What is Thompson Sampling?
Thompson Sampling, also known as Bayesian Bandit, is a heuristic for choosing actions that address the exploration-exploitation dilemma in the multi-armed bandit problem. It is a probabilistic algorithm that uses Bayesian statistics for decision-making.
Origins of Thompson Sampling
Thompson Sampling is attributed to the work of William R. Thompson, who proposed this approach in 1933. It's one of the oldest algorithms for the multi-armed bandit problem.
Anatomy of Thompson Sampling
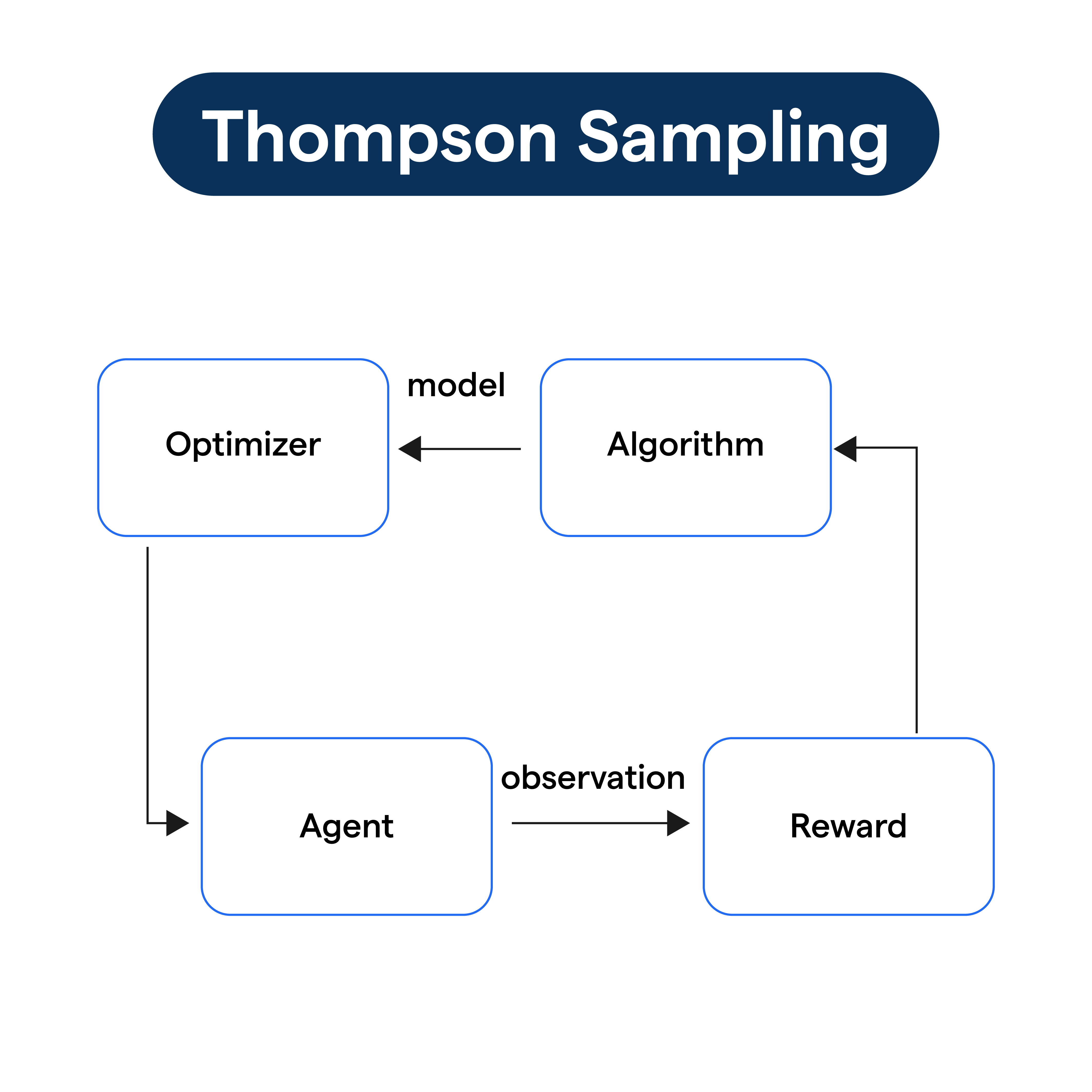
Thompson Sampling algorithm operates by maintaining a probability distribution for each action's rewards. It then randomly selects an action according to its current estimated probability of being the best.
