Introduction
In a world where communication is evolving faster than ever, large language models (LLMs) stand at the forefront of this transformation, bridging gaps and facilitating connections in ways we once thought impossible.
Imagine a tool so powerful that it can draft emails, generate creative content, and even engage in human-like conversations—all at lightning speed. This isn’t a scene from a sci-fi movie; it’s the reality of LLM development.
But how does one create such an incredible tool? The answer lies in the architecture behind it. Choosing the right LLM architecture is like selecting the blueprint for a skyscraper; every decision impacts the structure's strength and functionality.
In this blog, we’ll delve into the key factors that make up effective LLM development architecture, from the importance of high-quality data to the nuances of model size and complexity.
Whether you’re an aspiring developer or just intrigued by the magic behind these models, come along as we unpack the essential elements of successful LLM development!
Understanding Model Architectures in LLM Development
Selecting the right model architecture is the foundation of successful LLM development. The structure of the model not only dictates its ability to process data but also influences how well it learns patterns and generates meaningful text.
Different architectures are suited for various tasks, making it crucial for LLM product development to understand these nuances.
Neural Networks: The Building Blocks of LLM Development Architecture
Neural networks are fundamental to machine learning, designed to mimic the way the human brain processes information.
Several types of neural networks have evolved, each catering to the complexities of data, especially in LLM development.
Feedforward Neural Networks
Feedforward networks represent the simplest form of neural networks, where information flows in one direction—from input to output.
While effective for basic tasks, they struggle with sequential data like text, rendering them less suitable for LLM architecture.
The lack of memory means they cannot retain context across longer sequences, limiting their applicability in LLM development.
Recurrent Neural Networks (RNNs)
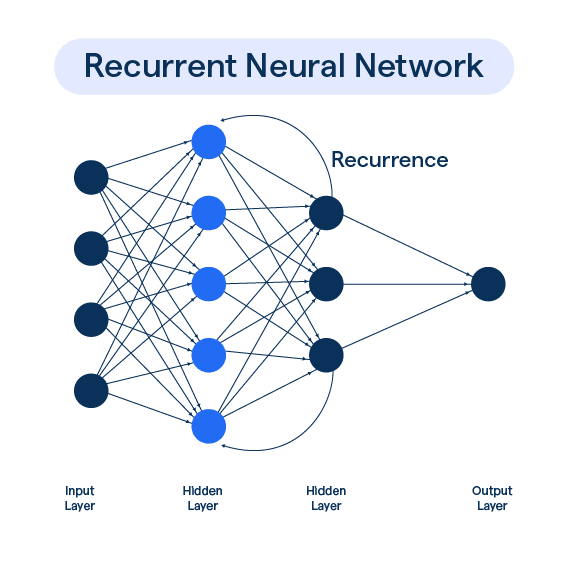
RNNs introduce memory into the equation, processing data sequentially and allowing the model to remember previous inputs, thereby enhancing context understanding.
This makes RNNs more adept for language tasks in LLM architecture.
Long Short-Term Memory (LSTM) Networks
LSTMs are a significant advancement over standard RNNs, equipped with mechanisms to store information for extended periods.
This capability makes them particularly effective for tasks that require long-term dependency handling in text, making them a staple in large language models or LLM development.
Gated Recurrent Units (GRUs)
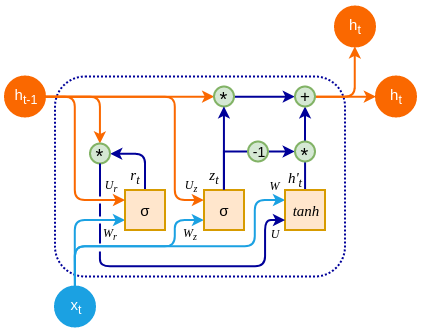
GRUs streamline the LSTM architecture by reducing the number of gates, leading to faster training while maintaining memory.
