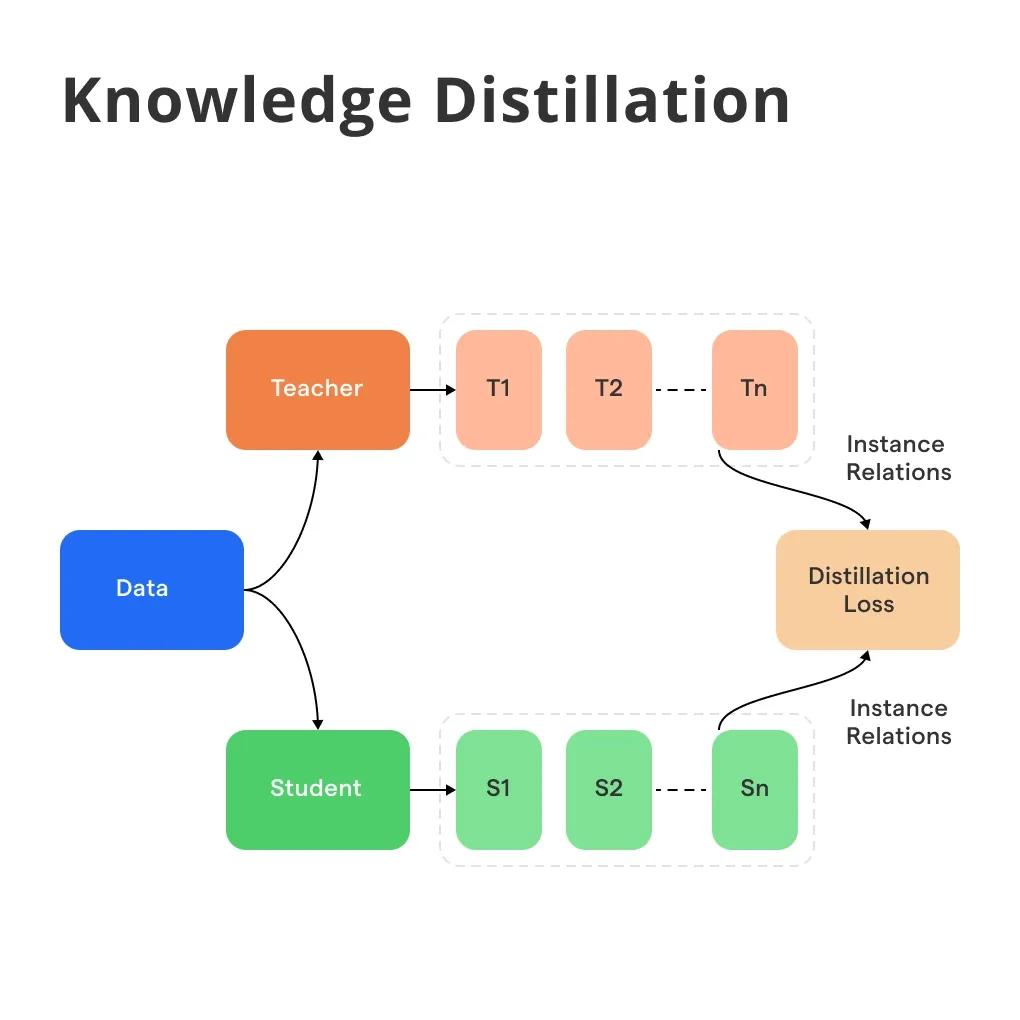
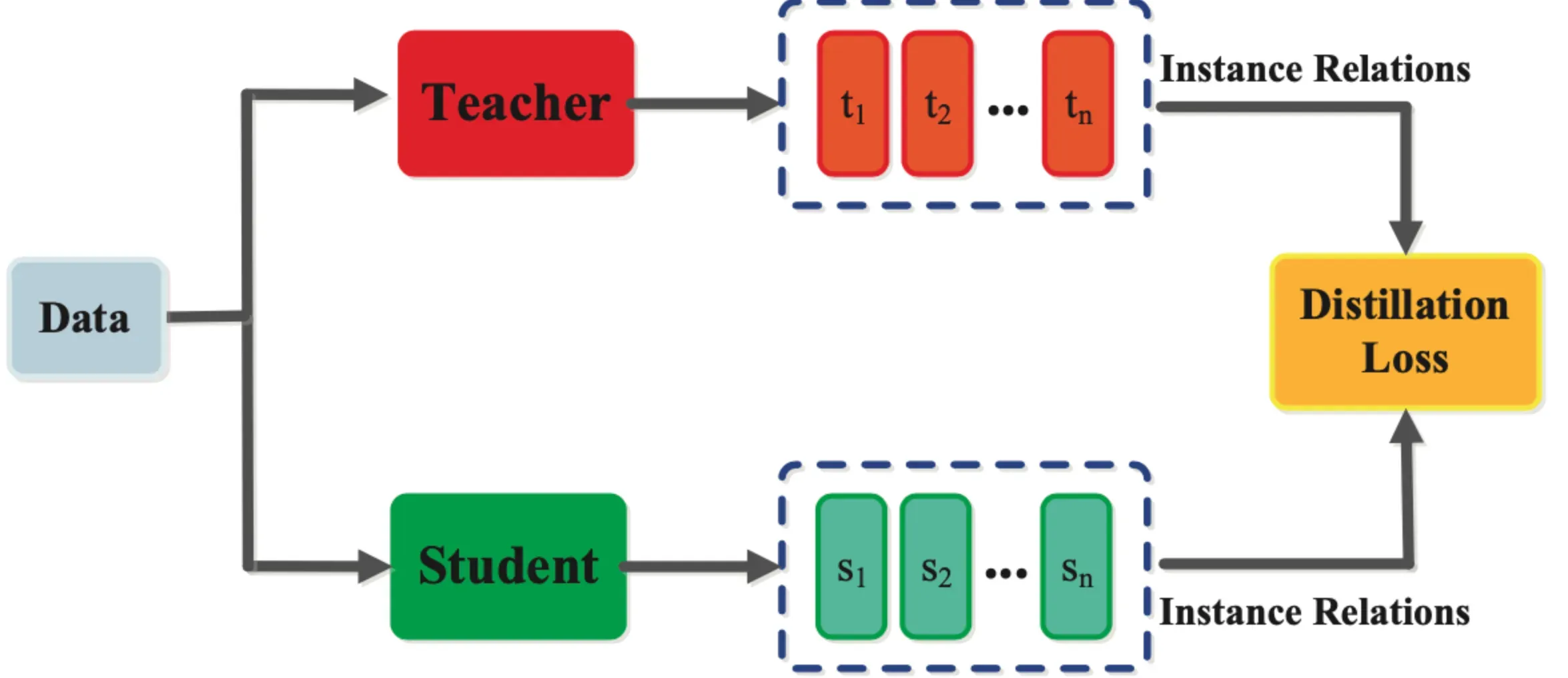
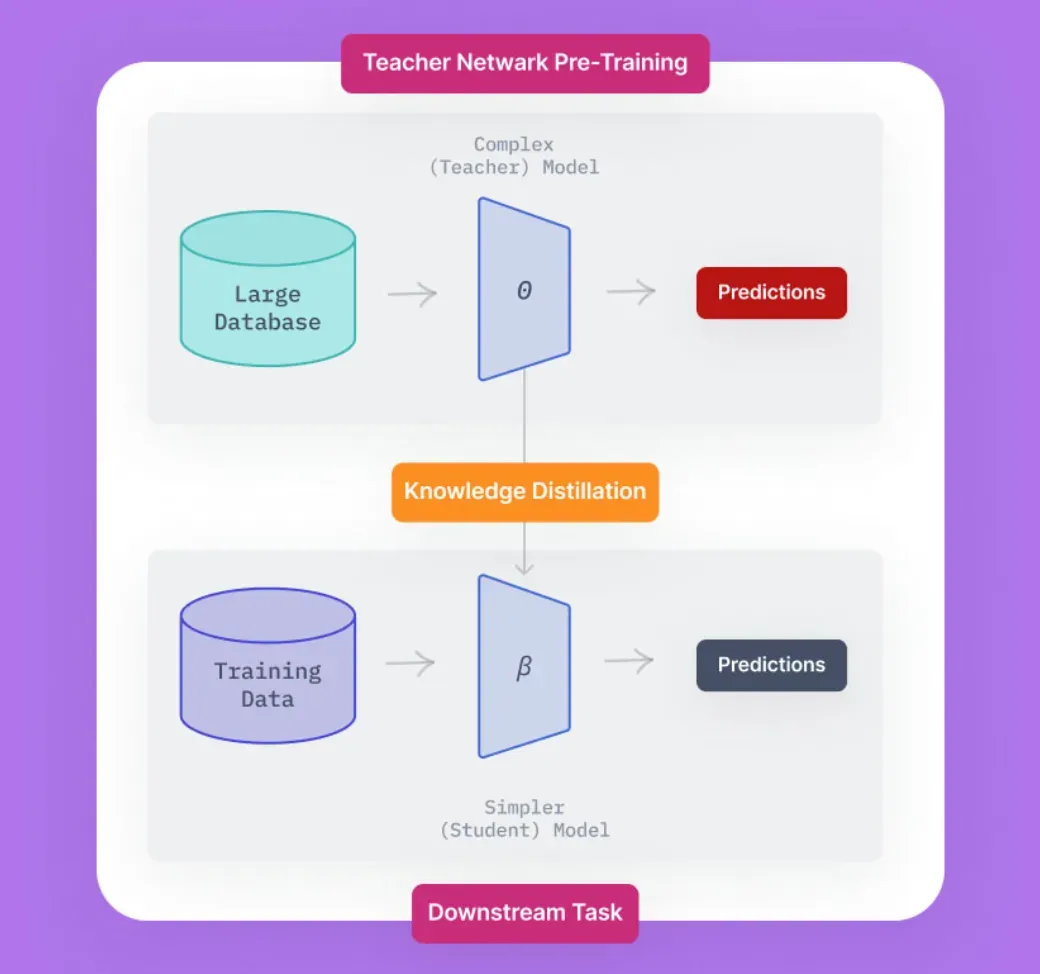
What is Knowledge Distillation?
Knowledge distillation, often referred to as Teacher-Student learning, is a process where a simpler model (the Student) is trained to reproduce the behavior of a more complex one (the Teacher).
History of Knowledge Distillation
Knowledge distillation, in the field of machine learning, really started to shine when Geoffrey Hinton, Oriol Vinyals, and Jeff Dean introduced it in their paper discussing Dark Knowledge in 2015.
