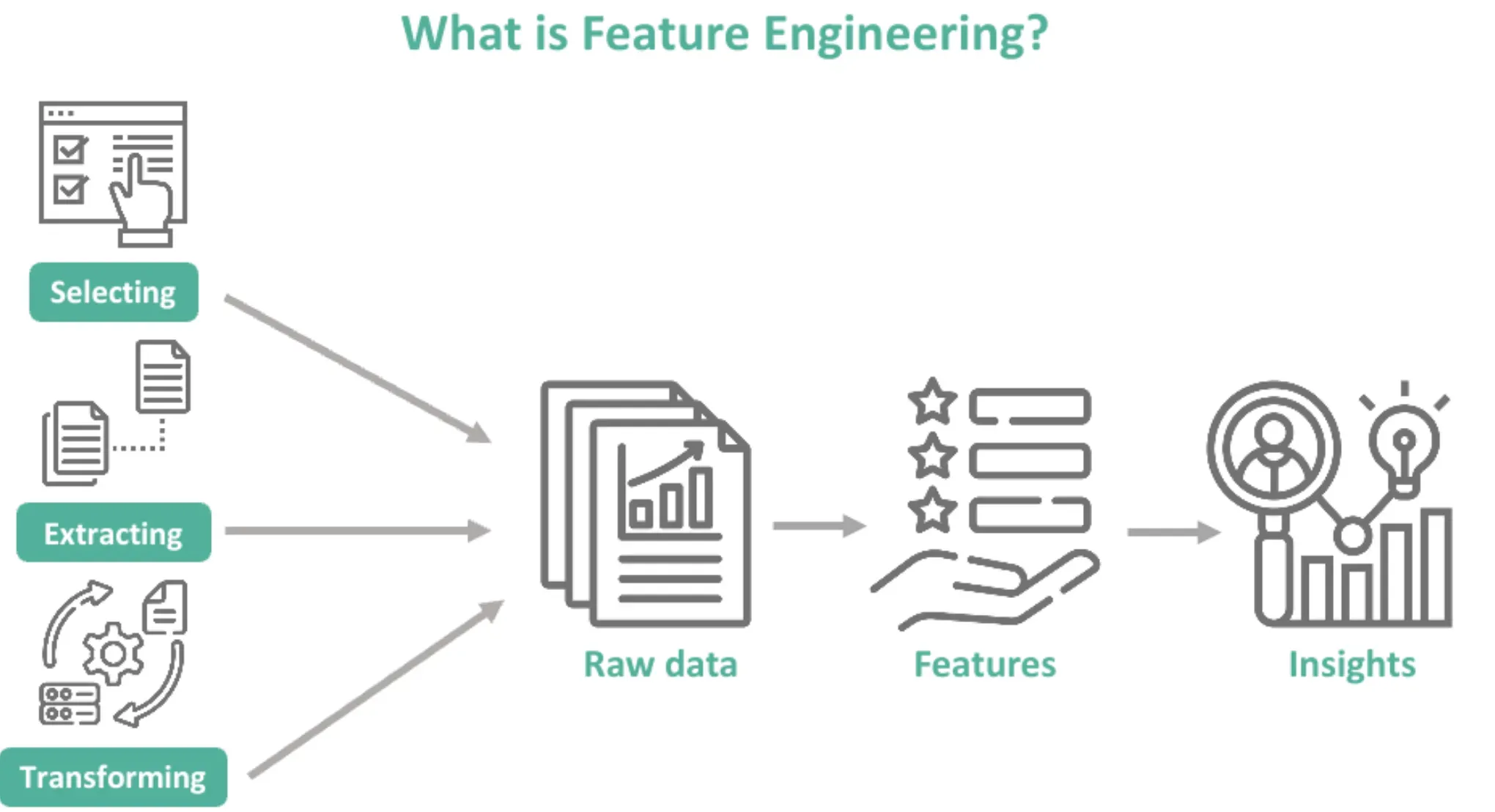
What is Feature Engineering?
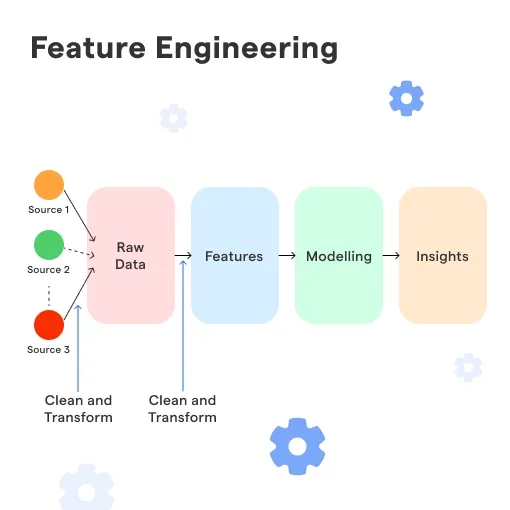
Feature engineering is the process of selecting, creating, and transforming features from the available data that can enhance the performance and accuracy of machine learning models. It involves a combination of domain knowledge, statistical techniques, and creativity to derive valuable insights from data.