Their efficiency makes GRUs increasingly popular in LLM development.
Transformer Architectures: A Revolution in LLM Development
Transformers have transformed LLM development by overcoming the limitations of RNNs and LSTMs.
Their capacity to manage long-range dependencies and facilitate parallel processing has established them as the go-to architecture for modern LLM development.
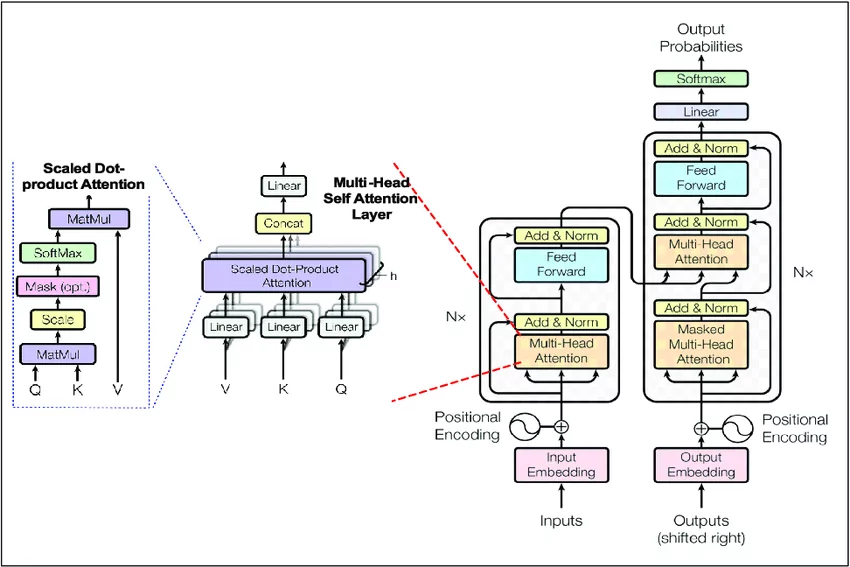
Self-Attention Mechanism
At the heart of transformers lies the self-attention mechanism, which allows models to focus on various parts of the input sequence simultaneously.
This ability to capture relationships across vast distances in text significantly enhances context understanding, making transformers essential in best practices for LLM development.
Encoder-Decoder Architecture
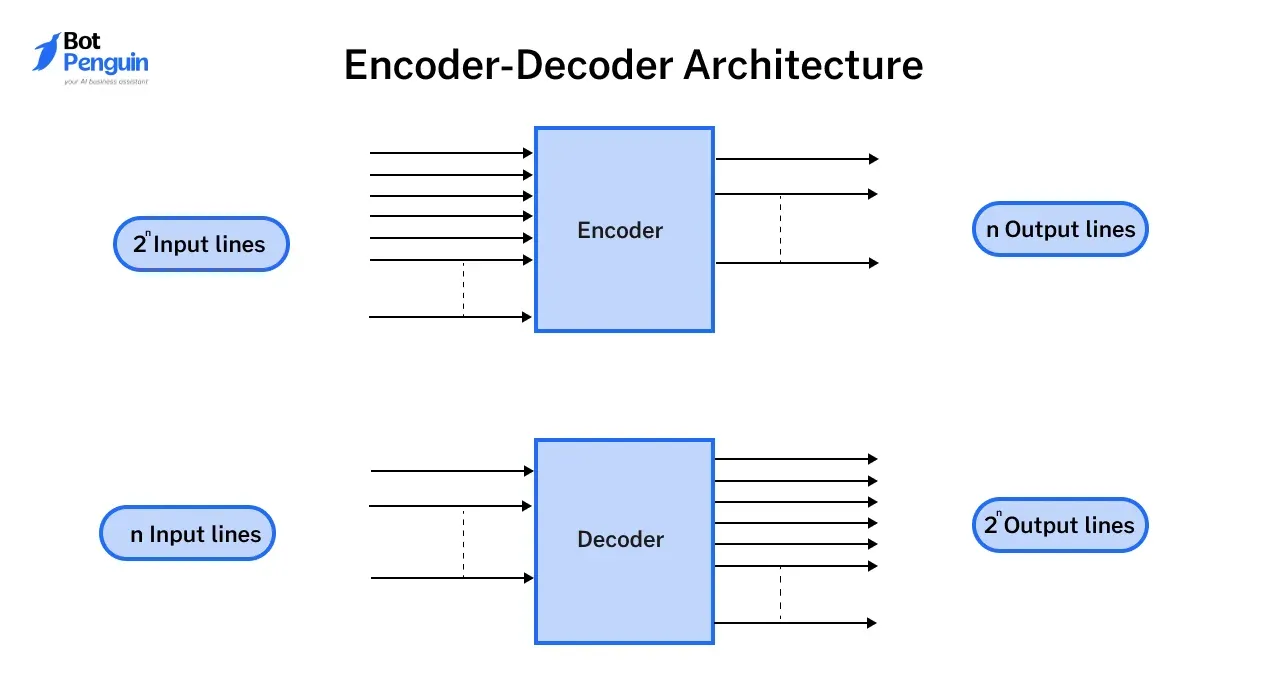
The encoder-decoder setup is a powerful framework in which the encoder processes the input, while the decoder generates the output. This architecture excels in tasks like machine translation and summarization, where input and output formats may differ.