Prior to this, models were only trained once - there was no idea of re-training or using one model to train another.
Importance of Knowledge Distillation
Knowledge distillation is particularly crucial when deploying machine learning models on devices with constraints in computational resources.
The distilled model is more efficient, faster, and lighter than the original complex one while still maintaining competence in terms of prediction accuracy.
Different from Traditional Machine Learning
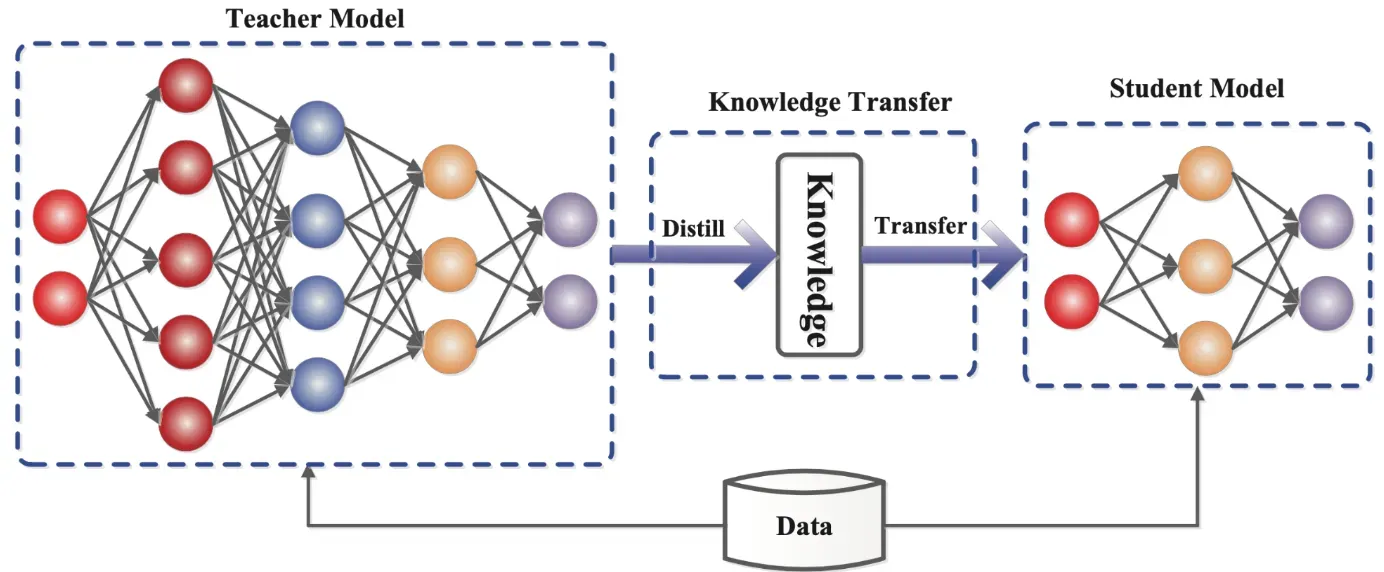
