
Transformer Models in Deep Learning: Latest Advancements
Updated at May 9, 2026
7 min to read
Transformers are the neural networks that analyze relationships between words/tokens using an attention mechanism for AI. The Transformer model allows the understanding of language context and complexity, unlike previous models.
In 2022, 90% of AI projects leveraged transformers, up from just 5% in 2019 per PapersWithCode. One of the popular GPT-3 transformer models boasts 175 billion parameters - surpassing humans' 86 billion neurons as some measure intelligence.
Transformers can digest massive datasets during training, extracting nuanced patterns and correlations. The resulting models like the GPT-3 generate remarkably human-like text - a breakthrough called few-shot learning. With just a text prompt, they can compose songs, explain quantum physics, or recommend Netflix films.
Transformers are triggering an AI renaissance. So knowing how the transformer model works will help you in the long run.
So continue reading to know more about transformer models.
Transformer Models are a class of neural network architectures that revolutionized the field of natural language processing (NLP) and more. These models, unlike traditional recurrent neural networks (RNNs), leverage the power of attention mechanisms to process sequences of data more efficiently.
Before Transformers entered the scene, RNNs were the go-to choice for sequence tasks. However, they suffered from long-term dependency issues and were computationally expensive. Transformers, with their self-attention mechanism, addressed these limitations.
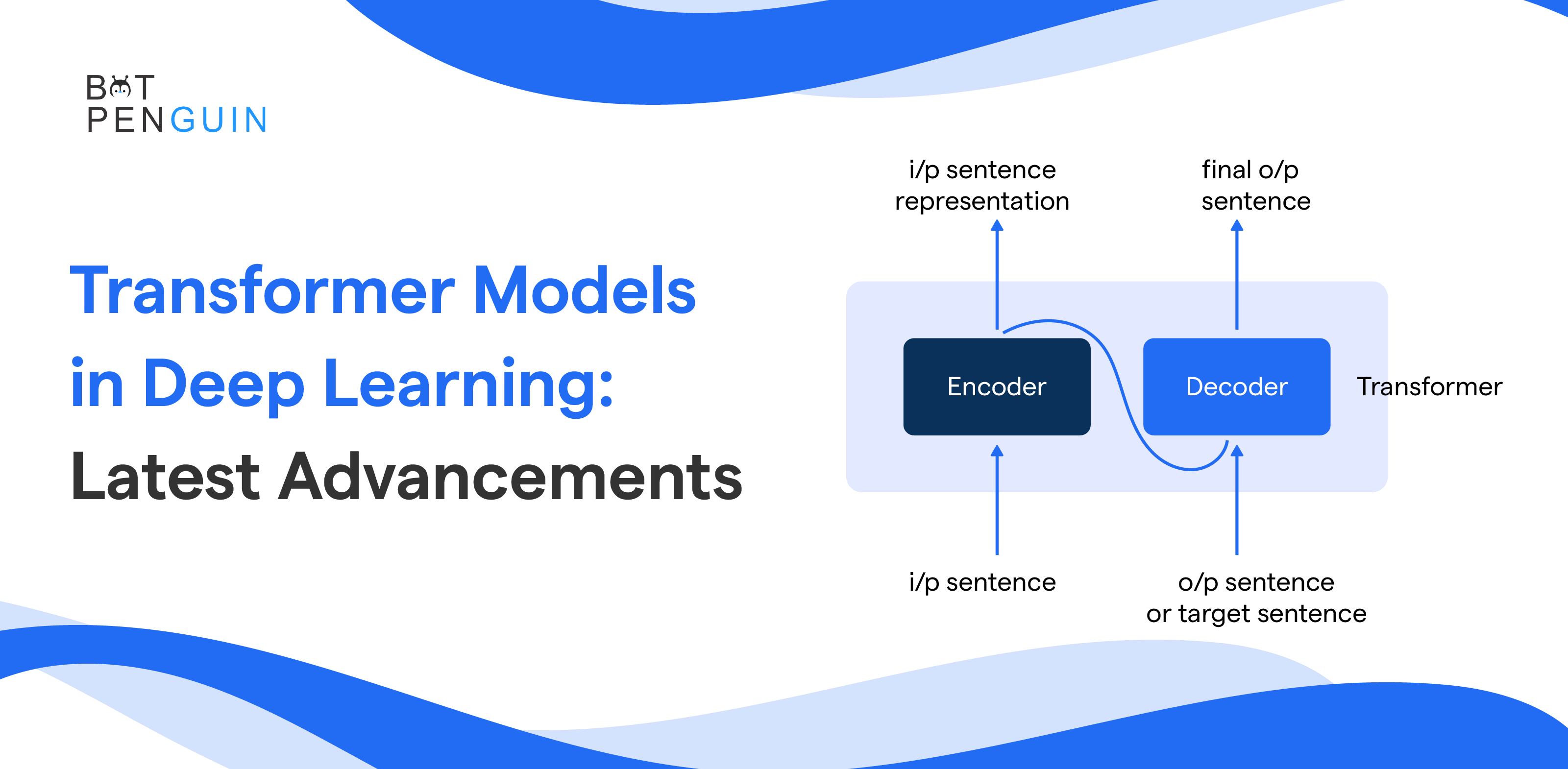
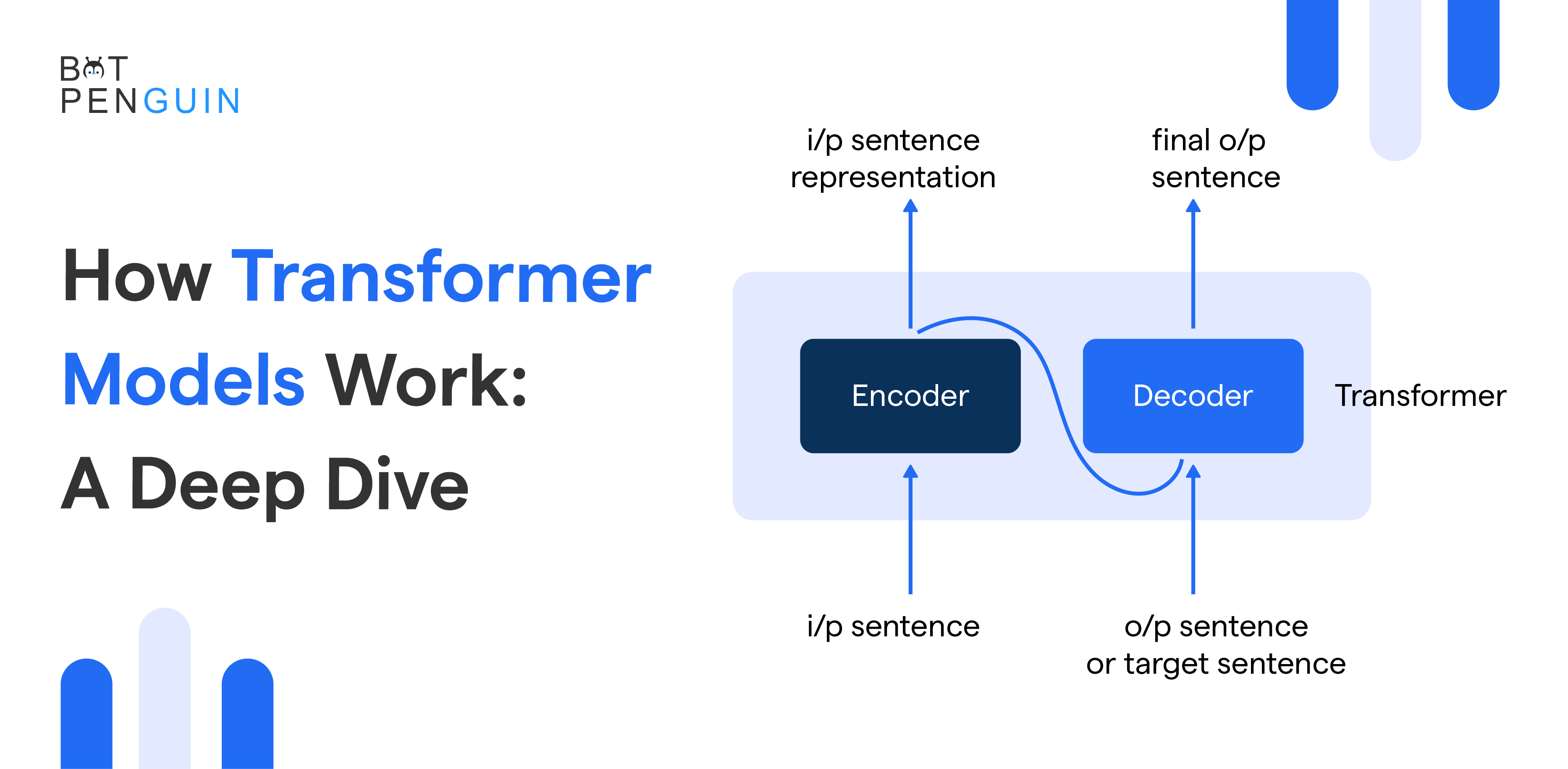
The key components of Transformer Models include the self-attention mechanism, encoder-decoder structure, and feedforward neural networks.
