Get ready to dive into the battle of the language models! In this blog, we'll explore the key differences between two titans of the natural language processing world: BERT LLM and GPT-3.
These powerful models have revolutionized how we understand and generate language, but they approach the task in distinct ways.
First, we'll unravel the secrets of BERT LLM, a bidirectional transformer model that excels at understanding context and linguistic patterns. From question answering to sentiment analysis, BERT LLM has proven its mettle across various tasks.
Then, we'll journey into the realm of GPT-3, a generative language model that can create stunningly human-like text. With its impressive language fluency and generation capabilities, GPT-3 has found applications in virtual assistants, content creation, and more.
But that's not all! We'll also delve into the architectural differences between these models, their training data, and their performance accuracies. Get ready to discover the strengths, limitations, and real-world applications of these language processing powerhouses.
Intrigued? Keep reading to uncover the fascinating insights behind BERT LLM and GPT-3 – and decide which one reigns supreme in your book!
BERT LLM
BERT (Bidirectional Encoder Representations from Transformers) is a popular language model developed by Google.
It has revolutionized the field of natural language processing (NLP) by introducing a groundbreaking approach to understanding language.
BERT model nlp is a transformer-based model that utilizes bidirectional training to capture the context and meaning of words in a text.
Key features and strengths of BERT LLM
BERT LLM (Language Model Masking) is an extension of BERT that focuses on improving language modeling tasks.
The key features of BERT model nlp include its ability to handle varied sentence lengths, model dependencies between words effectively, and understand complex linguistic patterns.
Due to its contextual understanding, the BERT model nlp also excels at tasks such as named entity recognition, question answering, and sentiment analysis.
Applications and use cases of BERT LLM
BERT LLM has found extensive applications across various domains.
It is widely used to develop chatbots and virtual assistants to enhance language comprehension and response generation capabilities.
BERT LLM is also utilized in sentiment analysis to analyze and understand the sentiment expressed in customer reviews, social media posts, and other text data.
Furthermore, it plays a crucial role in machine translation and information retrieval systems, improving their accuracy and performance.
Next, we will cover GPT3.
Try BotPenguin
GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is a cutting-edge language model created by OpenAI.
Its remarkable ability to generate human-like text and comprehend complex language structures has gained significant attention.
GPT-3 is a massive transformer-based model trained on an extensive dataset to learn human language's statistical patterns and nuances.
Key Features and Strengths of GPT-3

GPT-3 presents several key features and strengths that set it apart in language modeling.
It can generate coherent and context-aware text, making it highly useful for tasks such as article writing, poetry generation, and content creation.
GPT-3 showcases impressive language fluency and can effectively understand and respond to user queries, enabling it to excel in conversational AI applications.
Applications and Use Cases of GPT-3
The versatility of GPT-3 has led to its adoption in numerous domains.
It is utilized in virtual assistants for natural and interactive conversations. GPT-3's language generation capabilities have found applications in chatbots that provide personalized responses to user queries.
Furthermore, GPT-3 is employed in content creation tasks like writing blog articles or summarizing text.
It has also been used in academic research for automatic text completion and natural language understanding tasks.
Now, if you want to begin with customized GPT solutions for your business, then Meet BotPenguin, the home of AI-driven chatbot solutions.
BotPenguin houses experienced ChatGPT developers with 5+ years of expertise who know their way around NLP and LLM bot development in different frameworks.
And that's not it! They can assist you in implementing some of the prominent language models like GPT 4, Google PaLM, and Claude into your chatbot to enhance its language understanding and generative capabilities, depending on your business needs.