Purpose of Feature Engineering
The main purpose of feature engineering is to improve the quality and predictive power of machine learning models. By selecting and creating appropriate features, we can better represent the underlying patterns and relationships in the data, leading to more accurate predictions, reduction of overfitting, and enhanced interpretability.
Flexibility of Better Features
Well-engineered features provide flexibility to the machine learning models, enabling them to capture complex relationships and patterns present in the data. This flexibility expands the model's capability to handle a variety of scenarios and generalize well on unseen data.
Simplicity of Models with Well-Engineered Features
Sophisticated models often come with increased complexity, making them harder to interpret and understand. However, by leveraging feature engineering, we can simplify the models without compromising their accuracy and interoperability.
Importance of Feature Engineering
Feature engineering plays a pivotal role in the success of predictive models.
Performance Improvement
Feature engineering is critical to improving the performance of machine learning models. By selecting and creating relevant and important features, models can better capture the underlying patterns and relationships in the data, resulting in more accurate predictions.
Reduction of Overfitting
Effective feature engineering can help reduce overfitting, where the model becomes too complex and captures noise or irrelevant information in the data. By selecting the right features, models can focus on the most relevant information, reducing the risk of overfitting.
Model Interpretability
Feature engineering is not only important for improving model accuracy but also for enhancing model interpretability. Models that are easier to interpret help us to better understand the underlying patterns and relationships in the data, which is vital in many applications.
Data Imputation and Handling
Feature engineering is also important in data preprocessing, where missing values and outliers are identified and handled appropriately. Feature engineering techniques like imputation provide a way to fill in missing data and ensure that the machine learning model can be trained effectively.
Cost Reduction and Simplicity
