesis?
Speech synthesis is technology that converts written text into spoken audio. It is also called text-to-speech or TTS, and it powers voice assistants, screen readers, and AI voice agents.
What is the difference between speech synthesis and speech recognition?
Synthesis turns text into speech, which is the output side. Recognition turns speech into text, which is the input side. Voice agents use both: recognition to listen and synthesis to speak.
How does speech synthesis work?
Text is cleaned and broken into sound units. A model then predicts pitch and timing. Finally, an audio waveform is generated using an acoustic model to produce the spoken output.
What is neural text-to-speech?
Neural TTS is a modern AI-based approach that uses deep learning to generate natural, expressive speech. It replaces older stitched-fragment methods and is what most voice products use today.
How do AI voice agents use speech synthesis?
After understanding a caller's request, the agent uses TTS to voice its spoken reply. Real-time generation allows natural conversation without a human being involved on the other end.
Is speech synthesis the same as text-to-speech?
Yes. Both terms mean the same thing: generating spoken audio from text. "Speech synthesis" is the technical term, while "text-to-speech" is the everyday version most people use.
Does speech synthesis support multiple languages?
Yes. Most modern neural TTS systems support a wide range of languages and regional accents. Coverage varies by provider and model, so check the supported language list before deploying in a multilingual market.
How natural does AI-generated speech sound today?
Modern neural TTS sounds significantly more natural than older systems. Listeners often cannot tell the difference in a normal conversation. Quality depends on the model, the language, and how well the text input is formatted.