Introduction
Imagine stepping into a bustling kitchen where a master chef meticulously selects every ingredient to create a culinary masterpiece.
Just as this chef understands that every spice and herb adds a vital flavor, LLM developers carefully choose and prepare their data—the fundamental ingredient that powers intelligent, human-like language models.
But what’s the secret sauce behind creating an effective language model? It’s all in the data—the heart of LLM development. Data doesn’t just fuel these models; it shapes them, influencing their accuracy, depth, and ability to engage users meaningfully.
According to a recent report, the data used to train LLMs can account for up to 40% of a model's performance (McKinsey, 2023), highlighting just how essential high-quality data collection and preprocessing are.
In this article, we’ll uncover the essential ingredients for building powerful language models, from efficient data collection and rigorous preprocessing techniques to ethical considerations.
Join us as we explore the recipes for data-driven success in the world of LLM development and learn how to craft models that truly resonate with users!
Why Data Matters in LLMs?
When building LLM Development, data is the bedrock of success. The data used during the training process is critical because it directly influences the model's ability to understand and generate language.
A well-trained LLM not only makes accurate predictions but also delivers coherent and contextually relevant text. Simply put, high-quality data equals high-performing models.
Let’s delve into why data matters so much in LLM Development and how it impacts the model's overall quality.
How Data Impacts Model Quality and Performance
The quality, quantity, and diversity of data used in LLM Development determine the overall performance of the model.
If the dataset is biased, incomplete, or inconsistent, the resulting LLM will struggle with accuracy, leading to poor outcomes such as incorrect predictions or nonsensical text generation.
Conversely, a large, clean dataset ensures the model captures the complexity of human language, enabling it to produce more reliable and sophisticated text.
For example, consider an LLM development company building a legal language model. If the dataset primarily consists of U.S. legal cases, the model may struggle to generate accurate responses about laws in other countries.
By incorporating a diverse dataset with laws from multiple jurisdictions, the model becomes more versatile and performs better across different legal scenarios.
The Role of Diverse, High-Quality Data in Training LLMs
The importance of diverse, high-quality data cannot be overstated when it comes to LLM development services. Data diversity ensures that the model is exposed to multiple contexts, dialects, cultures, and scenarios, which makes it adaptable to a broader range of applications.
By including various data sources—news articles, academic papers, social media, and more—the LLM gains a comprehensive understanding of language and improves its real-world performance.
Leading LLM development companies often curate datasets to reduce bias, ensuring the model can operate ethically and fairly in diverse environments. For instance, an LLM trained in both male and female author-written content is less likely to produce gender-biased text.
Similarly, LLM development tools that support different data types—such as structured, unstructured, and semi-structured data—are essential to facilitate this high-quality training.
Real-World Example
OpenAI's GPT-3 model, a flagship example in the world of LLMs, was trained on an expansive dataset from diverse sources like books, websites, and even coding platforms.
This large and varied dataset allowed GPT-3 to generate human-like text across multiple industries, from healthcare to finance.
Companies offering LLM development services can take lessons from GPT-3’s training process to ensure their models perform well in varied, real-world scenarios.
By prioritizing diverse and high-quality data, LLM development tools can enable businesses to create models that meet their unique needs.
Types of Data for LLM Development
In LLM Development, the type of data used during training significantly influences the model's capabilities and overall performance.
Various data types make the models more flexible, enabling them to perform a wide range of tasks with improved accuracy.
Whether it's general text data, domain-specific content, or user-generated material, each data type plays a specific role in shaping the model’s abilities.
Below is a breakdown of the key data types used in LLM development.
Text Data: Books, Articles, and Web Content
Text data forms the backbone of most LLM Development projects. This includes data sourced from books, articles, blogs, and other web content. These resources help the model grasp fundamental language structures, idioms, and common expressions.
With the help of advanced LLM development tools, this data is processed to teach the model how to generate human-like responses. The richness and variety of the text allow the model to understand diverse contexts, enhancing its linguistic versatility.
For example, a leading LLM development company might use a large corpus of literature combined with news articles to create a model capable of answering questions about history, culture, or current events.
