

Choosing the right transformer model is overwhelming. GPT, BERT, T5, and whatnot, it's confusing! Many first-timers spend weeks training massive models only to get mediocre results.
There must be an easier way to pick the best model!
Luckily there is and it’s in this guide. This guide will simplify the process of selecting the right transformer.
We'll explain what they are, look at different models, and give you a framework for choosing one. You'll learn about attention mechanisms, whether to pre-train, and tips for fine-tuning. We'll even look at past and future trends.
Sure, it looks daunting now. But, that’s just a 10,000 feet view. As we dive deep, you’ll find it simple.
By the end, you'll be able to confidently pick the perfect model for your needs. You'll go from puzzled beginner to a transformer expert! This guide transforms technical jargon into clear advice for business leaders, companies, founders, and anyone wanting to leverage transformers.
So let's get started!
We'll make this journey easy and enlightening. You'll gain a simple yet deep understanding of these powerful models and how to select the ideal one for your goals. Let's dive in and demystify the world of transformers!
What exactly are Transformer Models?
Transformer models are all the rage these days in machine-learning land. But what in the world are they, and how do they work their magic? Let's break it down step-by-step.
Imagine you a super-smart person who's really good at understanding and generating text.
A transformer model is like a computer program that tries to be as smart as that person. It's designed to understand and create text just like humans do.
The "transformer" part is like the special ability that lets this program pay attention to different parts of a sentence and understand how they relate to each other.
This makes the program great at tasks like language translation, answering questions, and even writing stories.
It's called a "transformer model" because it transforms words and sentences in a way that helps it understand and generate meaningful text
Automate your various domains, Try BotPenguin
- Marketing Automation
- WhatsApp Automation
- Customer Support
- Lead Generation
- Facebook Automation
- Appointment Booking
Decoding the Transformer Ecosystem
There are so many different transformer models out there, it can feel like wandering into a zoo full of wild architecture!
Let's make sense of the creatures in this transformer menagerie.
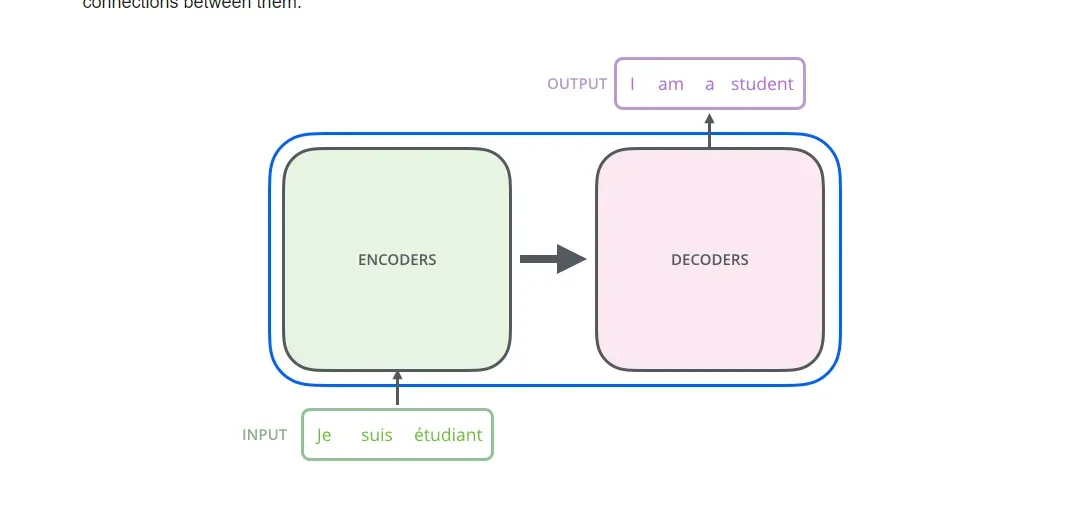
First up, we've got encoder transformer models. These guys only encode the input data into an internal representation. No decoding or generation here! Next are the decoder models, which create predictions from an encoded representation.
Then we have the encoder-decoder models. These do the full input-to-output process, encoding the input data and then decoding it into predictions. The classic combo!
Each type has its own strengths and uses cases. Encoders are great for understanding language, decoders specialize in text generation, and encoder-decoders can do end-to-end tasks like translation.
Checking Out Popular Models
Now that we know what encoder and encoder-decoder models are, we'll dive into three of the most popular transformer models in AI: BERT, GPT, and T5. We'll explore what they are, what they do, and how they conquered the AI universe.