Unlike traditional machine learning where each model is trained and used independently, the concept of knowledge distillation involves using a preexisting, often larger and more complex model to teach a simpler one.
Implementation and Use Cases
Knowledge distillation has been used in several fields. It has been used in Deep Neural Networks (DNNs) to reduce their size and increase run-time efficiency.
Furthermore, it's used in quantized Neural Networks, where the goal is to train a quantized model that matches the full precision model's accuracy.
What is Knowledge Distillation?
Now, let's dive a bit deeper into this interesting topic.
Knowledge distillation is a method used in the training of machine learning models, where a smaller, relatively simpler model (student) is trained to behave like a more complex, pre-existing model (teacher).
How is it Different?
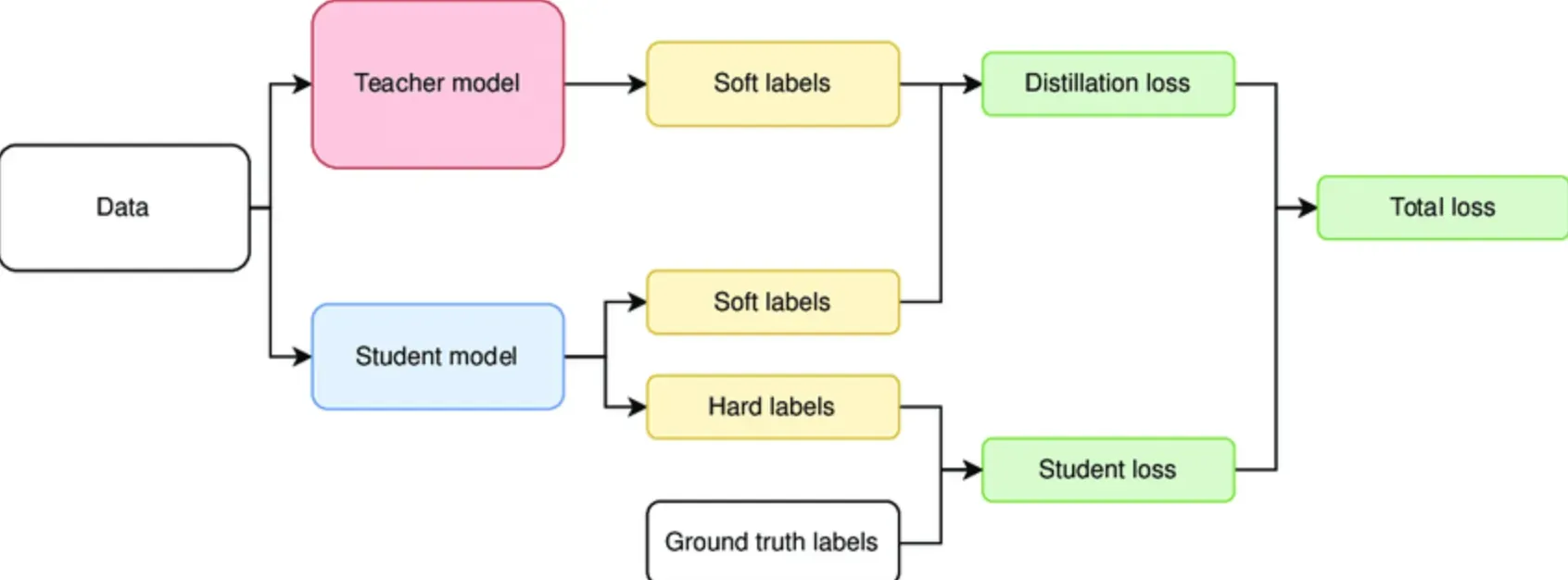
Knowledge Distillation is a type of transfer learning but instead of reusing model structures or pre-trained weights directly, the student learns from the softened output of the teacher model, which contains more information than just hard labels.