Effective feature engineering allows us to simplify models without compromising accuracy. This can result in cost reduction and more efficient use of computing resources, particularly in large-scale machine-learning applications. By reducing model complexity and improving model efficiency, more straightforward models can sometimes perform just as well as more complex models without the added computational expense.
Factors Influencing Results
The success of feature engineering relies on various factors, including the quality and diversity of the data, domain knowledge, creativity, the understanding of the problem, and the evaluation metrics used. These factors collectively determine the effectiveness of the derived features.
How to Perform Feature Engineering?
Performing feature engineering involves following a systematic process. Let's take a closer look:
Process Overview
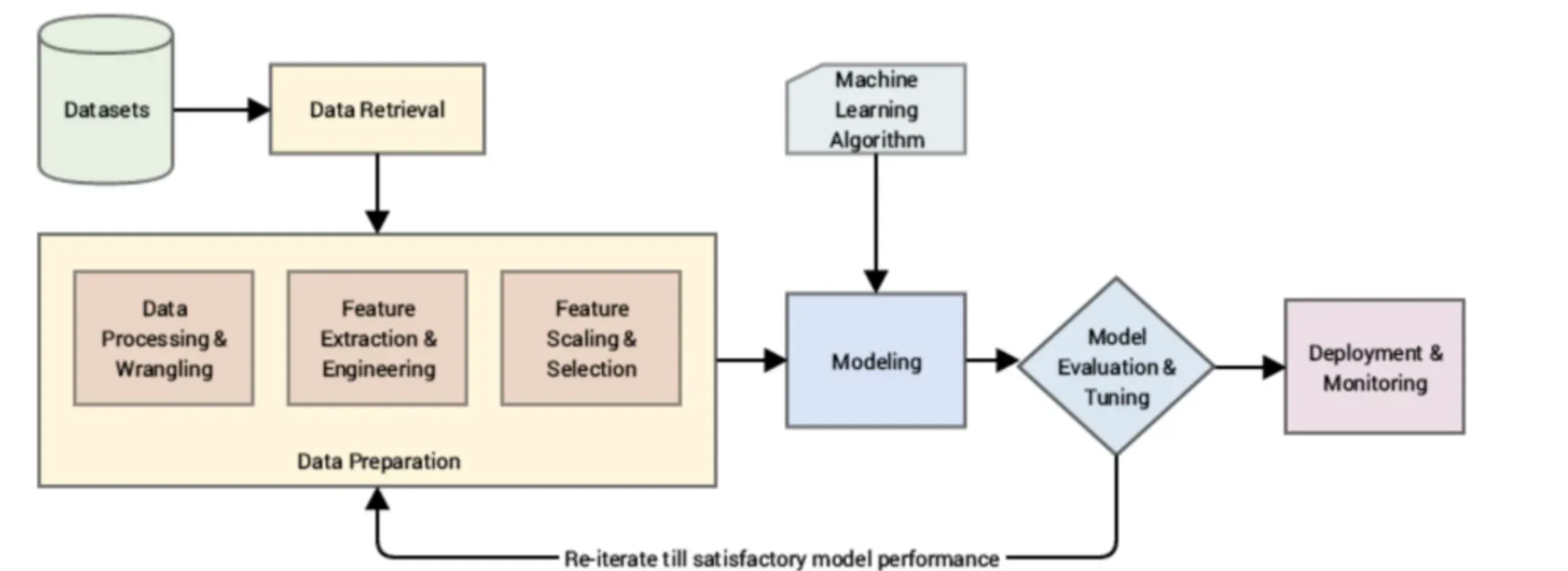
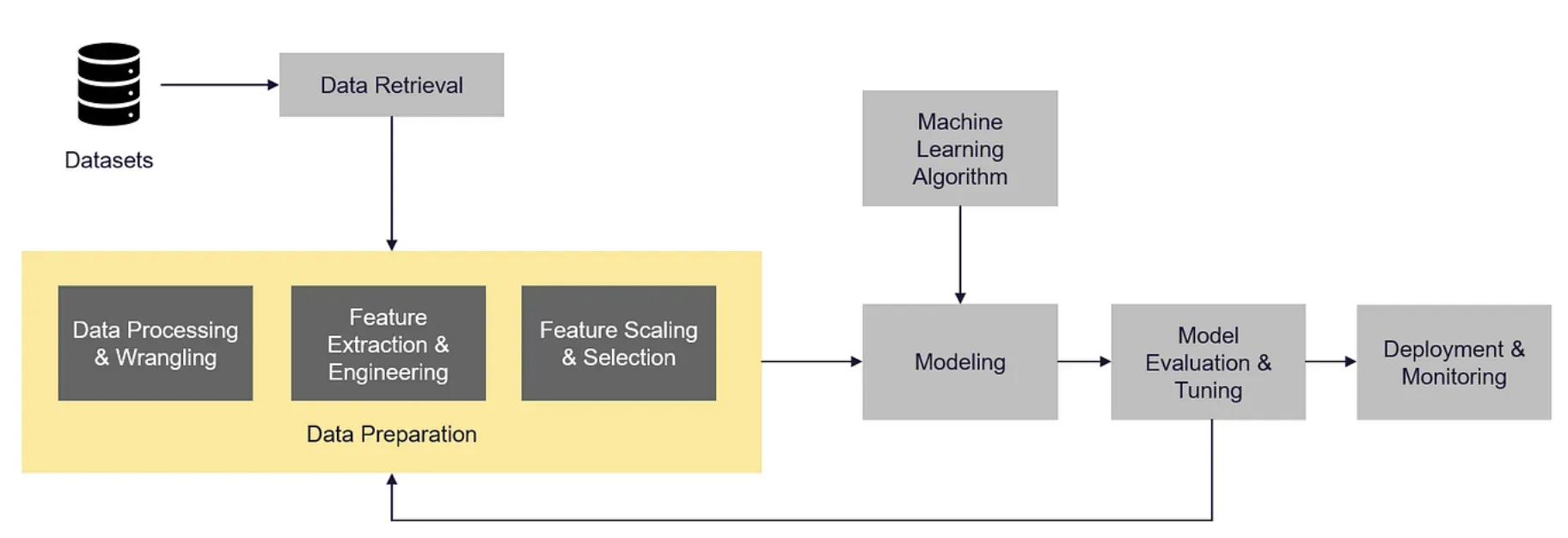
Feature engineering typically involves several stages, such as data analysis, preprocessing, feature selection, transformation, and creation. Each stage contributes to refining the features and preparing them for model training.
Data Analysis and Pre-processing
Analyzing and preprocessing the data is the initial step in feature engineering. This involves understanding the data's structure, identifying missing values or outliers, handling categorical variables, and normalizing or scaling the data.
Rules of Thumb and Judgment
Feature engineering is not only about applying standard techniques but also requires a certain level of subjectivity and domain knowledge. One must make informed decisions on feature selection, and transformation techniques and handle domain-specific challenges.
How to Get Started with Feature Engineering?
Getting started with feature engineering can be challenging. Let's explore some practical tips to kickstart the process:
Understand the Data
Begin by gaining a thorough understanding of your data. Examine the type of data you are working with, its format and potential relationships between different variables.
Define the Problem
Clearly define the problem you are trying to solve. Understand what patterns or insights you want to extract from the data and how these will be useful for your specific task.
Data Cleaning
Clean the data by dealing with missing values, outliers, and inconsistencies. This step is crucial as it ensures the quality of the data and prevents modeling issues.
