
Are you trying to decide between custom LLM models and pretrained models to solve your natural language processing problems? Look no further! In this blog post, we comprehensively analyse both approaches to help you make an informed decision.
We examine custom LLM models, their characteristics, benefits, and limitations. Then, we delve into pretrained models, discussing their features, advantages, and drawbacks.
Once we have explored both approaches, we compare them based on their performance, use case scenarios, and considerations for model selection.
This blog post is easy to read, with short sentences and paragraphs that eliminate all the fluff. We provide a direct, approachable, concise tone, without using corporate jargon or salutations.
If you want to make an informed decision when choosing between custom LLM models and pretrained models, this blog post is for you. It will take you through the entire analysis and provide valuable insights to help you choose the right model.
Custom LLM Models
Custom LLM models are powerful tools that enable businesses and researchers to develop machine learning models tailored explicitly to their needs.
These models are built from scratch and designed to understand and generate human language.
Their flexibility and tailor-made nature make them highly versatile in addressing unique problem statements.
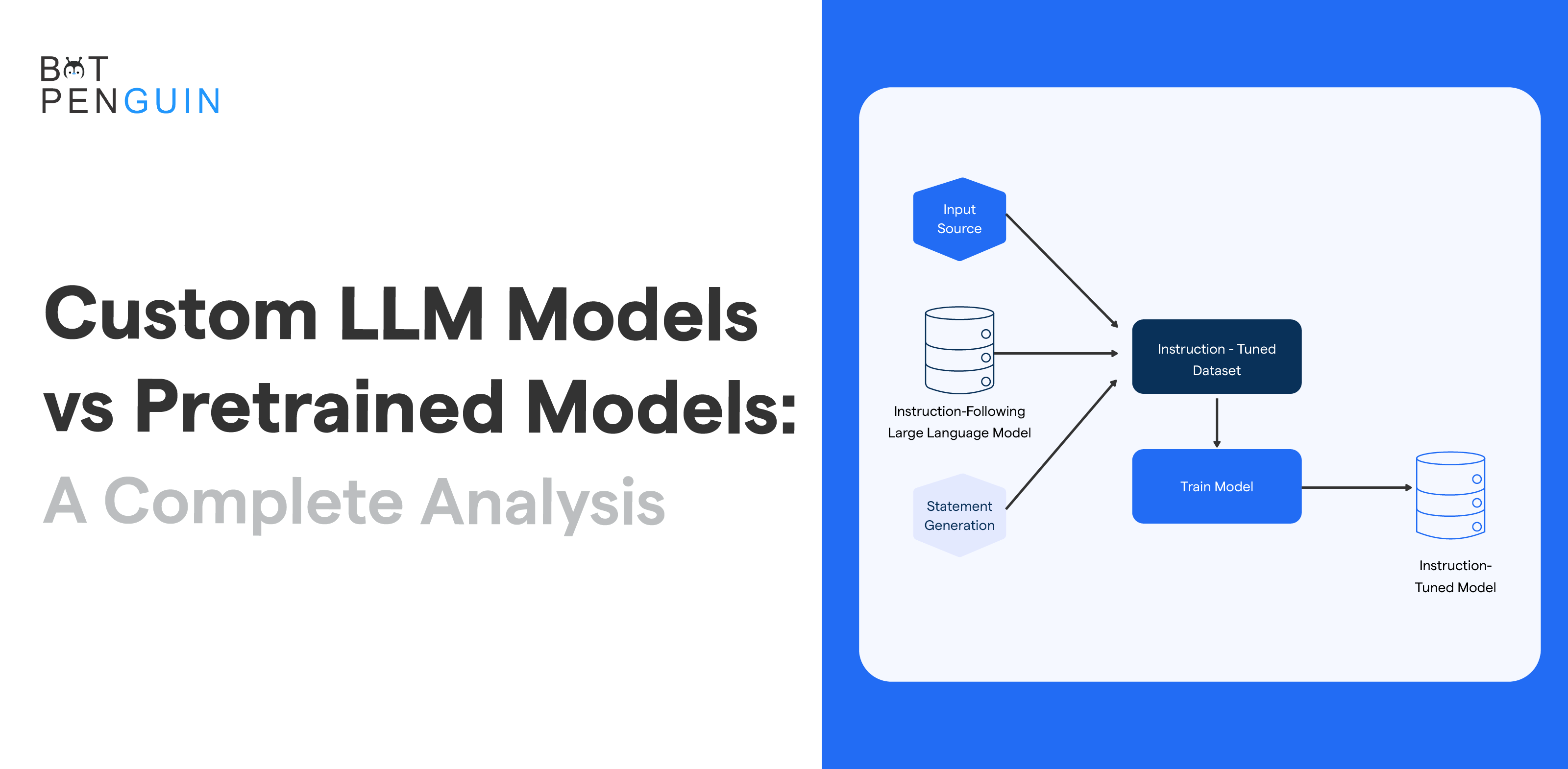
Characteristics of Custom LLM Models
Custom LLM models are language models trained on specific datasets to perform tasks related to natural language processing.
