
Selecting Model Architecture & Design In LLM Development
Updated at Nov 5, 2024
11 min to read
Large language models (LLMs) like GPT-3 and PaLM are driving explosive AI progress through their ability to understand, generate, summarize, translate and reason about natural language with human-like competence. The global LLM market is projected to expand 9x from USD 1.5 billion in 2021 to 14 billion by 2028 at a CAGR of 34.7% as adoption widens across enterprise functions (Reports and Data).
However, successfully leveraging LLMs requires strategic governance, testing and monitoring to ensure enterprise reliability, safety, and standards alignment before full deployment. Over 63% of organizations actively experiment with LLMs, but only 14% have put LLMs into production due to limitations around accuracy, bias and transparency (Appen).
As leading options emerge from OpenAI, Anthropic, Microsoft, Google, and more in 2023, this LLM development guide shares best practices for training, evaluating, and monitoring enterprise language models ready for the rigor of real-world usage across diverse demographics and verticals.
With traction growing exponentially daily, organizations must balance innovation appetite with responsible, ethical LLM development. If teams consider all applications and vulnerabilities upfront, LLMs promise immense opportunities to positively progress business and society.
In this article, you will learn the up-to-date process of LLM development in 2024 and its future trends.
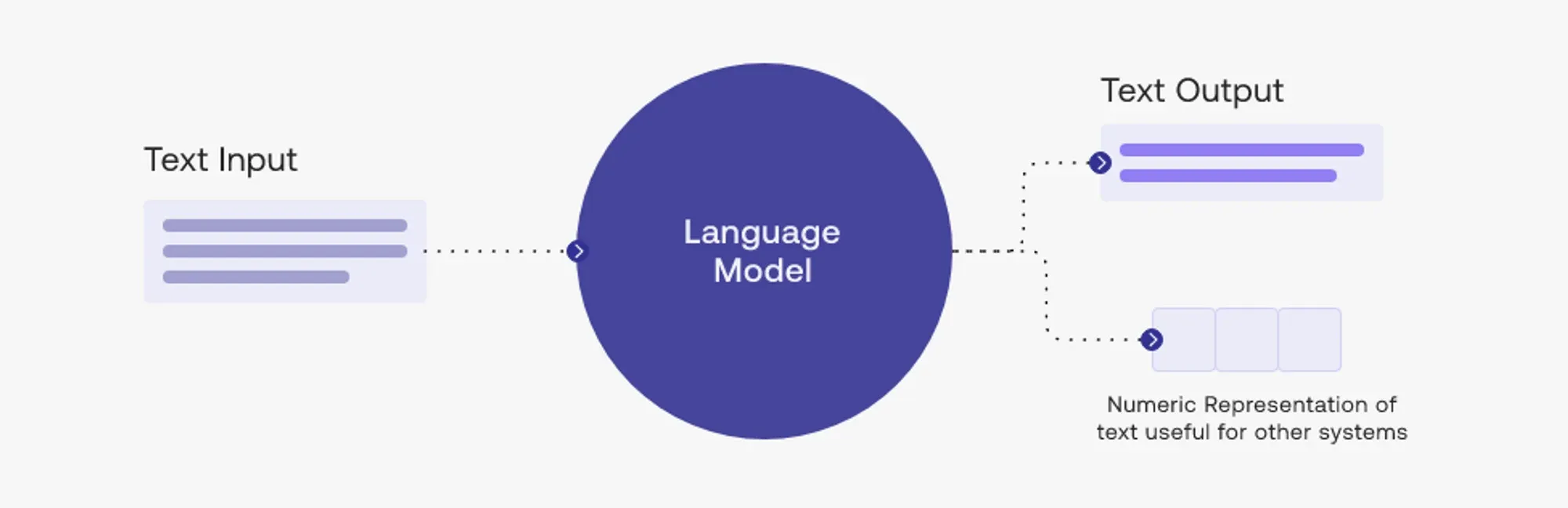
LLM, short for large language model, refers to developing machine learning models that enable machines to comprehend and generate human-like language. These models are trained on vast amounts of text data and use sophisticated algorithms to analyze and understand the meaning, structure, and context of language.
Traditional language development often relies on predefined rules and patterns to process and understand language. LLM, on the other hand, leverages the power of artificial intelligence and deep learning techniques to create models that learn from vast amounts of text data and adapt to various linguistic nuances.
This approach allows LLM models to handle complex language tasks that traditional methods struggle with, such as natural language understanding and generation.
The emergence of LLM technology brings forth many benefits and opens up a wide range of applications. LLM models can assist in language translation, sentiment analysis, text summarization, chatbot development, and more.
They provide accurate and efficient solutions to automate language-related tasks, improve customer support, enhance content creation, and streamline business processes. LLM technology can potentially transform various industries, including healthcare, finance, e-commerce, and education.
