Transformers are smart networks that understand word connections, allowing them to grasp context and language complexity than previous models.
From the first transformer to the latest, like GPT-4, they've reshaped how we understand language. Their capacity to work with big datasets, grasp intricate connections, and learn quickly has led to many applications.
In a recent OpenAI study, GPT-3, a pre-trained transformer model, can produce text indistinguishable from human writing in 52% of cases.
Compared to human brains with 86 billion neurons, GPT-3 has 175 billion parameters, a measure of intelligence.
Transformers, like GPT-3, GPT-3.5, and GPT-4, consume vast datasets during training to learn intricate patterns and relationships. These models excel at few-shot learning, generating human-like text. They can create music, explain quantum physics, or suggest Netflix movies with just a text request. It's a significant breakthrough.
Transformers are sparking a new era in artificial intelligence. So, understanding how the transformer model works will be beneficial in the long term.
So, keep reading to learn more about transformer models.
What is a Transformer Model?
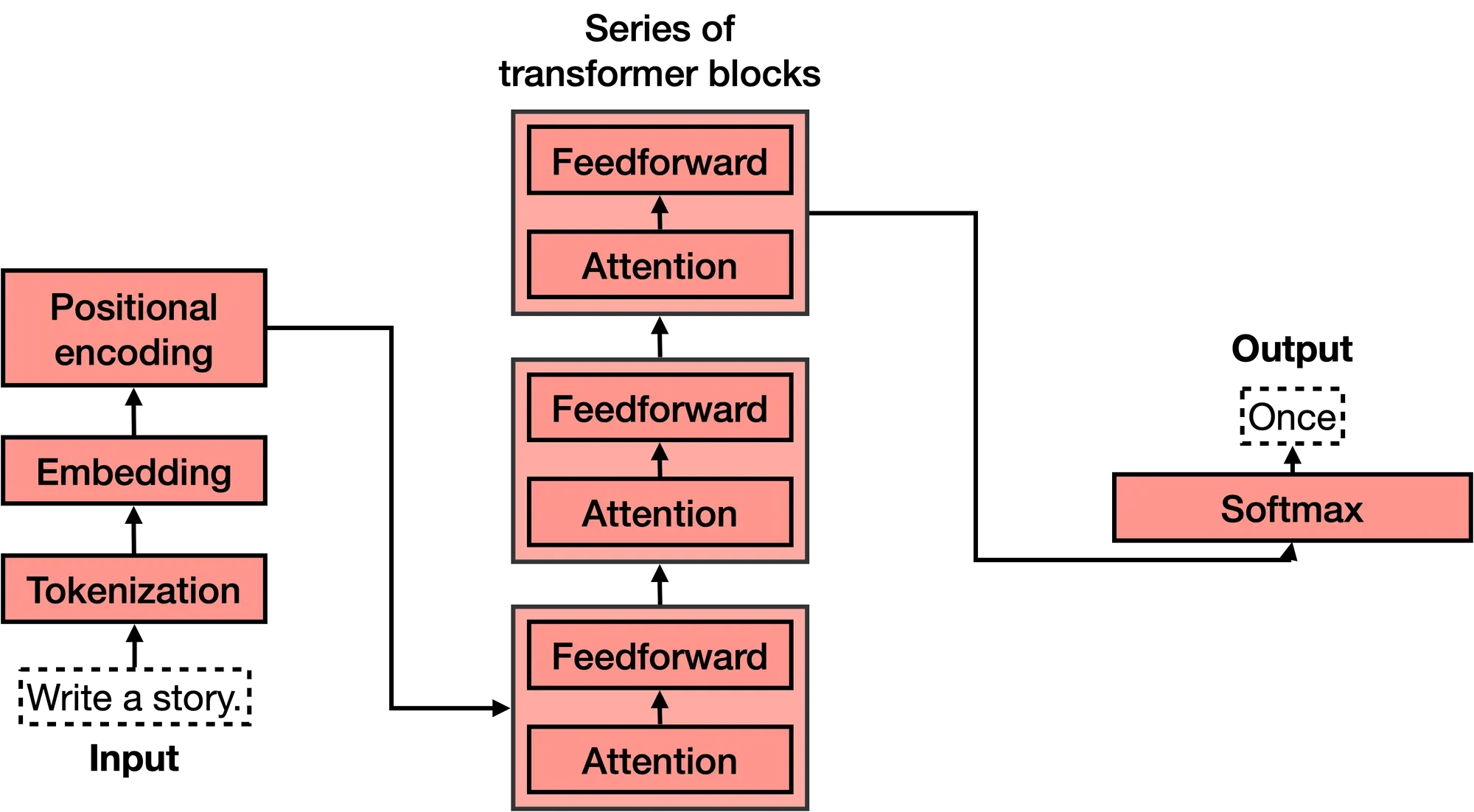
The Transformer model is a type of deep learning model introduced in 2017. It is used for natural language processing tasks, such as machine translation and text generation. The model utilizes self-attention mechanisms to capture relationships between words, allowing it to process input data in parallel and achieve state-of-the-art performance.