The self-attention mechanism allows the model to weigh the significance of different words in a sentence. Meanwhile the encoder-decoder structure enables tasks like machine translation.
Automate your various domains, Try BotPenguin
Here's an overview of why Transformer models are considered path-breaking in today's day and age.
The introduction of self-attention mechanisms in Transformer Models allows for parallelization during training, making them blazingly fast and efficient. This scalability is a game-changer.
As it enables the training of massive models on huge datasets without draining your patience.
Remember the days when RNNs struggled with long sentences, and their memory faded like an old photograph album? Well, fret no more! Transformer Models ace long-term dependencies with their self-attention magic. It captures relationships between words across extensive contexts.
Transformer models are utilized both indirectly and directly across research, technology, business, and consumer domains due to their ability to understand language.
Adoption is accelerating as capabilities improve and access expands through APIs and apps. The transformer revolution touches virtually every field involving language or text data.
Transformer Models have found their way into diverse industries, from healthcare and finance to entertainment and education. Their versatility and adaptability make them a go-to solution for various AI-driven applications.
Some uses cases are the following:
Natural language processing (NLP) has been transformed by the advent of transformer models. By analyzing semantic relationships between words and global contexts within sentences or documents, transformers achieve state-of-the-art results across NLP tasks.
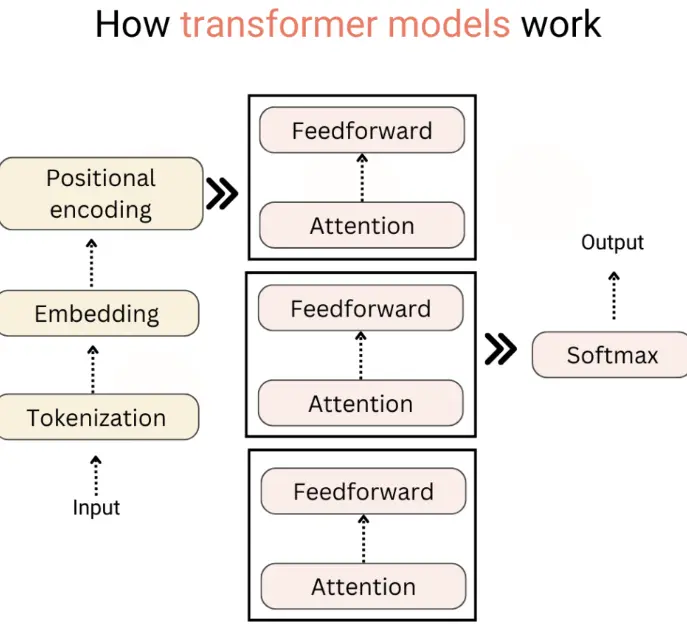
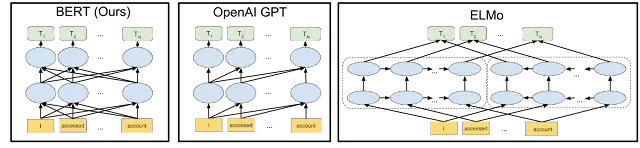
NLP Transformer Models, like the famous BERT, GPT, and T5, have earned their stripes by grasping the meaning and context of words. It is possible due to their revolutionary self-attention mechanism!