Feature Selection
Identify the most relevant features by removing irrelevant or redundant ones. You can use techniques like correlation analysis, statistical tests, or domain knowledge to select the features that have the most impact on the target variable.
Feature Extraction
Create new features by transforming the existing ones. This could involve scaling, log transformation, binning, or creating interaction features. This step aims to uncover more meaningful patterns in the data.
Feature Encoding
Convert categorical features into numerical representations. This can be done through techniques like one-hot encoding, label encoding, or target encoding, depending on the nature of the data and the machine-learning algorithm you plan to use.
Feature Scaling
Standardize the numerical features to a common scale to ensure that they have comparable ranges. Scaling can be done using techniques like min-max scaling or z-score normalization.
Evaluate and Iterate
Continuously assess the impact of the engineered features on the performance of your machine learning models. Experiment with different combinations of features and evaluate the results using appropriate evaluation metrics.
Domain Knowledge Integration
Incorporate domain expertise into the feature engineering process. This can help in identifying relevant features and applying task-specific transformations that can improve the model's performance.
Automate the Process
Once you become familiar with feature engineering techniques, consider automating the process to save time and effort. Libraries such as Featuretools, tsfresh, and sci-kit-learn provide tools for automating feature engineering tasks.
Techniques for Feature Engineering
The key techniques for features engineering include imputation, handling outliers, binners, etc. Let’s learn more about them.
Imputation
This technique is used to handle missing values in the dataset. It involves filling the missing values with suitable replacements or using statistical methods such as mean, median, or mode.
Handling Outliers
Outliers are data points that deviate significantly from the majority of the data. Handling outliers is important because they can negatively impact the model's performance. Techniques for dealing with outliers include removing them, transforming them to fall within an acceptable range, or treating them as missing values.
Binning
Binning involves grouping continuous variables into bins or categories. This simplifies the relationships between the variables and can enhance the interpretability of the model. Binning can be done using equal width, depth, or custom intervals.
Log Transform
Log transformation is applied to skewed data to make it more suitable for modeling. It reduces the effect of extreme values and can help normalize the data.
One-Hot Encoding
One-hot encoding is used to encode categorical variables into binary vectors. Each category is represented by a binary vector where only one element is "1" and the rest are "0". This technique is useful for models that require numerical input.
Grouping Operations
This technique creates new features by grouping or aggregating data based on certain attributes or relationships. It can help capture higher-level patterns and relationships in the data.
Feature Split
Feature split is used to split text or string features into multiple features for more granular analysis. For example, splitting a full name into separate features for first and last names.
Scaling
Scaling is the process of transforming features to a consistent range. It ensures that no feature has a disproportionate influence on the model by bringing all features to the same scale.
Extracting Date
This technique involves extracting meaningful information from date variables such as the day of the week, month, or year. This can help capture seasonality or trends in the data.
When to Apply Feature Engineering?
Understanding when to apply feature engineering is crucial to achieving optimal results. Let's dive into it.
Insufficient Data
In machine learning models, more data usually means better performance. However, sometimes, data can be limited, and there is no way to acquire additional data. In such cases, feature engineering can help create new features from existing data, which helps extract more information from the available data.
Irrelevant Features
Sometimes, there may be irrelevant features in the data that may result in noise or bias in the model. Feature engineering can help to identify and remove such features from the input data.
Non-Numeric Data
Machine learning models can only process numeric data, but sometimes we may have non-numeric data, such as text or images, as input. Feature engineering can help to extract useful features from such non-numeric data, which can be used as input to the model.
Model Performance Improvement
Feature engineering can help to improve model performance by creating features that better represent the underlying data. Better representation of the data leads to increased model accuracy and better predictions.
Frequently Asked Questions (FAQs)
What is the difference between feature engineering and feature selection?
Feature engineering involves creating or transforming features, whereas feature selection focuses on choosing the most relevant subset of features. Feature engineering improves the quality of features, while feature selection reduces the dimensionality of the feature space.
Are there any automated methods for feature engineering?
Yes, there are automated methods for feature engineering, such as automated feature engineering libraries or algorithms that can generate new features based on the existing ones. These methods can save time and effort in the feature engineering process.
How does feature engineering impact model interpretability?
Feature engineering can impact model interpretability. By creating meaningful features, it becomes easier to understand the relationship between the input variables and the target variable. Well-engineered features can provide insights into the underlying patterns in the data.
Can feature engineering only be performed on structured data?
Feature engineering is commonly associated with structured data, but it can also be applied to unstructured data like text or images. Techniques like text processing, natural language processing, or image feature extraction can be used for feature engineering in unstructured data.
Does feature engineering require domain knowledge?
Domain knowledge can be valuable for feature engineering, as it helps understand the data and the problem context. However, it is not always necessary. Feature engineering can also be driven by data analysis and exploratory techniques to uncover patterns and relationships in the data.