This foundational data is essential for most general-purpose LLMs, making it one of the most commonly used data types in LLM development services.
Domain-Specific Data: Legal, Medical, and More

For highly specialized industries like healthcare, law, and finance, domain-specific data becomes crucial.
This type of data includes legal documents, medical journals, financial reports, and technical manuals, which provide the model with the terminology, context, and precision required in these fields.
By incorporating domain-specific datasets, LLM development companies can create models that cater to specific professional needs, ensuring accuracy and reliability.
For example, a healthcare-focused LLM can be trained on medical records and research papers, allowing it to assist doctors by providing medical insights, diagnosing conditions, or summarizing research findings.
LLM development services that utilize domain-specific data lead to models tailored for niche sectors, enhancing their value in real-world applications.
User-Generated Content: Social Media, Forums, and Reviews
User-generated content from platforms like social media, online forums, and customer reviews is pivotal for models that need to understand colloquial language, trends, and opinions.
This type of data captures everyday language patterns, slang, and emerging trends, making the LLM more relevant in real-world interactions.
Many LLM development service providers rely on user-generated content to build models aimed at customer service, sentiment analysis, and marketing.
For example, a chatbot trained with user-generated content can assist e-commerce companies by understanding customer complaints, answering queries in casual language, or even detecting sentiment in product reviews.
By processing social media data, the LLM remains current and adaptable to changing language patterns.
Multilingual Data for Global Models
With the world becoming increasingly interconnected, training models on multilingual data is essential for global use. This data includes texts from multiple languages, allowing the model to cater to users from different linguistic backgrounds.
By incorporating multilingual datasets, LLM development service providers can build models that understand and generate text in various languages, thus expanding their usability.
A prime example is multilingual LLMs used by customer service teams to offer support in several languages, ensuring inclusivity and better communication with a global user base.
LLM development tools that facilitate multilingual training enable companies to create models that perform well across cultures and regions.
Real-World Example
Facebook’s AI research team developed M2M-100, a multilingual machine translation model that supports over 100 languages.
It was trained on a diverse dataset collected from various global sources, showcasing the value of multilingual data.
Similarly, LLM development services can leverage such approaches to build translation models, enhancing communication for businesses and users worldwide.
Effective Data Collection Strategies for LLM Development
Data collection is the cornerstone of LLM Development, directly influencing how well a model can understand, process, and generate language.
Employing effective data collection strategies ensures that the model is trained on a diverse and high-quality dataset, leading to better performance and real-world applicability.
Below are some of the most effective strategies for collecting data in LLM development.
Open-Source Datasets: Where to Find Reliable Datasets
Open-source datasets are one of the most accessible resources for LLM Development.
Platforms such as Kaggle, GitHub, and Google Dataset Search offer a wide array of public datasets, covering everything from general text data to domain-specific content like legal documents, medical records, and scientific papers.
To illustrate the process, let’s say an LLM development company is building a model focused on healthcare. The team could source medical datasets from open repositories like MIMIC-IV, which contains extensive de-identified healthcare data.
By combining this data with other text resources, the company can train its LLM to generate accurate and contextually relevant medical advice.
While open-source datasets are readily available, it's essential to carefully evaluate their quality, completeness, and relevance to ensure the model’s performance is not compromised.
Web Scraping: Tools and Techniques
Web scraping is an essential technique for collecting real-time data from the web, especially when public datasets are insufficient for specific needs in LLM development.
Tools like BeautifulSoup, Scrapy, and Selenium are popular scraping tools for automating the extraction of large volumes of textual data from websites. This method is invaluable for gathering dynamic, up-to-date content such as news articles, blog posts, or customer reviews.
For example, if a company providing LLM development services wants to build a model tailored to customer support, it can scrape FAQ pages, customer service transcripts, and product reviews to train the model on common user queries and responses.
However, developers must ensure that they follow ethical practices and scrape only publicly available information, respecting website terms of service.
Proper data cleaning and preprocessing are crucial steps after scraping to ensure the dataset is free from noise and ready for model training.