BERT: Bidirectional Encoder Representations from Transformers
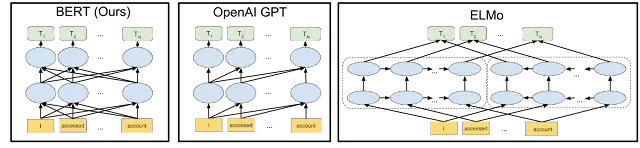
BERT (Bidirectional Encoder Representations from Transformers) is a transformer-based AI language model developed by Google.
It can understand the meaning of words in a text in a bidirectional way (from the left and from the right), offering a deep understanding of language.
Originally designed for the task of natural language processing, BERT is now used for a wide range of tasks, including sentiment analysis, question-answering systems, and machine translation.
BERT represented a breakthrough in the natural language processing field thanks to its accuracy and efficiency.
GPT: Generative Pre-trained Transformer
GPT (Generative Pre-trained Transformer) is another transformer-based language model created by OpenAI.
Unlike BERT, GPT excels in generating coherent and human-like text, making it ideal for tasks such as chatbots, language translation, and content generation.
Based on its architecture, the model predicts the next word in a sequence, using the previous tokens to provide context and generate text that flows naturally. GPT proved a significant advancement in natural language generation, generating coherent, context-relevant text.
T5: Text-to-Text Transfer Transformer
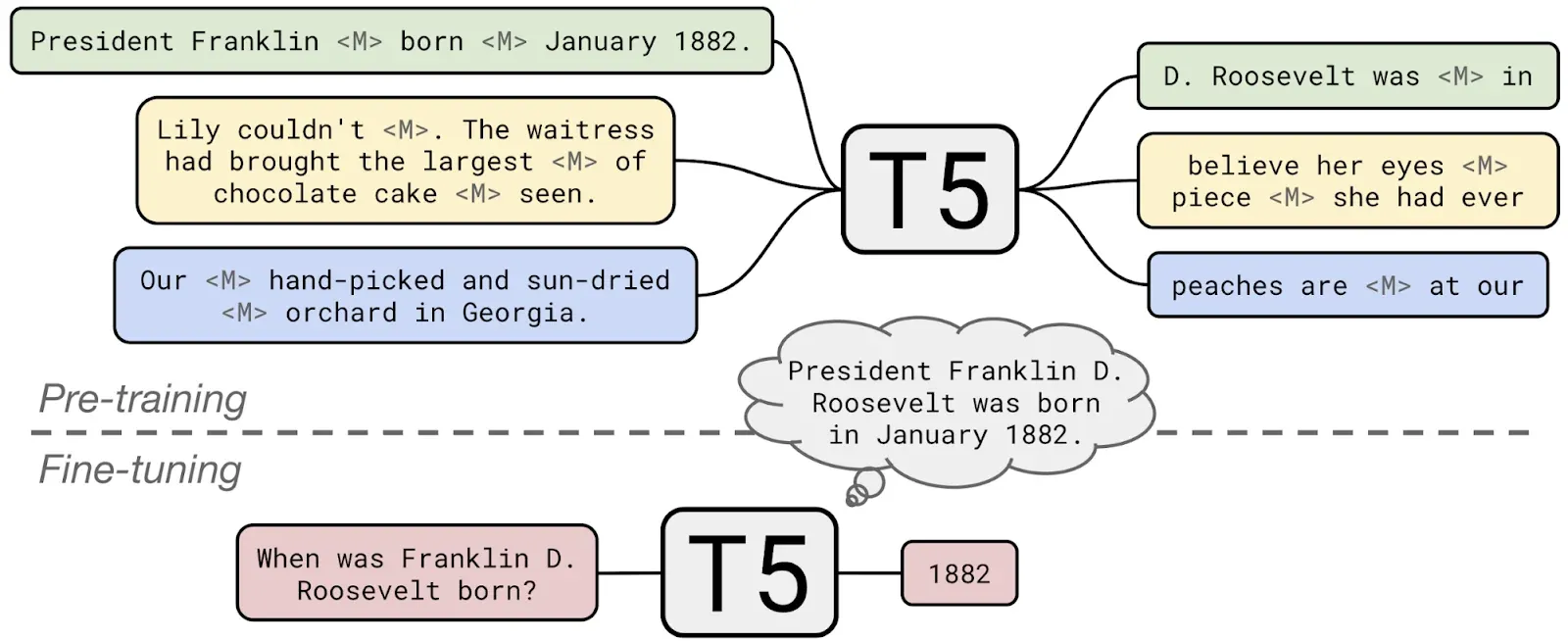
T5, or Text-to-Text Transfer Transformer, is another transformer model that takes the concept of natural language processing to a new level.