Understanding LLM architecture through the lens of encoder-decoder systems illustrates how transformers achieve superior speed and accuracy compared to their predecessors.
Benefits of Transformers for LLM Development
Transformers bring multiple advantages to LLM product development. They manage large datasets efficiently, process sequences in parallel, and effectively capture relationships in extensive text data.
For any LLM development company, utilizing transformers translates into faster training times and more accurate outcomes, making them the optimal choice for contemporary applications.
5 Key Factors to Consider in Model Design for LLM Development

Designing an effective model for LLM development extends far beyond merely selecting the right architecture. Numerous factors contribute to the success of a large language model (LLM).
In this section, we will delve into the most critical factors to consider in model design to ensure optimal performance and scalability for your LLM development.
1. Data Quality and Quantity
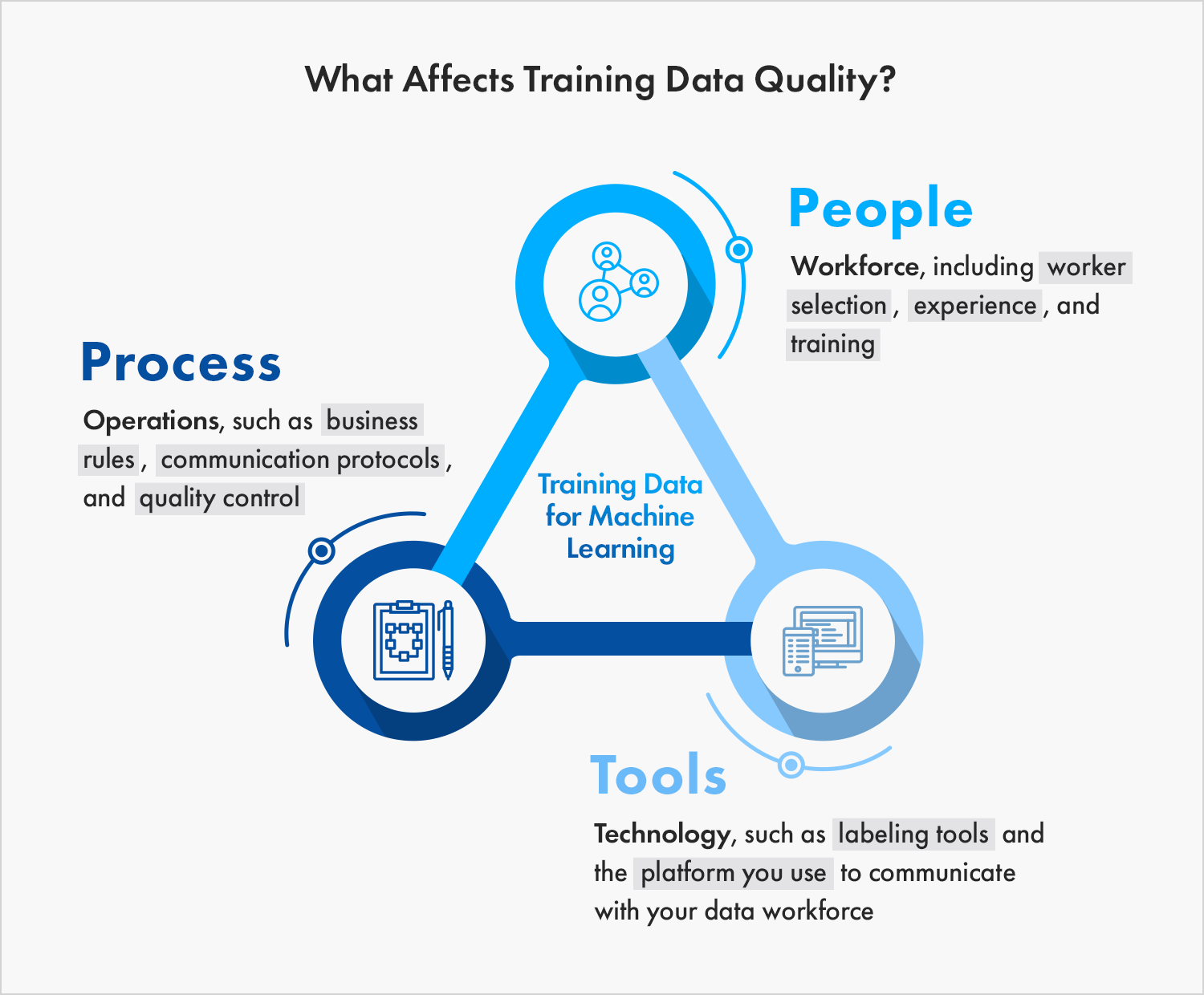
Data serves as the backbone of any effective model. The quality and quantity of data are paramount for successful LLM development.
Importance of High-Quality Training Data
In the realm of best practices for LLM development, the quality of your training data significantly impacts the model’s performance.
High-quality, relevant data enables the model to understand context and deliver more accurate predictions.
Data Preprocessing and Cleaning
Before training, robust data preprocessing and cleaning are essential. This involves addressing missing values, correcting errors, and transforming raw data into a usable format.
Proper preprocessing mitigates biases and ensures that your model is not learning from flawed information, which is crucial for effective LLM development architecture.
Data Augmentation Techniques
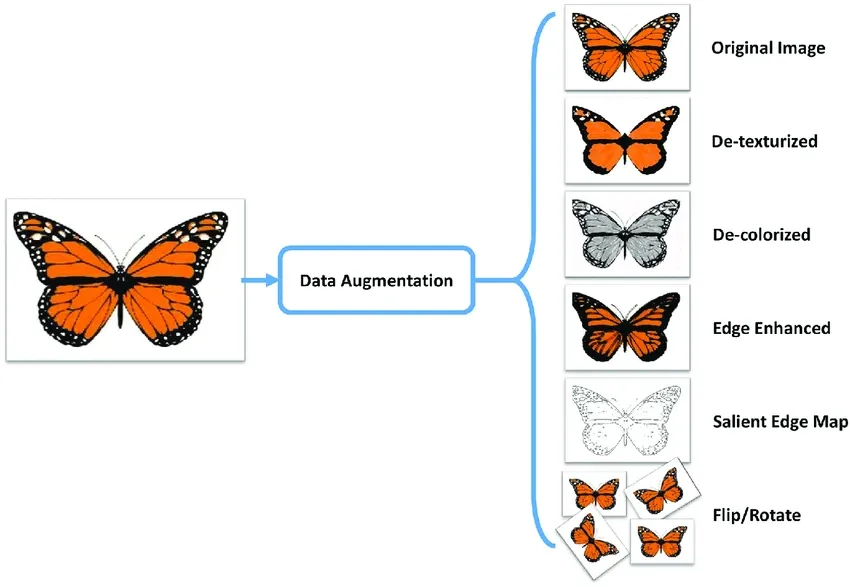
To enhance model generalization, consider employing data augmentation techniques.