Advancements in Transformer Models
Transformer models have seen significant advancements since their introduction. These advancements have led to improvements in various natural language processing (NLP) and machine learning tasks. Here are some key advancements in transformer models:
BERT (Bidirectional Encoder Representations from Transformers)
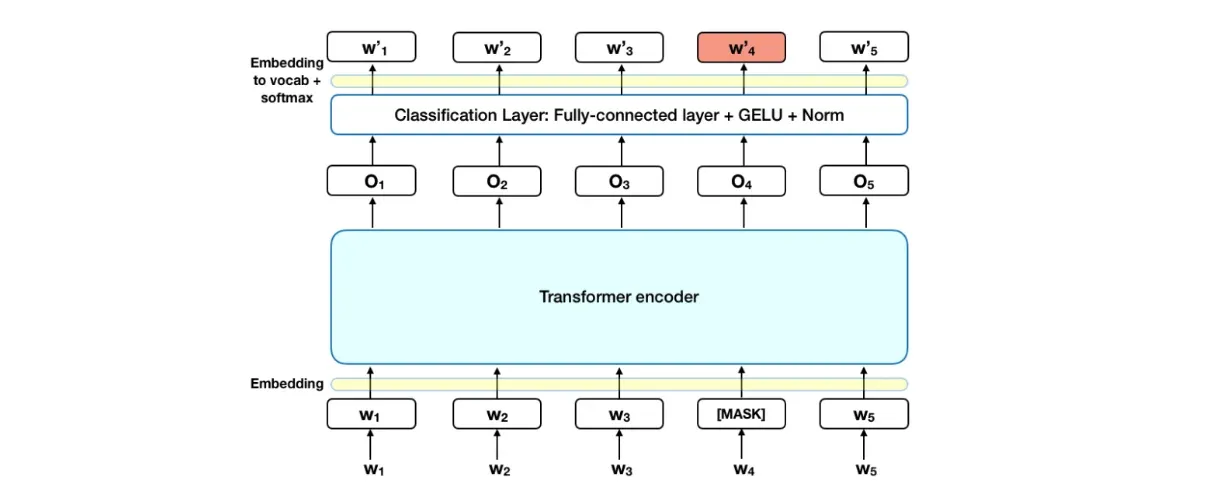
BERT, introduced by Google in 2018, marked a significant advancement by pre-training transformers on large text corpora in a bidirectional manner. This bidirectional pre-training improved the understanding of context and semantics, leading to remarkable gains in a wide range of NLP tasks, such as question answering, text classification, and sentiment analysis.