It handles various natural language tasks as "text-to-text" transformations, generating responses based on a particular input.
5's biggest advantage is its ability to combine several natural language capabilities, including language modeling, translation, and summarization, making it one of the most versatile transformer models to data
The key is picking the right architecture for your needs.
Pay Attention to Attention
The key innovation that sets transformer models apart is their fabulous attention mechanisms.
Let's dive deeper into how they work their magic!
In a nutshell, attention is how a transformer model decides which parts of its input to focus on. It lets the model pay closer attention to the most relevant data points.
There are a few different flavors of attention that each have their own flair:
Self-Attention and others
- Self-attention: The model attends to different positions within a single sequence. Great for capturing intra-sequence relationships.
- Cross-attention: The model attends between sequences, like between the input and output. Very useful for encoding-decoding tasks.
- Bi-directional attention: The model attends both forwards and backward. Helps the model understand the full context.
Each approach has its own set of strengths and weaknesses.
The critical point, for now, is that attention is the special sauce that allows transformer models to achieve new heights of performance. Pay close attention to attention when selecting your architecture
Alright, time to shift our focus to another critical transformer topic - pretraining. Let's go!
Should You Pre-train or Not Pre-train Transformer Model?
Alright, time to talk pre-training!
Many transformer models come pretrained, meaning they were already trained on a large dataset before you get your hands on them. But is starting from a pretrained model the right choice? Let's discuss.
Pretrained models can give you a solid head start. Since they were already trained on tons of data, they come packed with useful knowledge about language. This can help them better understand your specific data.
But pretraining isn't necessarily a shortcut to success. You need lots of data and computing power to pre-train a model properly. And you still have to fine-tune the model on your end task anyway.
Here's a quick cheat sheet on when pretraining makes sense:
- Limited data or compute? Pretrained models are your friend.
- Want to customize with your own data? Training from scratch may be better.
- Require high performance quickly? Pretrained has the edge.
Finding the Right Fit
There's no universally best option. Choose pretraining or training from scratch based on your specific needs and constraints. The important thing is setting your transformer model up for success!
Alright, time to move on to our next hot topic - multimodal transformers! I promise, no confusing jargon here. Let's keep things simple and have some fun!
Going Multimodal
So far we've focused on transformer models that handle boring old text. But did you know some transformers have expanded beyond natural language processing into other modalities like images, audio, and video?
Let's learn about these multimodal models!
In a nutshell, multimodal transformers can process and connect data from different modes or types.
For example, a multimodal model could generate an image caption by understanding the relationships between text and images.
Some well-known multimodal transformers include VL-Transformer for combining vision and language, DALL-E for text-to-image generation, and Must for speech translation.
When Multimodal Makes Sense
These models excel at tasks that require understanding connections across different data types, like:
- Image/video captioning
- Visual question answering
- Multimedia retrieval
The downside is multimodal models require lots of training data from different modalities.
If your use case involves multiple data types, multimodal transformers are worth exploring! But for most NLP tasks, text-only models still reign supreme.
Alright, next up: deployment options!
Where to deploy Transformer Models: Cloud or Local?
You've picked the perfect transformer model for your needs. But now it's time to decide: should you use a cloud service or deploy it locally? Let's compare the options!
Cloud services like HuggingFace are super easy to use. Just spin up your model with a few clicks and start queries. But this convenience comes at a cost - you pay for computing time and aren't in full control.
Local deployment takes more effort upfront. You need the hardware and engineering resources to serve the model efficiently. But you get more customization, and control, and can potentially save on operating costs long-term.
Finding the Right Fit
Here's a simple framework for deciding:
- Small scale or getting started? Go cloud!
- Tight budget or advanced needs? Local deployment.
- Unsure about usage? Try the cloud first before investing in local.
There's no one-size-fits-all best deployment approach. Assess your resources, needs, and constraints to choose what makes sense for your situation.
Alright, we covered a lot of ground! Let's keep up the pace and dive into fine-tuning tips next. This is where we'll really maximize transformer performance. Get pumped!