These models employ deep learning techniques, such as recurrent neural networks or transformers, to learn patterns, syntax, and semantics of human language.
These models become proficient in understanding and generating contextual information by training on domain-specific data.
Benefits of Custom LLM Models
Control over training data and model architecture: Custom LLM models allow users to curate and control the training data, ensuring that the model learns from relevant examples. Additionally, users can design the model architecture to suit their specific requirements.
Enhanced performance and accuracy: With customisation, LLM models can be fine-tuned to achieve high precision and superior performance in specific tasks. These models can capture nuances and produce more accurate outputs by training on domain-specific data.
Limitations of Custom LLM Models
Challenges like high development cost and time investment: Building a custom LLM model requires substantial resources in terms of time, computational power, and expertise. The development process involves data gathering, preprocessing, model training, and iterative optimization, which can be time-consuming and expensive.
Need for domain expertise: Building effective custom LLM models necessitates a deep understanding of both the domain and the intricacies of the underlying machine-learning techniques. Domain experts must ensure the model's relevance and effectiveness in real-world applications.
Custom LLM models offer the advantage of control and customization, allowing users to fine-tune the model architecture according to their needs. This leads to enhanced performance and accuracy.
Next, we will explore pretrained models.
Exploring Pretrained Models
Pretrained models are pre-trained on large-scale datasets and have become popular in various natural language processing tasks.
These models bring pre-existing knowledge to the table, making them a convenient option for many applications.
Characteristics of Pretrained Models
Pretrained models are language models trained on massive datasets such as Wikipedia, books, or web text. This initial training gives the models a "base" or general language understanding.
They are built using advanced techniques like transformers, which allow them to capture complex language patterns and semantics.
Advantages of Pretrained Models
Time-saving benefits and reduced resource requirements: Pretrained models eliminate the need to train a model from scratch, saving significant time and computational resources. These models are readily available and can be quickly fine-tuned for specific tasks.
State-of-the-art performance in various tasks: Pretrained models have demonstrated remarkable performance in various natural language processing tasks, including text classification, sentiment analysis, question-answering, and language translation. Leveraging their pre-existing knowledge allows for accurate results out of the box.
Limitations of Pretrained Models
Lack of customization and potential for biased outputs: Pretrained models are trained on diverse datasets ,and may, as a result, exhibit biases present in the training data.
Customizing these models to cater to specific requirements is limited, making it challenging to address certain niche tasks.
Compatibility issues and task-specific fine-tuning challenges: Pretrained models might not be compatible with all domains or tasks.
Adjustments and fine-tuning may be required to adapt them to specific scenarios, a complex process that demands expertise and additional effort.
Pretrained models offer the advantage of time-saving benefits and state-of-the-art performance in various tasks. Their pre-existing knowledge provides a significant head start.
However, it is important to consider the limitations of lack of customization and potential biases in outputs.
Compatibility issues and the need for fine-tuning for specific tasks should also be considered when deliberating on using pretrained models.
Next, we will compare both Custom LLM Models and Pretrained Models.
Suggested Reading:
Comparing Custom LLM Models and Pretrained Models
In comparing custom vs pretrained LLM models, it's essential to evaluate their strengths and weaknesses. This section will delve into the performance, use case scenarios, and considerations for selecting between these two approaches.
Performance Comparison
A language model's performance depends on various factors, including the amount and quality of training data, the model architecture, and fine-tuning techniques.
Custom LLM models, trained on domain-specific datasets, often excel in tasks that require a deep understanding of specific contexts.
They can capture nuances and intricacies more accurately. On the other hand, pretrained models, with their pre-existing knowledge, deliver impressive results out of the box in a wide range of tasks.