- Whitelabel ChatGPT
- Hire ChatGPT Developers
- Custom ChatGPT Plugins
- ChatGPT Clone
- ChatGPT Consultant
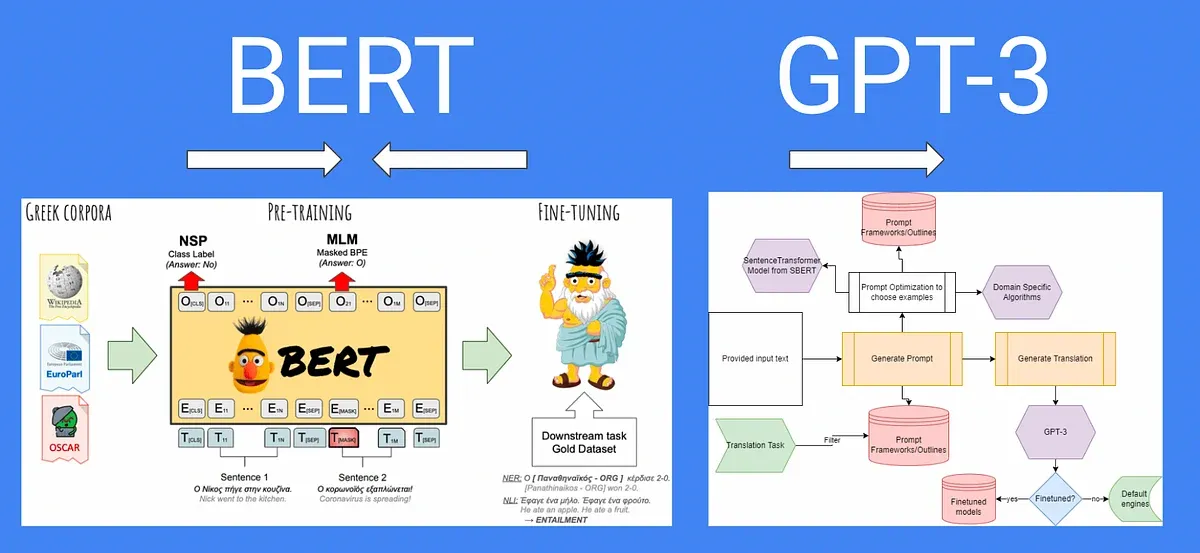
BERT LLM vs GPT-3: Comparison of Architectures
BERT LLM and GPT-3 are two widely used architectures in natural language processing.
While both models excel in understanding and generating text, their underlying architectural designs differ.
BERT LLM, short for Bidirectional Encoder Representations from Transformers with Language Model Masking, is a transformer-based architecture that combines bidirectional training with a masked language modeling objective.
It uses a masked language modeling task to learn word representations in a potentially bidirectional context.
On the other hand, GPT-3, or Generative Pre-trained Transformer 3, is a state-of-the-art autoregressive language model.
Unlike BERT model nlp , GPT-3 does not rely on bidirectional training. Instead, it focuses on generating text by predicting the next word in a sentence based on the preceding context.
Focus on Pre-training and Fine-Tuning Approaches
Both BERT LLM and GPT-3 employ pre-training and fine-tuning approaches to achieve their impressive language understanding and generation capabilities.
Pre-training involves training the models on a large corpus of unlabeled text. The models learn linguistic patterns, context, and semantic relationships during this phase.
BERT model nlp uses the masked language modeling objective, in which certain words are masked and the model has to predict them. GPT-3, on the other hand, uses a left-to-right autoregressive objective, predicting the next word in a sequence.
The subsequent phase involves fine-tuning the models using labeled data for specific downstream tasks. This step allows the models to specialize in sentiment analysis, text classification, or question-answering tasks.
Impact of Architecture on Performance and Flexibility
The choice of architecture significantly impacts the performance and flexibility of the models.
BERT LLM's bidirectional training enables it to capture contextual information from both left and right contexts.
This makes it well-suited for tasks requiring a deeper understanding of relationships between words. However, BERT LLM's bidirectionality can limit its ability to scale to longer sequences.
GPT-3's autoregressive architecture allows it to generate text fluently, making it valuable for tasks like language generation and dialogue systems.
Although lacking in bidirectionality, GPT-3 has shown impressive performance on various language tasks.
Regarding flexibility, BERT LLM's fine-tuning approach makes it adaptable to a wide range of tasks, as it can be trained on different labeled datasets to specialize in specific tasks.
GPT-3, being a generative model, is less flexible in this regard, as it is primarily designed for text generation tasks.
Next, we will cover how to train data.
BERT LLM vs GPT-3: Training Data and Pre-training
The training data used for BERT LLM and GPT-3 differs in sources and size.
BERT LLM is typically trained on large-scale corpora, such as books, articles, and web documents.
These corpora contain diverse text sources, providing a broad linguistic context for the model to learn from. The training data for BERT LLM is extensive, usually comprising millions or even billions of tokens.
GPT-3, as a language generation model, requires even larger training datasets. The training data for GPT-3 often includes vast amounts of text from sources like books, websites, and online platforms.
GPT-3's training dataset can exceed hundreds of gigabytes or even terabytes.
Pre-training Process for Each Model
Both BERT LLM and GPT-3 undergo a pre-training process to learn language representations.
During pre-training, BERT LLM randomly masks certain words in sentences and attempts to predict them. This masked language modeling objective helps the model understand context and relationships between words in a bidirectional manner.
In the case of GPT-3, pre-training involves predicting the next word in a sequence given the preceding context.
GPT-3 learns to generate coherent and contextually appropriate text by training on large-scale text corpora.
Comparison of Data Sources and Size
While BERT LLM and GPT-3 both pre-train on large amounts of text data, they may differ in their data sources and sizes.