Crowdsourcing Data: Platforms and Approaches
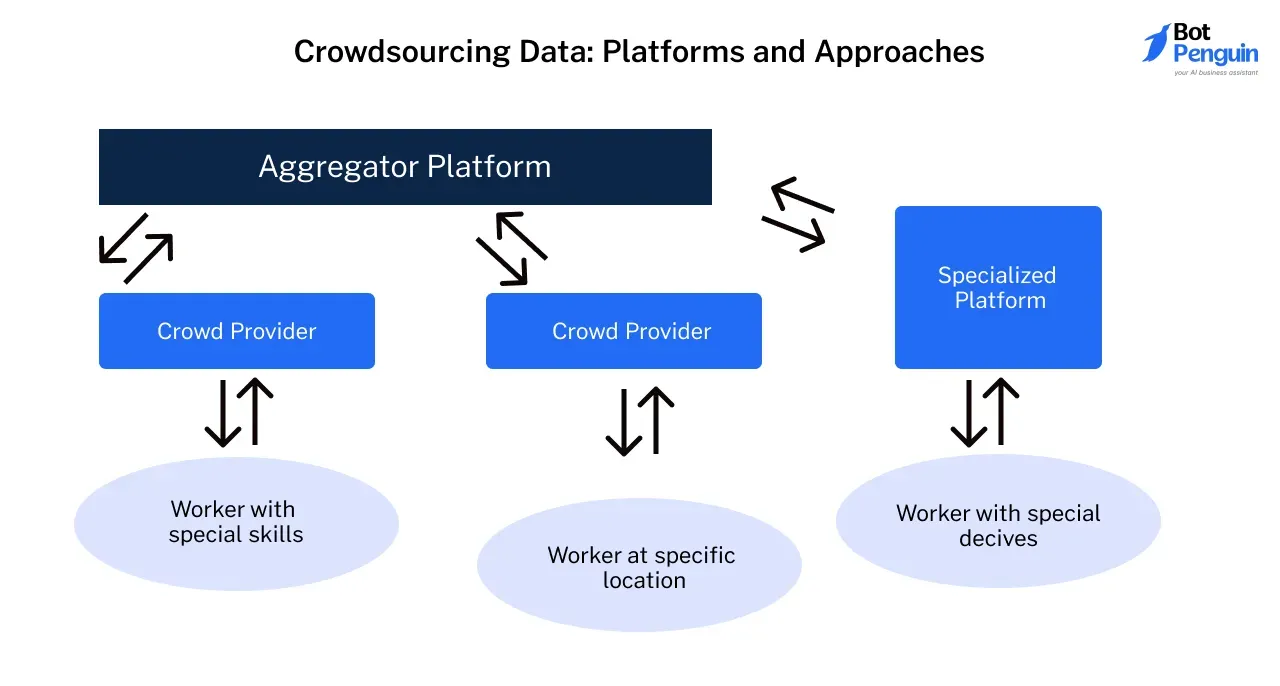
Crowdsourcing offers a unique way for LLM development services to gather diverse, user-generated content that reflects real-world interactions.
Platforms such as Amazon Mechanical Turk and Figure Eight allow companies to collect data like user sentiment, behavioral insights, or language preferences from a wide range of contributors.
For instance, an LLM development company building a chatbot for social media management might use crowdsourcing to gather user input on various conversational styles or customer complaints.
This crowdsourced data allows the model to stay relevant and adaptive to emerging trends and slang. The key benefit of crowdsourcing is the speed and scale at which data can be collected.
However, it is important to implement proper quality control mechanisms to ensure that the collected data is accurate, balanced, and free from bias.
Collaboration with Data Providers and Institutions

Collaborating with specialized institutions or data providers is a strategic approach for acquiring high-quality, domain-specific data, particularly for models that need industry-level expertise.
LLM development companies often partner with universities, hospitals, or legal organizations to gain access to proprietary datasets that are not available to the public.
For example, if a company is developing an LLM for the legal field, collaborating with a law firm or legal research institution can provide access to an exclusive set of legal case files, statutes, and precedents.