The Core Concept
The crux of this process revolves around the concept of "soft targets." These are the output probabilities or logits which the teacher model gives out.
The student model then tries to mimic these outputs, thus learning to generalize the task as the teacher model.
The Learning Process
During the distillation process, the student model is trained using a softened version of the teacher model's predictive distribution. This softening is usually achieved by raising the temperature of the final softmax, which controls the sharpness of the distribution.
Key Components
The two key components in knowledge distillation process are the teacher model (which is usually pre-trained) and the student model (which is often a smaller architecture and is the one to be trained).
Who uses Knowledge Distillation?
So who is actually employing this process and why? Let's find out.
Knowledge distillation has wide-ranging applications across industries where machine learning models are deployed.
Tech Giants
Technology giants like Google, Facebook, and Amazon, with vast resources and complex models, use it to enhance computational efficiency without compromising on the quality of predictions.
Mobile-First Businesses
Companies in the mobile-first era use knowledge distillation extensively to enable the scalability of AI systems on devices with limited computational power.
Machine Learning Researchers
Researchers use it to investigate and uncover insights into how sophisticated models such as deep neural networks make decisions, thus contributing to the broader field of explainable AI.
EdTech Companies
EdTech companies also utilize the teacher-student framework to provide personalized learning content tailored to students' capabilities.
Security and Defense
It's widely used in Cybersecurity and defense applications where real-time performance is crucial.
Where is Knowledge Distillation applied?
Its application extends far beyond what one may initially think. Here are some areas where it's applied.
Image recognition
In image recognition tasks, a larger convolutional neural network (CNN) can be used as the teacher model to teach a smaller CNN to detect and classify images.
Natural language processing
In the field of Natural Language Processing (NLP), large models like BERT can be distilled into smaller models providing near-identical performance with much less computational resources.
Self-driving cars
In the realm of self-driving cars, a larger model that performs a huge number of complex computations can be distilled into a smaller, fast-performing model that still maintains reasonable accuracy.
Speech recognition
In speech recognition, a very deep neural network can be distilled into a smaller, more compact, and efficient model to carry out real-time tasks on a device with restricted computational resources.
Recommendation systems
Complex recommendation systems that run on powerful servers can be distilled into simpler models that can run efficiently on users’ devices, providing personalized recommendations with significantly less computing power.
Why is Knowledge Distillation important?
Let's now understand why knowledge distillation is important.
Efficient deployment
Organizations can deploy high-performing machine learning models on devices with limited computational power and memory because of knowledge distillation.
Better performance
Even with fewer parameters, distilled models offer comparable or superior performance to larger, more complex models. Hence, distillation is often the key to deploying machine learning solutions on edge devices.
Cost-effective
By utilizing fewer computational resources and reducing storage requirements, the cost of maintaining and running models is reduced significantly.
Faster response times
As distilled models are lighter, prediction or response times decrease, offering an improved user experience in real-time applications.