To achieve successful LLM development, it is essential to understand the key components involved. In this section, we will explore the stages of LLM development, which include data collection and preprocessing, model training and evaluation, fine-tuning and optimization, and deployment and implementation.
Data collection forms the foundation of LLM development. Large and diverse datasets are required to train LLM models effectively. These datasets can contain various text types, such as books, articles, websites, and social media posts. Any relevant data should be obtained ethically, ensuring privacy and legal compliance.
Once the data is collected, it needs to be preprocessed to remove noise, correct errors, and organize it in a suitable format for training. Preprocessing involves tasks like tokenization (splitting text into words or sentences), normalizing text (converting to lowercase, removing punctuation), and handling special characters or symbols.
The next crucial step is to train the LLM model using the preprocessed data. Model training involves feeding the data to the model and optimizing its parameters through a process known as backpropagation. This allows the model to learn patterns and relationships within the data.
Evaluation is an essential part of LLM development, ensuring the model's performance and quality. Evaluation metrics, such as accuracy or perplexity, assess the model's ability to understand and generate language accurately. Iterative training and evaluation are often performed to improve the model's performance.
Fine-tuning large language models is refining the trained model to adapt it to specific tasks or domains. This involves training the LLM model on smaller, task-specific datasets and adjusting its parameters to improve performance. Fine-tuning helps tailor the model to understand better and generate language relevant to the target application.
Optimization techniques, such as regularization, parameter tuning, and hyperparameter optimization, enhance the model's performance and mitigate issues like overfitting or underfitting. This ensures the model performs well on real-world data and achieves the desired outcomes.
The final stage of LLM development involves deploying and implementing the trained model into a production environment. This typically involves integrating the model into an application or platform to make it accessible and usable by end-users. Deployment considerations include scalability, efficiency, and computational requirements.
Continuous monitoring and maintenance are crucial to ensure the model's performance remains optimal. Regular updates, bug fixes, and improvements may be necessary to keep up with evolving language patterns and user demands.
And, beginning with LLM development for your business need not be that tough. Meet BotPenguin, the home of AI-driven chatbot solutions
BotPenguin houses experienced developers with 5+ years of expertise who know their way around NLP and LLM bot development in different frameworks.
And that's not it! They can assist you in implementing some of the prominent language models like GPT 4, Google PaLM, and Claude into your chatbot to enhance its language understanding and generative capabilities, depending on your business needs.
Developing large language models (LLMs) comes with its own set of challenges and considerations. Ethical concerns and bias, privacy and security considerations, and legal and regulatory implications must be addressed to ensure responsible and conscientious LLM development.
Language models trained on vast amounts of data can inadvertently perpetuate biases present in the data. This can lead to biased outputs that reinforce societal prejudices and discrimination. Ethical considerations arise when LLMs unintentionally discriminate against certain demographics or perpetuate harmful stereotypes.
Developers must be vigilant in identifying and addressing biases within training datasets to mitigate these issues and ensure fair and unbiased language generation.
Developers must prioritize user privacy and data protection when building LLMs. The handling and protection of user data must comply with data protection and privacy regulations.
Implementing measures such as data anonymization, obtaining user consent for data use, and incorporating robust data security practices are essential. Ensuring the privacy and security of user data instills trust and safeguards against potential data breaches or misuse.
The development of LLMs is not exempt from legal and regulatory considerations. Language models may generate text that infringes intellectual property rights, violates privacy, or disseminates false information.
Developers need to be aware of the legal implications and ensure that their models comply with copyright, defamation, and other relevant laws and regulations. Adhering to legal and regulatory requirements protects both users and developers and fosters responsible and lawful use of LLM technology.
Suggested Reading:
To achieve successful LLM development, it is essential to follow best practices throughout the process. In this section, we will explore some key practices that contribute to the success of LLM development, including setting clear objectives and goals, choosing the right data sources and implementing quality control measures, selecting appropriate model architectures, and adopting an iterative development and evaluation process.
Before embarking on LLM development, it is crucial to define clear objectives and goals. This involves identifying the specific language tasks to be addressed and determining the desired outcomes. Clear objectives help guide the development process and ensure the resulting LLM meets the intended purpose.
Selecting the appropriate data sources is critical to the success of an LLM. High-quality and diverse datasets are essential for training robust and unbiased language models. Careful consideration should be given to the sources and their representativeness of the target domain.
Implementing quality control measures, such as data cleaning, verification, and validation, helps ensure the integrity and relevance of the data.
Choosing the right model architectures is crucial for achieving optimal performance. The architecture of an LLM determines its ability to understand and generate language effectively. Different architectures, such as transformers or recurrent neural networks, offer unique strengths and capabilities.
It is important to experiment with various architectures and select the one that best aligns with the specific language tasks and goals.