GPT (Generative Pre-trained Transformer) Series
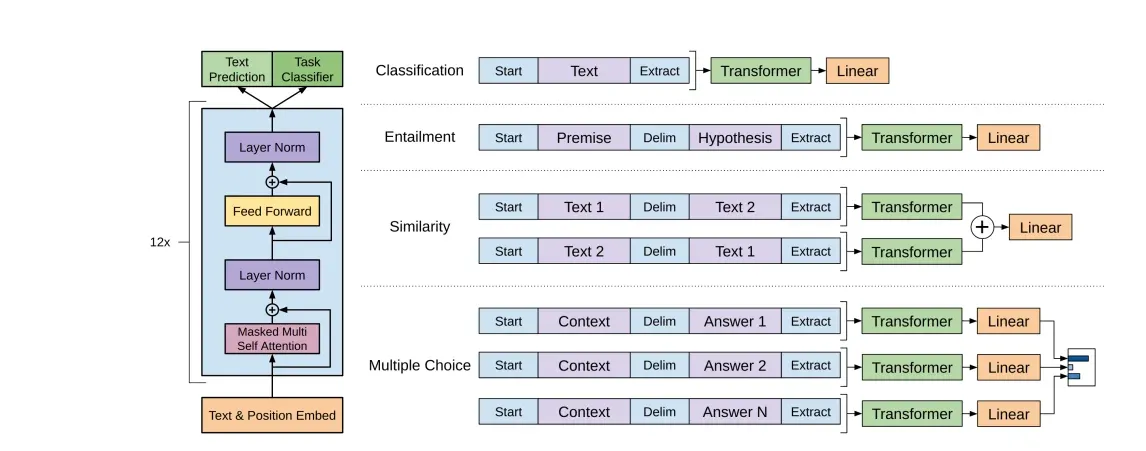
The GPT series, developed by OpenAI, consists of generative models trained on massive text datasets. GPT-2 and GPT-3, in particular, have demonstrated the capability to generate human-like text, answer questions, and perform various language-related tasks accurately. GPT-3, with its 175 billion parameters, represents one of the largest publicly available transformer models.
XLNet
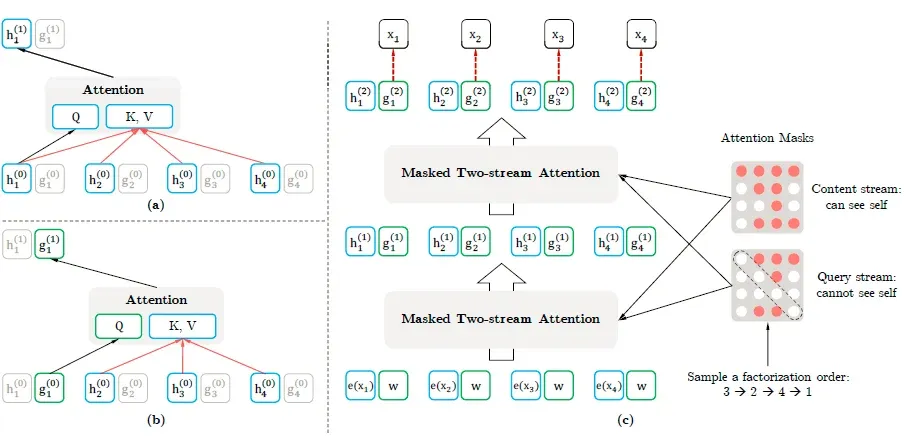
XLNet, proposed by Google AI and Carnegie Mellon University, addressed some limitations of BERT by considering all possible permutations of words in a sentence. This approach improved the modeling of dependencies and relationships between words, leading to state-of-the-art results on various benchmarks.