This type of collaboration ensures that the model is trained on accurate, up-to-date, and legally sound data, improving its ability to assist with legal research or drafting documents.
LLM development tools can then process this data to create a specialized model tailored to the intricacies of legal language, making it a reliable resource for professionals in the field.
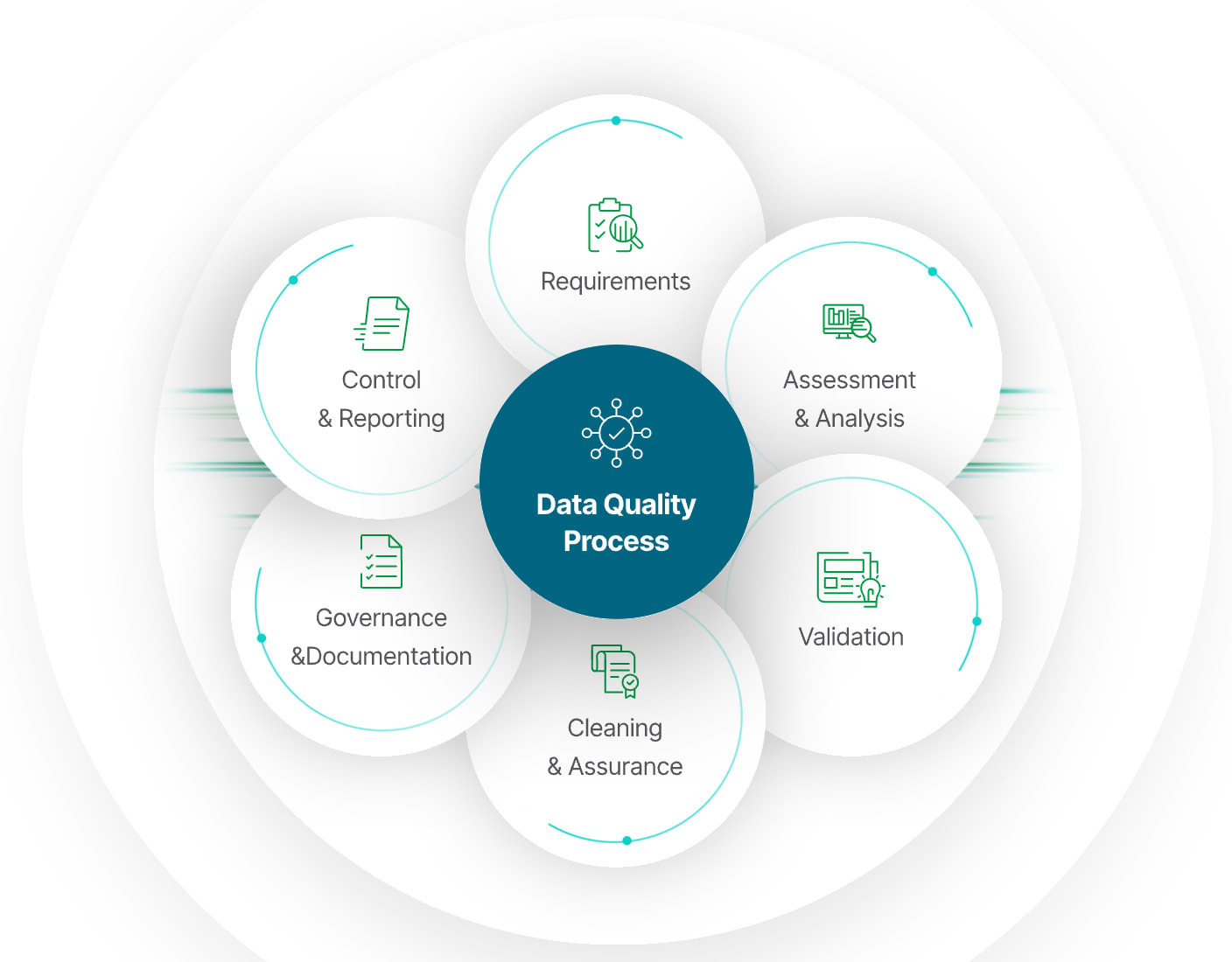
Ensuring Data Quality in LLM Development
In LLM Development, maintaining high data quality is vital to building models that are accurate, unbiased, and reliable. Poor-quality data can lead to faulty predictions and biased outputs, undermining the model's effectiveness.