Meet the masters of NLP Transformer Models:
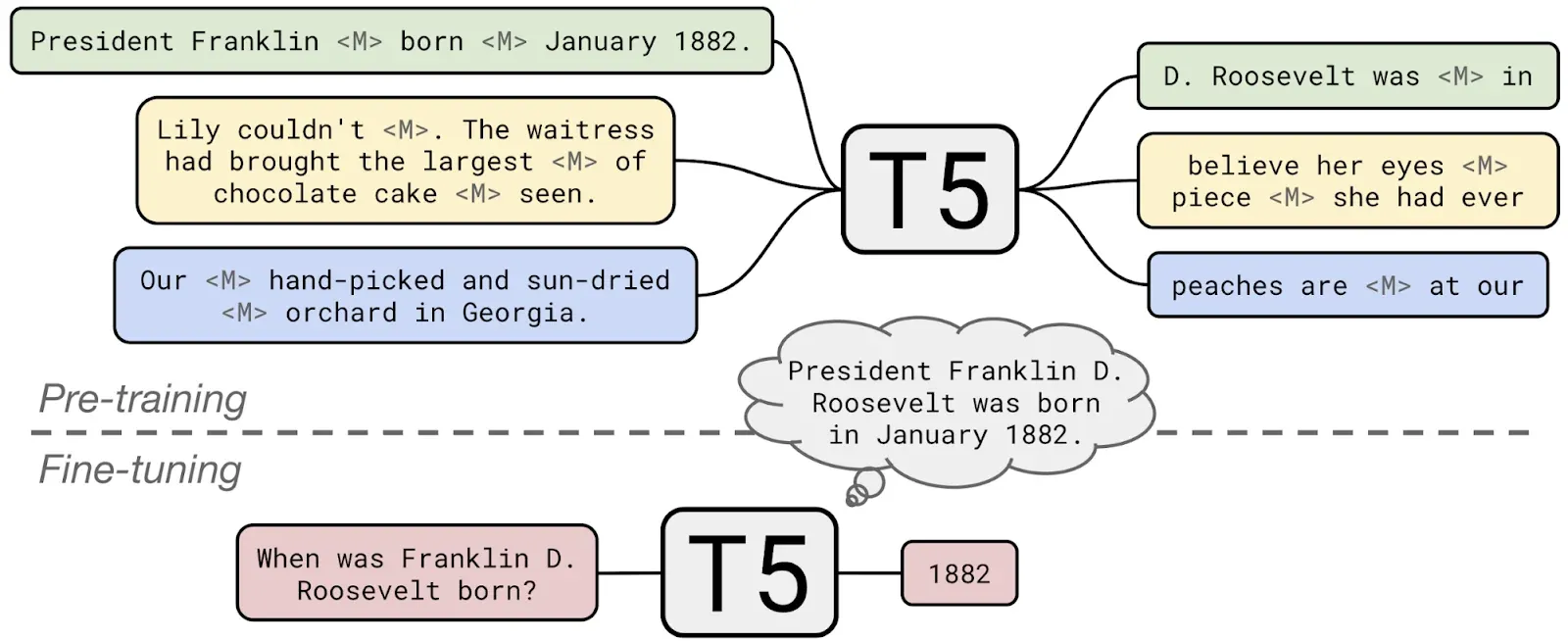
Here are some guidelines on when to use transformer models versus other machine-learning approaches:
If you're dealing with language-dependent tasks, like language translation, sentiment analysis, or text summarization, Transformer Models is the right choice.
They ace these tasks by understanding the contextual relationships between words, something traditional models often struggle with.
Does your dataset span the size of the entire internet? Fear not, Transformers can handle large datasets with finesse. Their scalability and parallelization prowess allow you to process massive datasets without the usual hair-pulling and desk-banging.
Remember those long sentences that sent traditional models running for the hills? Well, Transformers have no fear! They're champions at capturing long-term dependencies, making them the perfect choice for tasks involving lengthy texts.