Goal of Using Thompson Sampling
The primary goal of Thompson Sampling is to balance the trade-off between exploration (trying out each action to gather information) and exploitation (choosing the best action given current information).
Variations of Thompson Sampling
While the basic principle remains constant, Thompson Sampling algorithms can have variations depending on the exact nature of actions, rewards, and their distribution assumptions.
Why is Thompson Sampling Important?
Understanding the importance of Thompson Sampling will throw light on why it is such an instrumental tool in reinforcement learning.
Balancing Exploration vs. Exploitation
Thompson Sampling provides an algorithmic solution to the classic exploration-exploitation dilemma, making it a fundamental concept in reinforcement learning.
Real-world Application
Thompson sampling finds diverse real-world applications, from online advertising, personalized recommendations, and clinical trials to finance, showcasing its practical importance.
Built on Solid Statistical Foundation
Thompson Sampling is based on Bayesian inference, a rigorous statistical method, which makes it a mathematically sound approach in decision-making problems.
Versatility
These algorithms can work with different types of reward distributions – binary, categorical, or continuous, making them versatile for various use cases.
Statistical Efficiency
Thompson Sampling, especially with delayed feedback scenarios, often provides better statistical efficiency than other exploration-exploitation strategies.
When to Use Thompson Sampling?
Identifying the situations and scenarios of using Thompson Sampling will help algorithm designers apply it effectively.
Reinforcement Learning Problems
One should consider using Thompson Sampling for reinforcement learning problems, especially the multi-armed bandit problems.
Online A/B Testing
Thompson Sampling can be used in dynamic A/B testing scenarios where the balance of exploration (identifying the best version) and exploitation (serving the best version) is necessary.
Adaptive Clinical Trials
In adaptive clinical trials where treatment effectiveness is uncertain, applying Thompson Sampling can lead to better patient outcomes and more efficient trials.
Resource Allocation Problems
When faced with resource allocation problems such as budget distribution across different marketing channels, Thompson Sampling can provide improved strategies.
Dynamic Pricing
In situations like dynamic pricing, where you need to learn and adapt prices based on user behavior, Thompson Sampling can be of great use.
Where is Thompson Sampling Applied?
Knowing where Thompson Sampling is applied can offer insights into its wide-ranging uses in diverse fields.
Digital Advertising
In today's real-time bidding and ad placements, Thompson Sampling aids in ad selection for each user impression.
Recommendation Systems
Thompson Sampling powers many recommendation systems by dynamically learning and serving personalized recommendations for users.
Financial Portfolio Management
In finance, Thompson Sampling helps in portfolio selection by optimally diversifying investments to maximize returns.
Internet Traffic Routing
Thompson Sampling contributes to intelligent traffic routing systems by dynamically directing web traffic for better load balancing.
Clinical Trial Design
In healthcare, Thompson Sampling is used for designing more efficient and effective adaptive clinical trials.
Who are Concerned with Thompson Sampling?
Grasping who should be most concerned with understanding and using Thompson Sampling can lead to a better appreciation of its relevance.
Data Scientists
Any Data Scientist dealing with Reinforcement Learning should understand and be able to use Thompson Sampling.
Product Managers
Product Managers building personalized engines need to be aware of Thompson Sampling as it can directly affect product performance.
Machine Learning Engineers
For machine learning engineers implementing learning algorithms, Thompson Sampling might be a crucial methodology in their toolbox.
Clinical Researchers
In healthcare, clinical researchers designing adaptive clinical trials need to have a thorough grasp of Thompson Sampling.
Digital Marketing Analysts
For those in digital marketing, Thompson Sampling comes into play while making real-time bidding decisions or other dynamic, data-driven marketing tactics.
How is Thompson Sampling Implemented?
Underlying the steps and processes involved in implementing Thompson Sampling will provide clarity on applying it effectively.
Understanding the Problem Context
Before implementing, thoroughly understand the problem context, especially the actions, rewards, and their uncertain relationship.
Initialize Beliefs
Initialize prior distributions for each action. These distributions should represent your initial belief about each action's reward.