To prevent these issues, it's important to apply rigorous data cleaning and management practices. Below are key strategies for ensuring data quality in LLM Development projects.
Clean, Structured Data vs. Unstructured Data
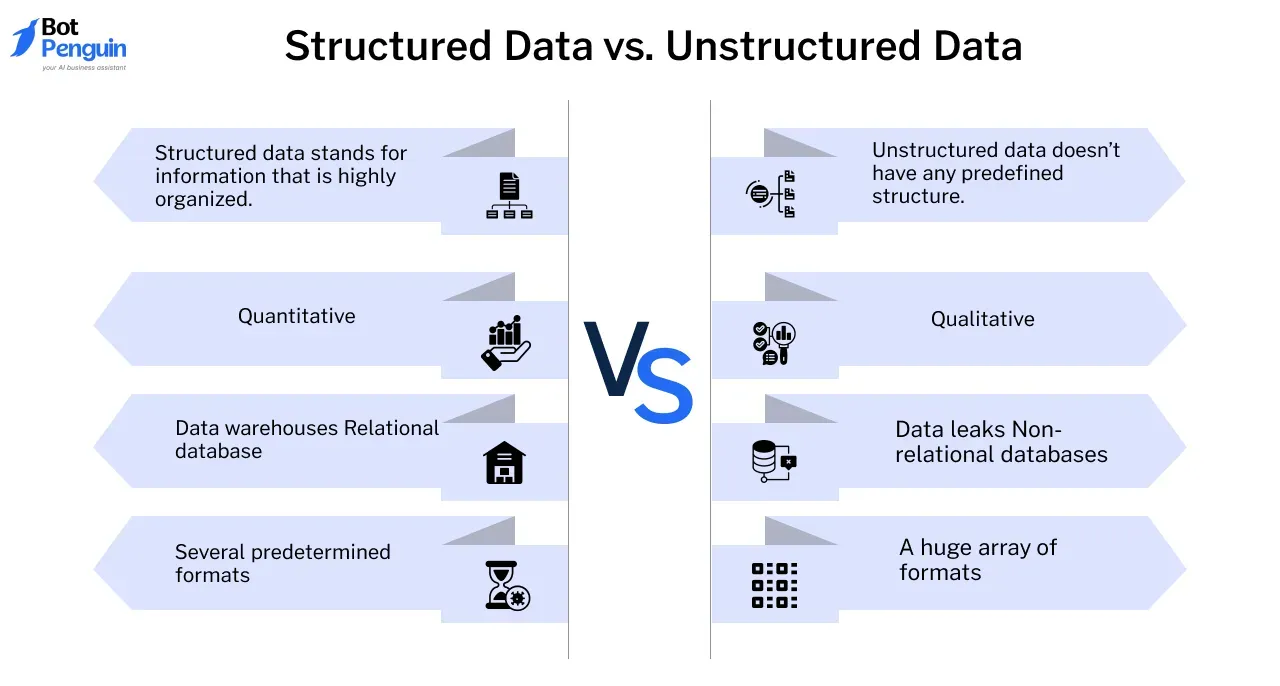
Clean, structured data is essential for efficient LLM Development. Structured data is well-organized and easily searchable, making it ideal for training language models.
It includes datasets like databases, spreadsheets, and well-tagged information, all of which simplify processing and improve model performance.
For example, an LLM development company creating a model for financial forecasting would rely on structured datasets like financial reports, stock data, and economic indicators, which are all labeled and organized.
However, unstructured data—such as text, images, or social media posts—also plays a crucial role. While unstructured data provides richer, more dynamic information, it requires extensive preprocessing to make it useful for the model.
LLM development tools can help convert unstructured data into a structured format through techniques like tokenization, annotation, and data labeling, ensuring it meets the quality standards necessary for model training.