T5 (Text-to-Text Transfer Transformer)
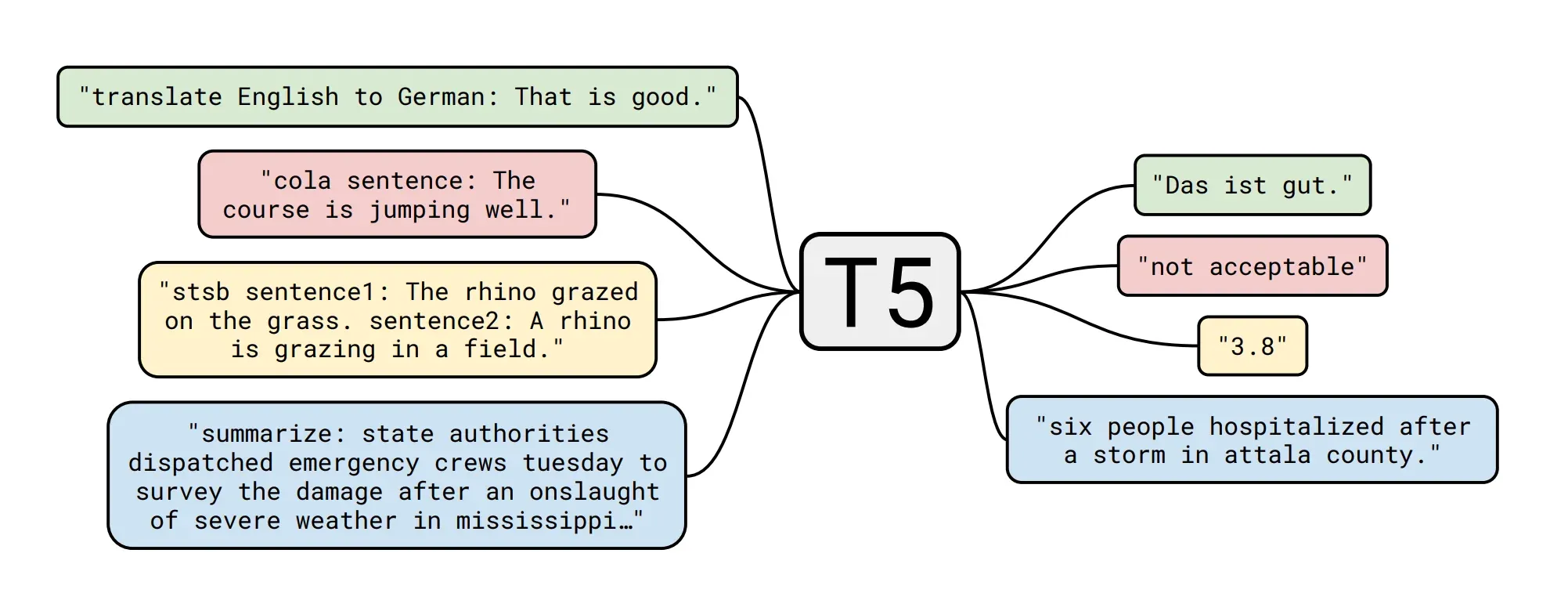
T5, also by Google AI, introduced a text-to-text framework where every NLP task is framed as a text generation problem. This simplified the design of models and allowed for consistent training and evaluation across different tasks. T5 achieved competitive performance across a wide range of NLP tasks.
BERT Variants and Fine-tuning
Researchers have developed numerous BERT variants and fine-tuned models for specific tasks and languages. This fine-tuning process involves training BERT on task-specific datasets, resulting in highly specialized models that excel in tasks like named entity recognition, coreference resolution, and more.
Efficiency Improvements
To make large transformer models more accessible and environmentally friendly, researchers have worked on efficiency improvements. Techniques like model pruning, quantization, and knowledge distillation aim to reduce the computational requirements of these models while maintaining their performance.
Multimodal Transformers
Transformers have been extended to handle multiple modalities, such as text and images. Models like Vision Transformer (ViT) and CLIP can process and generate text from images, opening up new possibilities in areas like computer vision and content generation.
Custom Architectures for Specialized Tasks
Researchers have developed custom transformer architectures for specialized tasks, such as long-document summarization, speech recognition, and protein folding prediction. These models are designed to handle the unique characteristics of their respective domains.
Suggested Reading:
Continual Learning and Adaptation
Ongoing research focuses on making transformer models more adaptable and capable of continual learning. This allows models to adapt to changing data distributions and emerging concepts.