Privacy Enhancements
Edge deployment made possible by knowledge distillation also enhances user data privacy, as the data doesn't have to be sent to a central server for processing.
How does Knowledge Distillation work?
So how does this teacher-student learning happen? Let's demystify it.
Selection of Teacher and Student Models
The first step involves choosing a pre-trained model (teacher) of complex architecture and a smaller model (student), which is often less sophisticated.
Softening the Labels
The teacher model's predictions called hard labels, are then 'softened' by applying temperature scaling. This gives more information about the teacher model's confidence in its predictions.
Training the Student
Next, the student model is trained on the softened labels from the teacher model instead of hard labels from the dataset.
Fine-Tuning the Student
After initial training, further fine-tuning can be done on the student model by training it again on the original hard labels.
Assessing Model Performance
Finally, the effectiveness of the student model is gauged by comparing its performance with that of the teacher model.
Best Practices of Knowledge Distillation
Let’s explore the different practices that help in enhancing the effectiveness of knowledge distillation.
Choosing the Right Models
Selecting appropriate teacher and student models is crucial. Generally, the teacher model should be more complex than the student model.
Temperature Tuning
Correct tuning of temperature in the softmax function helps in softening labels and is pivotal for improved performance.
Fine-Tuning
Close fine-tuning of the student model on the original dataset after initial training can lead to better results.
Diverse Ensemble as Teachers
Sometimes, using diverse ensemble models as teachers can lead to a richer variety of information and potentially better learning performance.
Progressive Distillation
Training intermediate student models between the initial teacher model and the final student model could lessen the gap between them, thus making learning easier.
Challenges of Knowledge Distillation
While knowledge distillation is a powerful technique, it's not without its challenges.
Complexity Misbalance
If the sizes of the teacher and student models are too disparate, the student model might struggle to learn effectively.
Overfitting
If the temperature parameter during distillation is not selected carefully, the student model can end up overfitting to the teacher model's outputs.
Loss of Precision
There's a risk that important details are lost during distillation due to the process of simplification.
Lack of Transparency
As with most deep learning techniques, there's also the potential issue of lack of transparency and interpretability of the process.
Dependence on Teacher
The student model's performance heavily depends on the teacher model, and any inaccuracies in the teacher model might propagate to the student model.
Trends in Knowledge Distillation
As the machine learning field expands, so do the trends and approaches in knowledge distillation.
Augmented Distillation
This involves introducing artificial 'jitter' or variations into the data during training to potentially improve the quality of the distilled model.
Self-Distillation
This is a process where a model is distilled multiple times, with the student model becoming the teacher for the next student model.
Distillation with Reinforcement Learning
The process of distillation has started to enter the realm of reinforcement learning, where a large and complex policy network can be distilled into a simpler one.
Layer-wise Distillation
This new trend focuses on distilling specific model layers instead of the entire architecture, offering problematic layers a course correction.
Progressive Distillation
This involves the creation and training of intermediate student models between the initial teacher model and the final student model, making the entire learning process smoother.
This rounds up our comprehensive dive into the universe of knowledge distillation. We've learned about its history, what it is, its importance and applications, the best practices, and the challenges apart from the trends in this domain.
With AI constantly reshaping the world around us, the significance of knowledge distillation is bound to increase over time.
Frequently Asked Questions (FAQs)
How Does Knowledge Distillation Improve Model Deployment on Edge Devices?
Knowledge distillation compresses complex models into smaller ones that retain original proficiency, making them suitable for resource-constrained edge devices.
Can Knowledge Distillation be applied to any Machine Learning Model?
It is primarily applicable to models where a smaller "student" model learns to mimic a larger "teacher" model, such as neural networks.
How does Temperature affect Knowledge Distillation?
Temperature controls the softness of the probabilities in the output distribution, affecting the smoothness of the knowledge transferred from teacher to student.
What is the role of the Student Model in Knowledge Distillation?
The student model learns the generalized knowledge from the teacher model, aiming to replicate its performance in a more compact architecture.
Can Knowledge Distillation help in Reducing Overfitting?
Yes, by learning from the softened outputs of the teacher model, a student model may generalize better and reduce overfitting compared to training from scratch.