Eliminating Bias in Data: Why It’s Crucial
Eliminating bias is one of the most important tasks during LLM Development. A biased model can generate skewed, unfair, or inaccurate results, leading to real-world consequences, especially in sensitive domains like healthcare, law, or finance.
For example, if a model used in hiring decisions is trained on biased data, it may inadvertently favor certain demographics over others.
To combat this, companies offering LLM development services focus on curating diverse datasets that represent a broad range of perspectives, languages, and demographics.
This reduces the risk of over-representation of any group and ensures the model's outputs are more balanced and fair.
Tools like fairness metrics and bias detection algorithms are commonly used to assess whether the data has inherent biases, enabling developers to refine the dataset before training begins.
Techniques for Filtering Noise and Irrelevant Information
In LLM Development, irrelevant or noisy data can significantly reduce the model's efficiency and accuracy. Noise refers to data that is redundant, inconsistent, or irrelevant to the task at hand.
Examples include typos, irrelevant web content, or spammy text from web scraping. Such data can confuse the model, leading to inaccurate predictions or irrelevant responses.
LLM development tools often use Natural Language Processing (NLP) algorithms to filter out noise and irrelevant information.
For instance, a company building a chatbot using an LLM might employ text preprocessing techniques like stop-word removal, stemming, or lemmatization to remove unnecessary parts of the text and focus on the relevant information.
This not only improves the model’s learning process but also reduces the time and computational resources required for training.
Handling Missing or Incomplete Data
Missing or incomplete data can disrupt the training process, potentially leading to gaps in the model's understanding.
Handling missing data effectively is crucial for ensuring consistency and accuracy during LLM Development. One common approach is data imputation, where missing values are replaced with estimates based on available data.
For instance, if an LLM development service is building a healthcare model and some patient records have missing data, imputation techniques like mean or median substitution, or more advanced methods like k-nearest neighbors (KNN) imputation, can be used to fill the gaps.
This ensures that the model receives a complete and coherent dataset, avoiding issues that could arise from incomplete information. By addressing these gaps, companies offering LLM development services ensure their models remain robust and capable of handling real-world scenarios.
Data Annotation and Labeling in LLM Development

In LLM Development, data annotation and labeling are pivotal, especially for supervised learning models.
Accurate labeling helps the model understand the relationship between input and output, enabling it to generate relevant and accurate responses.
Here's why labeled data is crucial and how it's managed efficiently in large-scale LLM projects.
Importance of Labeled Data for Supervised Learning
Labeled data serves as the backbone for supervised learning in LLM Development. It provides the model with specific examples of input-output pairs, allowing it to learn from these examples and make predictions.
LLM development companies recognize the importance of meticulously annotated data, as it directly impacts the performance of models in tasks like text generation, classification, and summarization. Well-labeled data helps models learn patterns, reducing errors and improving overall accuracy.
Tools for Automating Annotation

Annotating data manually can be labor-intensive, especially for large datasets. To streamline this process, LLM development tools like Prodigy and Labelbox automate the annotation process.
These tools help speed up the labeling process while ensuring precision, which is critical for training large-scale models. By automating annotation, LLM development services save time, reduce manual errors, and scale their projects efficiently.
Crowdsourcing Annotation for Large Datasets
For extensive datasets, crowdsourcing annotation tasks can be an efficient solution. Platforms like Amazon Mechanical Turk allow LLM development service providers to scale up data labeling by leveraging a large pool of workers.
Crowdsourcing is particularly beneficial for projects requiring diverse or context-specific annotations, such as sentiment analysis or domain-specific tasks.
By distributing the workload across multiple people, companies can speed up data labeling without compromising on quality.
Data Preprocessing Tips for LLM Development
Effective data preprocessing is vital to ensuring that the model can learn efficiently from the data.
Raw data often contains inconsistencies and noise that can hinder model performance, so proper preprocessing is key to building high-quality models in LLM Development.
Below are some essential tips for data preprocessing.
Tokenization: Breaking Text into Manageable Pieces
Tokenization is the process of breaking down large blocks of text into smaller, manageable units called tokens, such as words or subwords.