Ethical Considerations and Bias Mitigation
With the increasing impact of transformer models on society, there is growing research into addressing bias, fairness, and ethical considerations in their development and deployment.
How Do Transformer Models Learn?
Transformer models learn through a process called self-attention and deep neural network training. They break text into chunks (tokens) and iteratively update their understanding by assigning each token importance based on relationships with others in the sequence. This enables capturing contextual information.
During training, they minimize the difference between predicted and actual outcomes (e.g., next-word prediction) using backpropagation.
Large datasets and parallel processing on GPUs allow models with millions of parameters to learn intricate patterns in data, ultimately representing language-enabling tasks like translation, summarization, and more.
Transformer's architecture, attention mechanisms, and extensive training data collectively facilitate this learning process.
Suggested Reading:
Transformer Models in Deep Learning: Progress and Practical Applications
Let's explore the advancements and practical uses of transformer models in deep learning:
Key Innovations
The critical innovations include:
Self-attention mechanism that connects all positions.
Learned positional embeddings for encoding order information.
Encoder-decoder architecture.
Multi-head attention for handling multiple representations.
Notable Models
Some standout models are:
BERT (2018) - A bidirectional encoder renowned for its language prowess.
GPT-2 (2019) - A unidirectional decoder model used for text generation.
GPT-3 (2020) - An upsized version of GPT-2, flaunting a staggering 175 billion parameters.
Applications
These models find applications in various domains:
Natural language processing tasks like translation and summarization.
Conversational AI, including chatbots and virtual assistants.
Text and code generation, from articles and essays to software development.
Computer vision tasks such as image captioning and classification.
Diverse fields like drug discovery, healthcare, and more.
Future Outlook
Looking ahead, the future of transformer models in deep learning involves:
Developing larger, more capable foundational models.
Expanding into multimodal and multi-task capabilities.
Tackling issues related to bias, safety, and alignment.
Enhancing model interpretability and explainability.
Conclusion
Transformer models have garnered attention for their exceptional language capabilities. Originally designed for natural language tasks, they now have the potential to revolutionize various fields like education, healthcare, and business.
These models excel in tasks ranging from enabling natural conversations with chatbots to identifying promising molecules and materials. BotPenguin, a chatbot development platform, harnesses transformer models to power its chatbots. It offers user-friendly features like a drag-and-drop chatbot builder, pre-trained models, and deployment tools.
With BotPenguin, building chatbots driven by transformer models is quick and straightforward. Challenges such as efficiency, ethics, and transparency persist but do not overshadow the significant momentum behind transformer technology.
Frequently Asked Questions (FAQs)
What are the key components of Transformer models?
Transformers consist of encoder and decoder layers. The encoder processes input data, employing self-attention to capture context, while the decoder generates output by attending to the encoded information.
What are some recent advancements in Transformer models?
Recent advancements involve techniques like efficient attention mechanisms (e.g., sparse attention, linear attention), model compression methods, and enhanced training strategies (e.g., pre-training, fine-tuning) that improve performance and efficiency.
How do Transformer models handle overfitting or generalization issues?
Techniques such as regularization, dropout, and diverse pre-training strategies are employed to prevent overfitting. Additionally, fine-tuning on specific tasks aids in improving generalization capabilities.
What are the applications of Transformer models in various industries?
Transformer models find applications in machine translation, language understanding, speech recognition, recommendation systems, and image processing, contributing significantly to advancements in these domains.
How do large-scale Transformer models like GPT-3 or BERT work?
Large-scale models like GPT-3 (Generative Pre-trained Transformer 3) or BERT (Bidirectional Encoder Representations from Transformers) leverage massive amounts of pre-training data and complex architectures to achieve state-of-the-art performance in various NLP tasks.
Are there limitations to Transformer models?
While powerful, Transformers demand significant computational resources and memory due to their attention mechanisms, making them resource-intensive. Handling extremely large datasets might pose challenges.