By creating new training examples from existing data—such as by adding noise or making slight modifications—you can help your model handle variations in language and prevent overfitting.
2. Model Size and Complexity
Striking the right balance between model size and complexity is vital to avoid inefficiencies in LLM development.
Trade-off Between Model Size and Performance
While larger models can capture more complex patterns and nuances, they require significantly more computational resources and longer training times.
In LLM architecture explained, this trade-off becomes evident: a larger model might yield better results, but impractical resource requirements can stifle progress.
Computational Resources and Scalability
When designing your model, it is crucial to assess the computational resources at your disposal. Scalability is key in LLM product development, especially when managing large datasets or training on distributed systems.
Efficient architectures and techniques, such as model parallelism, can help you achieve desired performance levels without overwhelming your infrastructure.
3. Hyperparameter Tuning

Proper hyperparameter tuning can significantly enhance model performance in LLM development.
Learning Rate, Batch Size, Number of Epochs
Key hyperparameters such as learning rate, batch size, and the number of training epochs require careful tuning.
The learning rate determines the speed at which the model learns, while batch size influences training stability.
Grid Search and Random Search Methods
Two common approaches for hyperparameter tuning are grid search and random search.
Grid search systematically evaluates all combinations of hyperparameters, while random search samples random combinations.
4. Regularization Techniques
Regularization techniques are essential for preventing overfitting, ensuring the model generalizes well to new data in LLM development.
L1 and L2 Regularization

L1 and L2 regularization adds penalties to the model’s loss function, discouraging overly complex models.
L1 regularization promotes sparsity by eliminating unnecessary parameters, while L2 regularization encourages smaller weights. Both methods enhance model generalization and contribute to the reliability of LLM development architecture.
Dropout and Early Stopping
Dropout is a regularization technique that randomly deactivates neurons during training, preventing the model from becoming overly reliant on specific features.
Early stopping halts training when the model's performance on validation data ceases to improve, further mitigating the risk of overfitting and enhancing model stability.
5. Loss Functions
Choosing the right loss function is a pivotal decision in LLM development that directly influences the model’s training efficacy.
Cross-Entropy Loss
Cross-entropy loss is widely utilized in classification tasks, particularly in language models.
It quantifies the difference between the predicted probability distribution and the true distribution, guiding the model to refine its predictions over time.