This is a foundational step in LLM Development that enables the model to process language more effectively.
Popular LLM development tools like SpaCy or NLTK can efficiently handle tokenization, ensuring that the model gets clear, understandable input.
Removing Duplicates and Redundant Data
Duplicate or redundant data can skew the training process, leading to inefficient or inaccurate models. LLM development services must identify and eliminate such data, focusing the model on unique and valuable inputs.
Automated tools can assist in detecting duplicates, improving the efficiency of the model's learning process, and enhancing performance.
Normalization: Ensuring Consistency in Formatting
Normalization involves converting data into a consistent format, such as standardizing text to lowercase or unifying punctuation styles.
Consistency is key in LLM Development, as inconsistent formatting can confuse the model and reduce accuracy.
Normalizing text ensures that the model isn't misled by trivial formatting differences, helping improve its ability to generate reliable responses.
Text Cleaning: Removing Irrelevant Characters and Symbols
Text cleaning involves removing irrelevant characters, symbols, or extra spaces to reduce noise in the dataset.
In LLM Development, this step is crucial for maintaining data quality, ensuring that the model only learns from clean, relevant inputs.
Cleaning text before feeding it into the model improves both the speed and accuracy of training.
Handling Special Characters and Encoding Issues
Special characters, such as emojis, accented letters, or symbols, can introduce challenges during training. Proper handling of these characters is essential to prevent errors in the LLM Development process.
Many LLM development companies use encoding techniques like UTF-8 to manage these issues efficiently, ensuring smooth data processing.
Ethical Considerations in Data Collection for LLM Development

Ethical considerations are critical in LLM Development, especially when it comes to data collection.
Adhering to ethical guidelines helps maintain fairness, transparency, and privacy, while also ensuring that the model remains compliant with legal standards.
Here's an overview of the key ethical aspects that companies must keep in mind.
Privacy and Consent: Importance in Data Collection
When collecting data for LLM Development, it's essential to prioritize user privacy and obtain explicit consent.
Users must be informed about how their data will be used, ensuring transparency throughout the data collection process. Every LLM development company should follow these best practices to maintain trust with users and avoid legal issues.
Suggested Reading:
Top 10 Best Tools for LLM Development in 2024
Avoiding Harmful Data (e.g., Misinformation, Hate Speech)
Harmful data, such as misinformation or hate speech, can significantly impair the model's outputs. To avoid generating biased or unethical content, LLM development services need to filter out harmful data.
This ensures that the model promotes fairness, generates accurate results, and avoids reinforcing negative stereotypes or misinformation.
Compliance with Data Protection Regulations (GDPR, etc.)
Compliance with data protection regulations like GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act) is a non-negotiable aspect of LLM Development.
These regulations outline how data should be collected, processed, and stored. Any LLM development service provider must ensure strict adherence to these rules to avoid penalties and ensure ethical data practices.
Best Practices for Data Storage and Management in LLM Development
In LLM Development, efficient data storage and management are crucial for ensuring seamless workflows and scalable operations.
Poor management can lead to delays, inefficiencies, and even errors in model training. Here are some best practices to optimize data storage and management:
Organizing Data for Easy Access and Processing
Organizing data systematically is essential to avoid chaos and inefficiency. A well-structured folder system, clear file naming conventions, and metadata tagging make it easy for teams to locate and process the data needed for model training.
For example, a folder structure might group data by categories like "Training Data," "Test Data," and "Evaluation Data," with subfolders indicating specifics like the data source or version.
This reduces time spent searching for files and ensures that LLM development tools can access the necessary data quickly and efficiently.
Scalable Storage Solutions: Cloud and On-Premise
As datasets grow in size, having a scalable storage solution becomes vital. Cloud-based storage, such as Amazon S3 or Google Cloud, is popular among LLM development services for its flexibility, scalability, and ability to handle large datasets without upfront hardware costs.
On-premise storage, on the other hand, offers more control over data security and is often preferred by companies handling sensitive data.