Case studies and examples from both approaches showcase their respective capabilities.
Use Case Scenarios
Custom LLM models are particularly beneficial in scenarios where domain-specific knowledge is crucial. They shine in finance, healthcare, and legal industries, where precise language understanding is essential.
For example, a custom LLM model trained on legal texts could provide accurate analysis and document summarization in the legal field. Pretrained models, on the other hand, are suitable when time and resource constraints are present.
They are ideal for general tasks like sentiment analysis, language translation, and text classification that do not require domain-specific expertise.
And, beginning with custom LLM development for your business need not be that tough. Meet BotPenguin, the home of AI-driven chatbot solutions
BotPenguin houses experienced developers with 5+ years of expertise who know their way around NLP and LLM bot development in different frameworks.
And that's not it! They can assist you in implementing some of the prominent language models like GPT 4, Google PaLM, and Claude into your chatbot to enhance its language understanding and generative capabilities, depending on your business needs.
- Hire ChatGPT Developers
- Custom ChatGPT Plugins
- Hire Chatbot Developers
- Custom Chatbot Development
- ChatGPT Clone
- ChatGPT Consultant
Considerations for Model Selection
When selecting between custom LLM models and pretrained models, several factors should be considered.
The availability of labeled data plays a significant role. A custom LLM model can provide a more tailored solution if a substantial amount of labeled data is available in the desired domain.
However, pretrained models offer a convenient alternative if labeled data is limited. Time constraints should also be considered since training a custom LLM model can be time-consuming.
Lastly, the desired outcomes and the specific task requirements must guide the decision-making process.
Conclusion
When it comes to custom vs pretrained LLM models, each presents its own set of strengths and considerations. Custom LLM models, specifically, afford users control, customization, and heightened accuracy by training on domain-specific data.
They are ideal for industries requiring precise language understanding, such as finance, healthcare, and law. However, building custom LLM models can be costly and time-consuming and requires domain expertise.
On the other hand, pretrained models save time and resources by leveraging pre-existing knowledge and delivering impressive results out of the box. They suit general tasks like sentiment analysis, language translation, and text classification.
However, they may exhibit biases from the training data and lack customization options, making them less suitable for niche tasks or specific requirements.
The availability of labeled data, time constraints, and task requirements should be considered when choosing between the two approaches. Custom LLM models provide a tailored solution with ample labeled data and specific domain expertise, while pretrained models offer convenience when labeled data is limited.
Suggested Reading:
Custom LLM Development: Build LLM for Your Business Use Case
Frequently Asked Questions (FAQs)
What distinguishes Custom LLM Models from Pretrained Models?
Custom vs pretrained LLM models offer distinct advantages. Custom LLM Models are tailored to specific needs, offering domain expertise, while Pretrained Models are generalized models trained on diverse data. Customization allows precise control over features, enhancing relevance in specialized tasks, whereas pretrained models provide a broader understanding but may lack specificity.
How does training data impact Custom LLM Models and Pretrained Models differently?
Custom LLM Models rely on domain-specific training data, ensuring relevance to specific industries. Pretrained Models, in contrast, learn from diverse datasets, potentially lacking domain expertise. This distinction influences the models' performance in specialized versus general contexts.
Can Custom LLM Models outperform Pretrained Models in specific applications?
Yes, Custom LLM Models excel in applications requiring domain expertise, providing better performance in industry-specific tasks. Pretrained Models, while versatile, may not offer the same level of precision in specialized domains, impacting their effectiveness in certain applications.
How does the adaptability of Custom LLM Models compare to that of Pretrained Models?
Custom LLM Models exhibit high adaptability to specific contexts, thanks to targeted training. Pretrained Models, though adaptable to various tasks, may struggle to match the nuanced understanding and relevance achieved by custom models in specific industries or domains.
What are the advantages of using Pretrained Models in terms of time and resources?
Pretrained Models offer a time-efficient solution by leveraging existing knowledge from extensive datasets, reducing the need for prolonged training. This can be advantageous when time and resource constraints are critical considerations, providing a quicker deployment option compared to customizing LLM Models.
How does the level of control differ between Custom LLM Models and Pretrained Models?
Custom LLM Models provide a higher level of control over features, allowing fine-tuning for specific requirements. In contrast, Pretrained Models offer less control over underlying structures, limiting customization. The choice between these models depends on the desired level of control in a given application.