Tuning Tips and Tricks
We've got our transformer model picked out and deployed. Now it's time for the fun part - tuning! Fine-tuning is how we customize the model for our specific task. Here are some pro tips:
- Start with a low learning rate - transformers are sensitive! Gradually increase it.
- Train with mixed precision - reduces memory usage and speeds things up.
- Use checkpoint averaging - averages last checkpoints to improve robustness.
- Play with discriminator fine-tuning - trains certain layers more than others.
- Try adapter modules - lightweight add-ons for quickly personalizing models.
Getting the Best Performance
There are lots of techniques for getting the most out of your model. The key is experimenting to find the perfect tuning formula for your dataset and use case.
Remember that tuning is an iterative process. Analyze performance after each test, adjust techniques, and repeat until you maximize those metrics!
We're in the home stretch now. Just a few more topics left before you become a transformer pro! Let's keep up the momentum.
Evaluating Your Model
You've trained your transformer model and are ready to see how it performs. But how do you actually evaluate those results? Let's break it down.
\, F1 score, perplexity, and BLEU for translation models. These quantify how correct the model's predictions are.
But don't just rely on metrics alone. It's also important to:
- Perform error analysis - Check examples the model gets wrong and spot patterns.
- Assess human readers - Get qualitative human feedback on output quality.
- Try model variations - Evaluate different architectures/hypers.
Iterating and Improving
Evaluation should guide the next phase of model improvement:
- Fix data issues revealed by error analysis.
- Retrain with feedback from human readers.
- Run new experiments based on model variations.
It's an iterative cycle - evaluate, analyze, adjust, repeat! This is how you refine the model and achieve the best transformer for your use case.
We're almost at the finish line! Just need to recap the past and take a sneak peek into the future. Let's go!
The Past, Present, and Future of Transformers
Transformers exploded onto the scene in 2017, revolutionizing sequence modeling tasks like translation and language modeling.
Today, they power cutting-edge NLP and are expanding into computer vision, audio, chemistry, and more. Models continue to rapidly grow in size and capability.
The future may bring enhancements like sparse attention and multi-agent coordination, unlocking even more applications. However, challenges around bias, interpretability and environmental impact must also be addressed as transformers advance.
While the road ahead is unclear, transformers are likely to remain integral to ML innovation for years to come through new techniques that usher in the next generation of intelligent systems.
A Quick Recap
We've covered everything you need to select the best transformer model for your needs. Let's recap the key takeaways:
- Understand model architectures and attention mechanisms
- Match models to your specific use case
- Fine-tune and optimize model performance
- Continuously evaluate and improve through iterations
Applying these tips will empower you to leverage transformers to their full potential. The world of NLP is being revolutionized - and you now have the knowledge to take part!
Before you pick your perfect model, we'd like to introduce you to our friend BotPenguin. BotPenguin is an omnichannel chatbot that connects you with customers across any platform.
With advanced NLP and conversational AI, BotPenguin strikes the perfect balance between automation and personalization. BotPenguin integrates with Open AI’s API. It can handle high-volume, repetitive queries so your team can focus on complex issues.
BotPenguin was designed to be flexible, easy to use, and integrate seamlessly with your existing tools. We handle the technical complexity behind the scenes so you can focus on delighting customers.
As this guide equips you to implement transformers, BotPenguin equips you to transform customer engagement. Why not try it and take your business to the next level? We can't wait to automate and enhance your customer experience!
Frequently Asked Questions (FAQs)
What is a Transformer model, and why are they so popular in AI?
Transformers are a type of neural network architecture that revolutionized AI with their powerful self-attention mechanism and encoder-decoder design.
They excel in various tasks, making them highly versatile and popular in the AI community.
What factors should I consider when choosing a Transformer model?
Choosing the right Transformer involves assessing your task requirements, model size, available training data, and computational resources. It's like finding the perfect puzzle piece that fits your AI project seamlessly.
What are the benefits of using a pre-trained Transformer model?
Pre-trained models come with a wealth of knowledge from extensive data and can be fine-tuned for your specific task, saving time and resources. Think of them as expert consultants you can tailor to your needs.
How can I evaluate the performance of a Transformer model?
Evaluation metrics differ based on tasks, like accuracy for NLP and precision-recall for computer vision. Understanding these metrics helps gauge your model's effectiveness and ensures it's delivering the desired results.
What are the common challenges and pitfalls to avoid when working with Transformer models?
Challenges like data sparsity, OOV issues, and memory constraints require creative solutions, such as data augmentation and robust tokenization, to ensure smooth AI operations.