For instance, an LLM development company working with private or regulated data may opt for on-premise storage to maintain complete control while ensuring compliance with data protection standards.
Version Control for Datasets
In large-scale LLM Development projects, version control is critical to keep track of changes and updates to datasets. Tools like DVC (Data Version Control) allow teams to monitor dataset modifications, ensuring consistency across the model training process.
For example, if new data is added to a training set, version control helps ensure that all team members use the updated dataset, preventing issues such as model inconsistencies or errors.
Versioning also enables rollback to previous versions if needed, offering flexibility in managing large datasets.
Evaluating Data for Model Training
Data quality directly impacts the performance and reliability of LLMs. Evaluating the data before and during model training helps ensure that it meets the necessary quality standards.
Here are key approaches to evaluating data:
Techniques for Evaluating Data Effectiveness
One of the most effective ways to evaluate data quality is by using model performance metrics. Metrics like accuracy, precision, and recall give insights into how well the model is learning from the data during testing.
For example, if an LLM achieves high precision but low recall, it may indicate that the dataset lacks diversity or completeness in certain categories.
LLM development tools often provide built-in features to calculate these metrics, helping companies fine-tune their data and models for better results.
Balancing Quantity with Quality in Data Collection
In LLM Development, having large datasets is valuable, but data quality should never be compromised for quantity. Clean, diverse, and relevant data is crucial for building high-performance models.
For example, a model trained on a massive but unbalanced dataset (biased toward one category or language) may perform poorly on tasks requiring diversity.
A successful LLM development company focuses on gathering high-quality, well-annotated data that covers a broad spectrum of inputs, ensuring that the model can generalize well across different tasks.
Conclusion
As we wrap up our exploration of LLM development, it's clear that the journey from raw data to high-performing models is both intricate and rewarding.
By prioritizing data quality, effective annotation, and smart storage solutions, you can set your projects up for success.
In summary, ensuring data quality is a multi-step process that includes using structured data, eliminating bias, filtering noise, and addressing missing data. These steps are essential for developing accurate, reliable models that serve their intended purpose effectively.
Whether using LLM development tools or collaborating with LLM development companies, these best practices help create models that are not only high-performing but also ethical and trustworthy.
Remember, it’s not just about gathering large amounts of data; it’s about ensuring that data is clean, relevant, and diverse. Embracing automated tools can lighten your workload and streamline processes, allowing you to focus on innovation.
As you navigate this exciting field, keep in mind that each step in your data strategy contributes to the overall performance of your models.
With the right practices in place, you can create LLMs that truly understand and resonate with users. So, let’s commit to excellence in every aspect of data management and make a meaningful impact in the world of AI together!
Frequently Asked Questions (FAQs)
What is the role of data in LLM Development?
Data plays a vital role in LLM development as it serves as the foundation for training the model.
High-quality, diverse datasets help the model learn patterns in language, enabling it to generate accurate and relevant responses across various tasks.
Why is data preprocessing important in LLM Development?
Data preprocessing is essential because it cleans and organizes raw data, enhancing the model's accuracy.
This step involves techniques like tokenization, normalization, and removing irrelevant information, ensuring the model learns from structured and high-quality data.
What are the best practices for data collection in LLM Development?
Best practices for data collection include utilizing open-source datasets, ethically web scraping, crowdsourcing data, and collaborating with trusted data providers.
These strategies help ensure the data's quality, which is crucial for building reliable language models.
How do you ensure data quality for LLMs?
Ensuring data quality involves removing duplicates, addressing missing data, eliminating bias, and maintaining clean, structured datasets.
High-quality data directly contributes to the accuracy and reliability of the language models.
What tools are used for data annotation in LLM Development?
Tools such as Prodigy and Labelbox are commonly used to automate data annotation.
These tools streamline the labeling process, allowing for the efficient creation of high-quality training data, which is critical for improving model performance.
Why is ethical data collection important in LLM Development?
Ethical data collection is crucial for protecting user privacy, avoiding harmful content like misinformation, and ensuring compliance with regulations such as GDPR.
By prioritizing ethics, LLM development companies can maintain trust and uphold the integrity of their models.