Iterative development and evaluation are key to refining and improving LLMs. This involves training and evaluating the model multiple times, considering feedback, and making necessary adjustments.
Regular evaluation against performance metrics and user feedback can help identify areas for improvement and ensure the model aligns with the desired objectives. By iteratively refining the LLM, developers can enhance its accuracy, fluency, and overall performance.
Suggested Reading:
Custom LLM Development: Build LLM for Your Business Use Case
As large language model (LLM) technology continues to evolve, the future holds exciting possibilities and opportunities. In this section, we will explore emerging trends and advancements in LLM technology, potential applications and impact in various industries, and the challenges and concerns that need to be addressed moving forward.
LLM development is an active area of research and innovation. Various trends and advancements are shaping the future of LLM technology. One notable trend is the move towards even larger and more powerful language models. Continued advances in computing infrastructure and training techniques enable the development of LLMs with enhanced capabilities and broader linguistic understanding.
Another emerging trend is the exploration of multimodal LLMs, which can understand and generate language in conjunction with other forms of media, such as images or videos. Integrating multiple modalities opens up new possibilities for LLMs to comprehend and generate context-rich and more immersive language.
Additionally, efforts are being made to address the ethical concerns surrounding bias in LLMs. Researchers and developers are exploring methods to reduce bias in training data and ensure fairness in language model outputs. Fairness-aware training approaches and bias detection techniques are being developed to mitigate the biases inherent in LLMs and promote more equitable language generation.
LLM technology has the potential to revolutionize a wide range of industries, offering innovative solutions and enhancing efficiency and productivity. In healthcare, LLMs can assist in medical transcription, patient diagnosis, and drug discovery research. They can help automate administrative tasks, improve patient engagement, and provide personalized healthcare recommendations.
In finance, LLMs can be utilized for sentiment analysis, automated risk assessment, and fraud detection. They can analyze vast amounts of financial data, identify patterns, and make data-driven predictions to support investment decisions and facilitate financial planning.
E-commerce stands to benefit from LLMs through improved customer service and personalization. LLM-powered chatbots can assist customers in finding products, answering queries, and providing tailored recommendations. Natural language processing capabilities enable seamless and intuitive interactions between customers and online platforms.
The education sector can leverage LLMs to enhance language learning, automated assessment, and personalized tutoring. LLM models can provide real-time feedback on written assignments, facilitate language translation, and deliver interactive learning experiences.
As LLM technology progresses, some important challenges and concerns must be addressed to ensure responsible and ethical use. Ongoing efforts are being made to improve the transparency and interpretability of LLMs, allowing users to understand how decisions and language generation are made. Open-source initiatives and collaborative research efforts promote the sharing and auditing of LLM models, fostering accountability and trust.
Ensuring the security and privacy of user data remains a crucial concern. Researchers and developers are developing privacy-preserving techniques that minimize the storage and processing of sensitive data while maintaining the utility of LLMs. Adherence to privacy regulations and implementing robust security measures are of utmost importance.
In conclusion, the field of LLM development in 2024 is witnessing rapid advancements and exciting possibilities. With larger models, multimodal capabilities, and ongoing efforts to address ethical concerns and biases, LLMs are poised to revolutionize healthcare, finance, e-commerce, and education industries.
However, to ensure responsible and ethical LLM development, it is crucial to navigate challenges related to transparency, privacy, and security. By fostering collaboration, enhancing interpretability, and adhering to legal and regulatory frameworks, we can harness LLMs' potential to reshape language interactions and unlock new opportunities in the coming years.
The future of LLM development is bright and holds immense potential for positive impact.
Suggested Reading:
How Large Language Models are Trained? A Complete Guide
LLMs are a type of AI that can process and generate human-like text. They're revolutionizing fields like customer service, marketing, and content creation due to their ability to handle complex language tasks.
Developing an LLM involves several steps, including data collection, pre-training, fine-tuning, and evaluation. The specific steps may vary depending on the desired application.
The most common LLM architecture is the transformer, but other architectures like recurrent neural networks are also used. Each architecture has its own strengths and weaknesses.
LLMs can be biased and generate harmful content if not carefully developed. It's important to consider ethical issues like fairness, accountability, and transparency throughout the development process.
LLMs are being used in a variety of applications, including chatbots, virtual assistants, machine translation, and content creation. As they continue to develop, we can expect even more innovative applications to emerge.
There are many resources available online and in libraries that can teach you more about LLM development. Some good places to start include research papers, blog posts, and online courses.
Subscribe to Our Newsletter
Get the latest business insights straight into your inbox.
Checkout our related blogs you will love.
Updated at Nov 5, 2024
11 min to read


Updated at Mar 5, 2024
13 min to read

Updated at Jul 3, 2026
15 min to read

Updated at Jul 3, 2026
10 min to read

Updated at Jul 1, 2026
16 min to read
Table of Contents