Selection, Action, Update Cycle
In each time step, sample from each action's distribution, select the action with the highest sample, take the action, observe the reward, and update the belief distribution based on the observed reward.
Algorithmic Considerations
Pay attention to algorithmic choices - how to represent distributions, how to sample from them, and how to perform Bayesian updates.
Monitor and Adjust
Track the performance of Thompson Sampling, adjust parameters as necessary, and be prepared to tweak or refine the model as more data becomes available.
Advantages and Limitations of Thompson Sampling
Examining the benefits and the bounded utility of using Thompson Sampling can provide a balanced perspective.
Advantages of Thompson Sampling
From automatic exploration-exploitation balancing, flexibility, and simplicity to good empirical performance - Thompson Sampling offers several advantages.
Probabilistic Interpretation
A key advantage is its probabilistic interpretation of balancing exploration and exploitation, which makes it logically appealing.
Off-line Simulation Benefit
Because Thompson Sampling inherently simulates estimates, it easily adapts to offline simulations to estimate performance.
Robust Performance
Thompson Sampling is reported to have robust performance compared to many other algorithms in various problem scenarios.
Limitations of Thompson Sampling
Like any method, Thompson Sampling also has its limitations. It might not work well when reward distributions don’t match the assumed prior or when there are non-stationary reward distributions.
Comparison of Thompson Sampling with Other Strategies
Comparing Thompson Sampling with other leading strategies can provide insights into choosing the best strategy for specific problems.
Thompson Sampling vs. Epsilon-Greedy
While both strategies are widely used for balancing exploration and exploitation, Thompson Sampling typically outperforms Epsilon-Greedy, especially in contexts with delayed feedback.
Thompson Sampling vs. Upper Confidence Bounds (UCB)
Thompson Sampling and UCB are two leading strategies for handling the multi-armed bandit problem. Comparative studies often show Thompson Sampling performing better or at par with UCB.
Thompson Sampling vs. Optimal Bayesian
Thompson Sampling is often nearly as good as the hypothetically optimal Bayesian strategy that knows the true prior.
Performance on Real-World Problems
Researchers have conducted numerous benchmark tests on real-world datasets, often finding Thompson Sampling providing high-quality solutions.
Guideline for Strategy Selection
While Thompson Sampling often performs well, understanding the problem context, task complexity, and nature of data is essential when choosing the right strategy.
Innovations and Future Research Directions in Thompson Sampling
Surveying the exciting innovations and promising future research directions in Thompson Sampling can tune us to the horizon.
Contextual Bandits and Thompson Sampling
Recent research is focused on extending Thompson Sampling to more complex problems like contextual bandits where action rewards depend on context variables.
Thompson Sampling with Human-in-the-Loop
Exploring Thompson Sampling with Human-in-the-Loop systems to balance algorithmic choices with human intelligence is an emerging area.
Non-Stationary Environments
Designing Thompson Sampling strategies for non-stationary environments where the reward distribution changes over time is a promising research direction.
Thompson Sampling in Deep Reinforcement Learning
Incorporating Thompson Sampling in Deep learning architectures for reinforcement learning problems is another active research area.
Advanced Computational Techniques
Using advanced computational techniques to scale Thompson Sampling for high-dimensional problems is expected to be a broad research direction.
Impact of Thompson Sampling in Decision Sciences
Let's explore how Thompson Sampling is making an impact in the broad domain of decision sciences.
Transforming A/B Testing
Thompson Sampling is transforming traditional A/B testing into more efficient and dynamic methods.
Personalization in Tech Industry
For real-time, personalized recommendations, many tech giants rely on Thompson Sampling to learn individual users' preferences and maximize platform engagement.
Efficient Clinical Trials
In healthcare, Thompson Sampling is revolutionizing the design and operation of clinical trials, leading to more effective treatments and better patient outcomes.
Optimized Digital Marketing
From more effective ad placements to optimized email marketing campaigns, Thompson Sampling is enabling a new age of data-driven digital marketing.
Smart Resource Allocation
In operations research, Thompson Sampling is being used to optimally allocate scarce resources, like budget or staff, across various competing demands.
Best Practices of Thompson Sampling
Implementing Thompson Sampling efficiently requires following some best practices:
Proper Prior Initialization
Establish correct prior probability distributions. Your initial beliefs about the rewards associated with the actions significantly influence Thompson Sampling's performance.