Mean Squared Error (MSE)
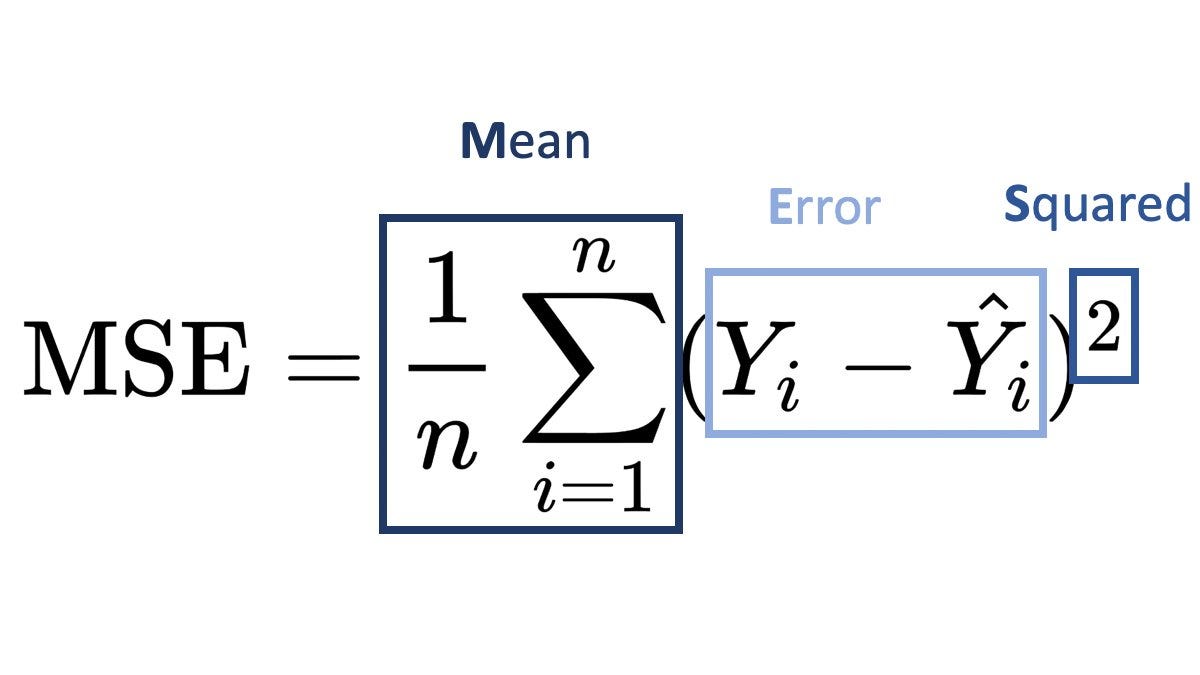
While not commonly used in language models, mean squared error (MSE) is applicable in regression tasks and evaluates the average squared difference between predicted and actual values.
Custom Loss Functions
For specialized tasks in LLM product development, creating custom loss functions allows for tailored optimization, providing greater flexibility in addressing unique requirements.
This approach is particularly advantageous for LLM development companies aiming to innovate in niche markets.
Common LLM Architectures

In this section, we will explore some of the most common architectures used in LLM development and their applications.
GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is one of the most recognized architectures in LLM development.
Key Features and Capabilities
GPT-3 is based on a transformer architecture and is specifically designed for generating human-like text.
With a staggering 175 billion parameters, it can handle a diverse range of tasks—from language translation to code generation—without requiring fine-tuning. Its ability to excel at zero-shot and few-shot learning enables it to perform effectively with minimal context or examples.
Applications and Use Cases
Common applications of GPT-3 include content creation, chatbot development, and virtual assistants. Its versatility also extends to coding assistants and answering complex questions across various industries.
GPT-3 has become a go-to model for many large language models (LLM) development companies, owing to its ability to generate coherent and contextually relevant text.
BERT

BERT (Bidirectional Encoder Representations from Transformers) marked a significant advancement in LLM architecture, introducing the concept of bidirectional learning.
Bidirectional Learning
Unlike GPT-3, BERT employs bidirectional training, meaning it considers the context from both sides of a word in a sentence.
Applications in Natural Language Understanding
BERT is widely utilized in various tasks such as question answering, sentiment analysis, and natural language understanding.
Its bidirectional nature makes it ideal for applications where context is paramount, establishing it as an essential model in best practices for LLM development.