BERT LLM commonly utilizes publicly available text sources like books, Wikipedia, and web pages. These sources provide a diverse range of text and knowledge for the model to learn from. Depending on the specific training configuration, the size of BERT LLM's training data can vary, ranging from millions to billions of tokens.
GPT-3's training data also involves sources like books, websites, and internet text. However, due to its focus on language generation, GPT-3's training datasets are significantly larger, often reaching hundreds of gigabytes or even terabytes.
Next, we will cover performance accuracy of BERT LLM and GPT-3.
BERT LLM vs GPT-3: Performance and Accuracy
Evaluating the performance and accuracy of BERT LLM and GPT-3 is essential to understanding their reliability in different language tasks.
BERT LLM has achieved state-of-the-art performance in various natural language processing benchmarks.
It has shown impressive accuracy in question answering, sentiment analysis, and text classification tasks.
BERT LLM's accuracy stems from its ability to capture deep contextual information and understand complex linguistic patterns.
GPT-3 has also demonstrated remarkable performance in language generation tasks, generating highly realistic and contextually appropriate text.
It has been evaluated in various language tasks, including story completion and language translation, where it achieved compelling results.
GPT-3's performance showcases its capacity to generate high-quality language output.
Benchmark Tests and Results
Both BERT LLM and GPT-3 have been evaluated using benchmark tests to assess their language processing capabilities.
BERT LLM has been benchmarked using datasets such as GLUE (General Language Understanding Evaluation) and SQuAD (Stanford Question Answering Dataset).
It has consistently achieved top scores in various subtasks, demonstrating its effectiveness across various language understanding tasks.
GPT-3 has been evaluated using tasks like language translation, text completion, and summarization.
It has shown impressive results, often surpassing previous state-of-the-art models. GPT-3's evaluations have highlighted its strong language generation capabilities.
Suggested Reading:LLM Use-Cases: Top 10 Industries Using Large Language Models
Limitations or Challenges for Each Model
While BERT LLM and GPT-3 offer impressive language processing abilities, they also face certain limitations and challenges.
BERT LLM's bidirectional training makes it computationally expensive and less scalable for longer texts. It requires tokenization, which can limit its ability to handle out-of-vocabulary words.
Additionally, BERT LLM lacks explicit modeling of relationships between sentences, which can be a challenge for certain tasks.
GPT-3's language generation strength can sometimes lead to over-optimistic or biased responses. It may generate text that is contextually appropriate but factually incorrect.
GPT-3's limitations include the potential for generating misleading or inappropriate content and the lack of fine-grained control over the output.
Conclusion
The battle of language models has raged on, but one thing is clear: both BERT LLM and GPT-3 are linguistic titans, each with its unique strengths.
BERT LLM's contextual understanding and versatility make it a formidable choice for tasks like sentiment analysis and question answering. Meanwhile, GPT-3's language generation prowess shines in content creation and conversational AI.
Ultimately, the choice between these models depends on your specific needs. If you require deep language comprehension and flexibility, BERT LLM could be the ideal ally. But if you prioritize fluent text generation and natural dialogues, GPT-3 might be the perfect fit.
Whichever path you choose, one thing is certain: the future of language technology has never been more exciting. Embrace the power of these language models and unlock new possibilities for your business or research endeavors.
Suggested Reading:
Custom LLM Models: Is it the Right Solution for Your Business?
Frequently Asked Questions (FAQs)
How do BERT LLM and GPT-3 differ in their pre-training data and methodology?
BERT LLM is pre-trained on large-scale text corpora using masked language modeling and next sentence prediction objectives. In contrast, GPT-3 iverse range of text sources using autoregressive language modeling, resulting in different pre-training strategies and data utilization.
Which model exhibits better performance in downstream NLP tasks?
Performance depends on the specific task requirements.
BERT LLM tends to excel in tasks requiring an understanding of contextual information, such as sentiment analysis and named entity recognition. GPT-3 shines in tasks requiring text generation, such as language translation and text completion.
What are the limitations of BERT LLM compared to GPT-3?
BERT LLM's bidirectional approach may not capture long-range dependencies as effectively as GPT-3's autoregressive nature. Additionally, BERT LLM requires task-specific fine-tuning for optimal performance, whereas GPT-3 can generate text without task-specific prompts.
How do BERT LLM and GPT-3 differ in terms of model size and computational resources required?
GPT-3 is generally larger in terms of model size and requires more computational resources compared to BERT LLM. This makes BERT LLM more accessible for tasks with limited computational resources or when rapid inference is required.
Which model is more suitable for research versus production applications?
Both models have their strengths depending on the application. BERT LLM is often favored in research settings due to its interpretability and flexibility for fine-tuning. GPT-3, with its powerful text generation capabilities, is well-suited for production applications requiring natural language understanding and generation.