Data Representation
Consider how you represent the data, and adjust your Thompson Sampling implementation accordingly. If the reward data is binary, consider using Beta-Binomial distribution. For real-valued data, use Gaussian distributions.
Bayesian Updating
Follow correct Bayesian updating procedures to adjust distribution after each round.
Simulating from Distributions
Use reliable methods to simulate the distribution.
Practise Patience
Thompson Sampling is a probabilistic algorithm, meaning it needs enough time to explore all available actions and learn their reward distributions accurately.
Monitor & Tune
Continuously monitor the algorithm's output and tune parameters, including the prior distribution, as necessary.
Challenges of Thompson Sampling
Implementation and usage of Thompson Sampling bring several challenges:
Prior Distribution Assumption
The biggest challenge is that you need to make an assumption about the prior distribution which may or may not map accurately to the true reward distribution.
Computational Efficiency
Higher-dimensional and complex problems require advanced computational techniques and pose significant challenges.
Non-stationary Environments
Thompson Sampling can underperform in non-stationary environments, where the reward probabilities change over time.
Delayed Feedback
Delayed feedback often complicates the learning process.
Thompson Sampling Examples
Here are a few examples demonstrating Thompson Sampling's application:
Online Advertising
Imagine you work for a digital advertising platform, and you have 3 different ad designs(A, B, C) for a specific campaign but unsure which one will lead to the most user conversions. You can use Thompson Sampling to algorithmically decide which ad to present to each new user.
Recommendation Systems
An e-commerce platform is trying to personalize its homepage layout for each user. Using Thompson Sampling, it can dynamically learn the optimal placement based on user interactions. It would start with random layouts, monitor user reactions, update beliefs about each layout's utility, and gradually serve better-personalized layouts.
Clinical Trials
Thompson Sampling provides an ethical and mathematically justifiable approach to adaptive clinical trials. Starting with several available treatments, Thompson Sampling can make patient allocation decisions in real time, reducing the chances of patient exposure to sub-optimal treatments.
Financial Portfolio Optimization
A portfolio manager with a diversified portfolio needs to decide how much to invest in each asset. Using Thompson Sampling, the manager can allocate the new funds by learning from historical data. By continually updating the portfolio based on observed returns, Thompson Sampling can help maintain a high-performing portfolio.
A/B Testing
Rather than traditional methods of A/B testing where groups are split evenly, a website can use Thompson Sampling strategy. Here, the initial traffic is split in some proportion to different page variants, and as data on actions (like click-throughs, purchases, etc.) is gathered, the traffic allocation is adapted based on which variant performs better.
Dynamic Pricing
Consider an airline trying to decide ticket prices for a particular route. It has prior beliefs about consumer responses to different price levels, but they are uncertain. Using Thompson Sampling, the airline can dynamically adjust prices, learning more about consumer preferences and optimizing revenue.
Frequently Asked Questions (FAQs)
How does Thompson Sampling stand out in Reinforcement Learning?
Thompson Sampling stands out due to its probabilistic approach. Unlike Epsilon-Greedy or other exploration strategies, it balances the exploration-exploitation tradeoff based on probability distribution probabilities, leading to more efficient learning and optimal action selection.
What contribution does Thompson Sampling make in Bandit Problems?
In Multi-Armed Bandit problems, Thompson Sampling provides a robust solution. By updating probability distributions over actions based on received rewards, it enables a more informed selection of actions to maximize the cumulated rewards over time.
How does uncertainty play a role in Thompson Sampling?
Uncertainty is integral to Thompson Sampling. The methodology utilizes Bayesian updates to revise the uncertainty about each action's reward distribution, influencing the choice of actions and ensuring a more effective balance between exploration and exploitation.
Can Thompson Sampling cope with Non-Stationary Problems?
Despite being designed for stationary environments, Thompson Sampling can adapt to non-stationary problems using sliding windows or discounting past observations, allowing model adjustments to changes in problem dynamics for effective performance.
Is Thompson Sampling useful beyond Reinforcement Learning?
Yes, apart from reinforcement learning, Thompson Sampling finds use in A/B testing, clinical trials, and recommendation systems, where it optimizes decision-making under uncertainty, maximizing long-term rewards in an exploration-exploitation trade-off scenario.