T5
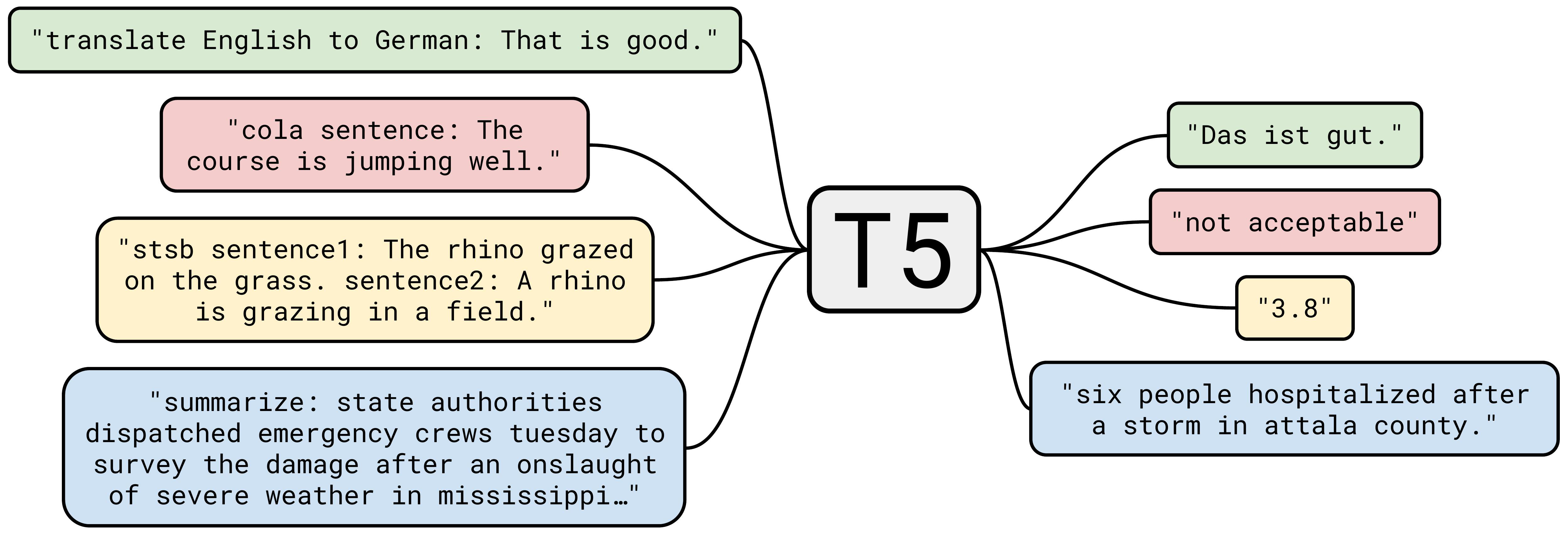
T5 (Text-to-Text Transfer Transformer) takes a distinctive approach to LLM development by framing every task as a text-to-text problem.
Text-to-Text Framework
T5 treats all tasks—ranging from translation to summarization—as variations of text-to-text tasks.
This simplification allows for a highly adaptable architecture that can easily accommodate multiple types of natural language processing tasks.
Multi-Task Learning Capabilities
T5's proficiency across various tasks makes it a powerful tool for LLM product development.
Its ability to seamlessly switch between different tasks positions it as an ideal candidate for multi-task learning scenarios.
Other Notable Architectures
Several other architectures have emerged, each with its own advantages in LLM development.
- RoBERTa: This model builds on BERT by optimizing its training process, resulting in superior performance on various benchmarks. It enhances robustness and efficiency, making it a strong contender in LLM development for products.
- XLNet: XLNet improves upon the pretraining process by capturing bidirectional context while addressing the limitations of BERT, providing a more comprehensive understanding of language context.
- ALBERT: ALBERT (A Lite BERT) is a streamlined version of BERT, reducing model size while preserving performance. This makes it more scalable and efficient for LLM product development, especially in resource-constrained environments.
Model Evaluation and Testing
In LLM development, evaluating and testing models is crucial to ensure they perform effectively in real-world applications.
In this section, we’ll cover key evaluation metrics, testing methods, and the importance of monitoring models after deployment in LLM product development.
Evaluation Metrics
Metrics are essential for quantifying a model's performance in large language model or LLM development.
BLEU, ROUGE, METEOR
Commonly used metrics include BLEU, ROUGE, and METEOR.
These metrics assess the quality of machine-generated text by comparing it to human-written reference texts, helping to gauge the model’s accuracy in tasks like translation and summarization.
Human Evaluation
While automatic metrics are useful, human evaluation remains vital for assessing language fluency, relevance, and creativity.
This is particularly important for models designed for conversational or creative tasks within LLM architecture.
Model Testing and Validation
Proper testing ensures that your model generalizes well and performs consistently across different scenarios.
Holdout Validation
Holdout validation involves splitting the dataset into training and testing subsets.
This approach ensures that the model’s performance is evaluated on unseen data, providing a clearer picture of how it will perform in real-world applications.
Cross-Validation
By training and testing the model on different subsets, cross-validation helps mitigate overfitting and enhances the model's generalization capabilities, making it a key part of best practices for LLM development.
Model Deployment and Monitoring
Post-deployment monitoring is essential for ensuring sustained performance in LLM product development.
Considerations for Production Environments
Before deploying a model, developers must ensure it meets the computational and performance requirements of production environments.
This includes evaluating latency, scalability, and resource allocation to ensure the model can handle real-time requests and workloads effectively.
Model Performance Monitoring
Once deployed, models must be continuously monitored for performance issues.
This includes tracking accuracy, efficiency, and user feedback to ensure the model maintains its performance over time.
BotPenguin in Selecting Model LLM Architecture & Design
BotPenguin excels in selecting and implementing the ideal model architecture and design for Large Language Models (LLMs), ensuring smooth integration into existing workflows.
Integrating custom LLMs can be challenging, often requiring custom development solutions tailored to the specific business use case. BotPenguin’s team of NLP and LLM experts, with over five years of experience, are skilled in building and deploying LLM-based chatbots across various frameworks.
By carefully designing LLM architectures to suit each project, BotPenguin enhances chatbots’ language understanding and generative capabilities, empowering them to analyze conversations in real time, respond empathetically, and continue from previous interactions.
BotPenguin’s expertise ensures that each model is seamlessly woven into the chatbot’s functionality, delivering a more dynamic, responsive, and human-like experience.
Conclusion
In conclusion, it’s clear that selecting the right model architecture and design is crucial for success. From choosing high-quality data to implementing robust preprocessing techniques, every step matters in crafting effective language models.
With popular architectures like GPT-3 and BERT, you have powerful tools at your disposal, but understanding their strengths is key to unlocking their potential.
Rigorous evaluation methods, including metrics like BLEU and ROUGE, alongside human assessments, help ensure your models are ready for real-world challenges.
And let’s not forget about the importance of ongoing monitoring after deployment; this ensures your models stay relevant and accurate as user needs evolve.
By embracing these best practices, you can create innovative LLM development products that truly resonate with users, making a meaningful impact in the realm of natural language processing. The future of LLMs is bright, and you’re well-equipped to be a part of it!
Frequently Asked Questions (FAQs)
What factors should be considered when selecting an LLM architecture?
Key factors to consider include model size, data quality, computational resources, task requirements, and scalability to ensure optimal performance in LLM development.
How do transformers improve LLM performance?
Transformers enhance LLM performance by effectively handling long-range dependencies, processing sequences in parallel, and scaling efficiently, making them ideal for modern LLM development.
What is the difference between RNNs and transformers in LLMs?
RNNs process data sequentially, while transformers leverage parallel processing and self-attention mechanisms, making them significantly more efficient for large-scale LLM development.
Why is data preprocessing important in LLM architecture design?
Data preprocessing is vital in LLM architecture design as it ensures clean, high-quality input, reducing biases and enhancing the accuracy and efficiency of LLM development models.
How does model size affect performance in LLM development?
Larger models can capture complex patterns but require more computational resources, emphasizing the importance of balancing size and efficiency in LLM architecture.