With a wide range of pre-trained Transformer Models available, you can choose the one that best fits your needs and fine-tune it for your specific task. It's like having a personal AI tailor at your service!
Here is a quick overview of how transformer models like BERT and GPT-3 work
Self-attention relates all positions to every other position using queries, keys, and values to build context-rich representations of the sequence.
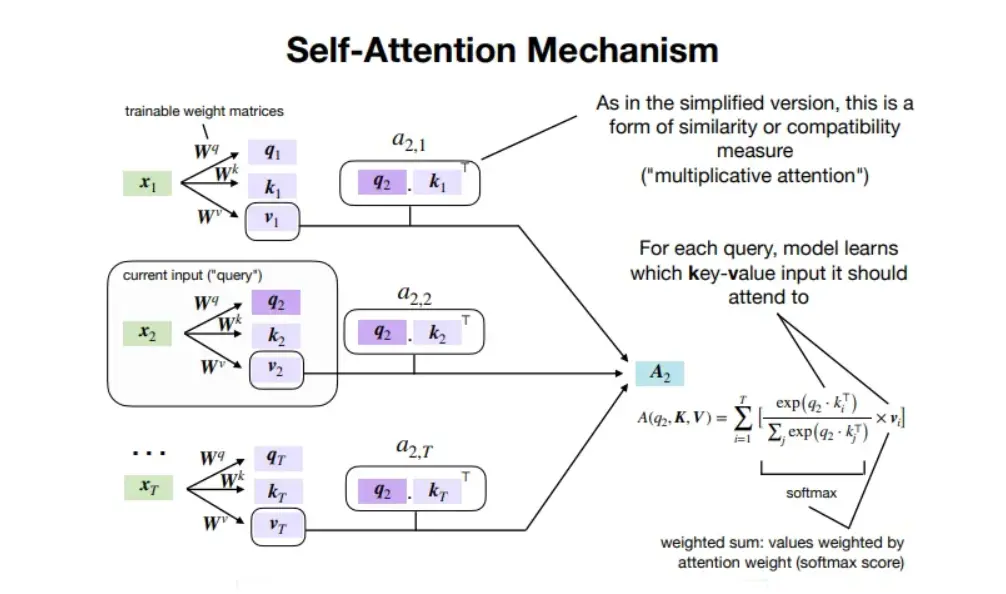
The self-attention mechanism calculates attention scores, deciding which words should receive more focus in a given context. And it's all done through the magical softmax function!
Multi-head attention looks at the input from a different perspective. It adds layers of depth and understanding to our language treasure.
Here are some key challenges and limitations of transformer models:
Transformers demand hefty computational power and memory, especially with large models.
Transformers must brave the perils of overfitting. Striking the right balance between model complexity and data size is the key to ensure smooth generalization.
No challenge is too big for the AI community. There are many research-backed strategies and mitigation techniques that AI researchers are using to tame these challenges and propel the field forward.
Here is an overview of transformer model advancements and applications in deep learning:
The key innovations are the following:
The notable models are the following:
The application of training models in deep learning are the following:
The future outlook of transformer models in deep learning are the following:
Transformer models have captivated imaginations with their ability to analyze, generate, and reason about language at an unprecedented level.
What began as an AI architecture tailored for natural language processing now promises to reshape education, healthcare, business, the arts, and fields we can scarcely imagine.
Their prowess stretches from chatbots conversing naturally to models identifying promising new molecules and materials.
BotPenguin is a chatbot development platform that uses transformer models to power its chatbots. BotPenguin also offers several features that make it easy to build and deploy chatbots using transformer models. These features include a drag-and-drop chatbot builder, a pre-trained model, a deployment dashboard, etc.
Using BotPenguin, you can quickly and easily build chatbots that are powered by transformer models. Challenges around efficiency, ethics, and transparency remain. But the momentum behind transformers is undeniable.
Transformer Models are advanced neural network architectures for sequential data, like text. Unlike traditional RNNs, Transformers use self-attention for parallel processing, capturing long-range dependencies efficiently.
The self-attention mechanism calculates attention scores for each word based on its relation to other words in the sequence, allowing the model to focus on important contexts.
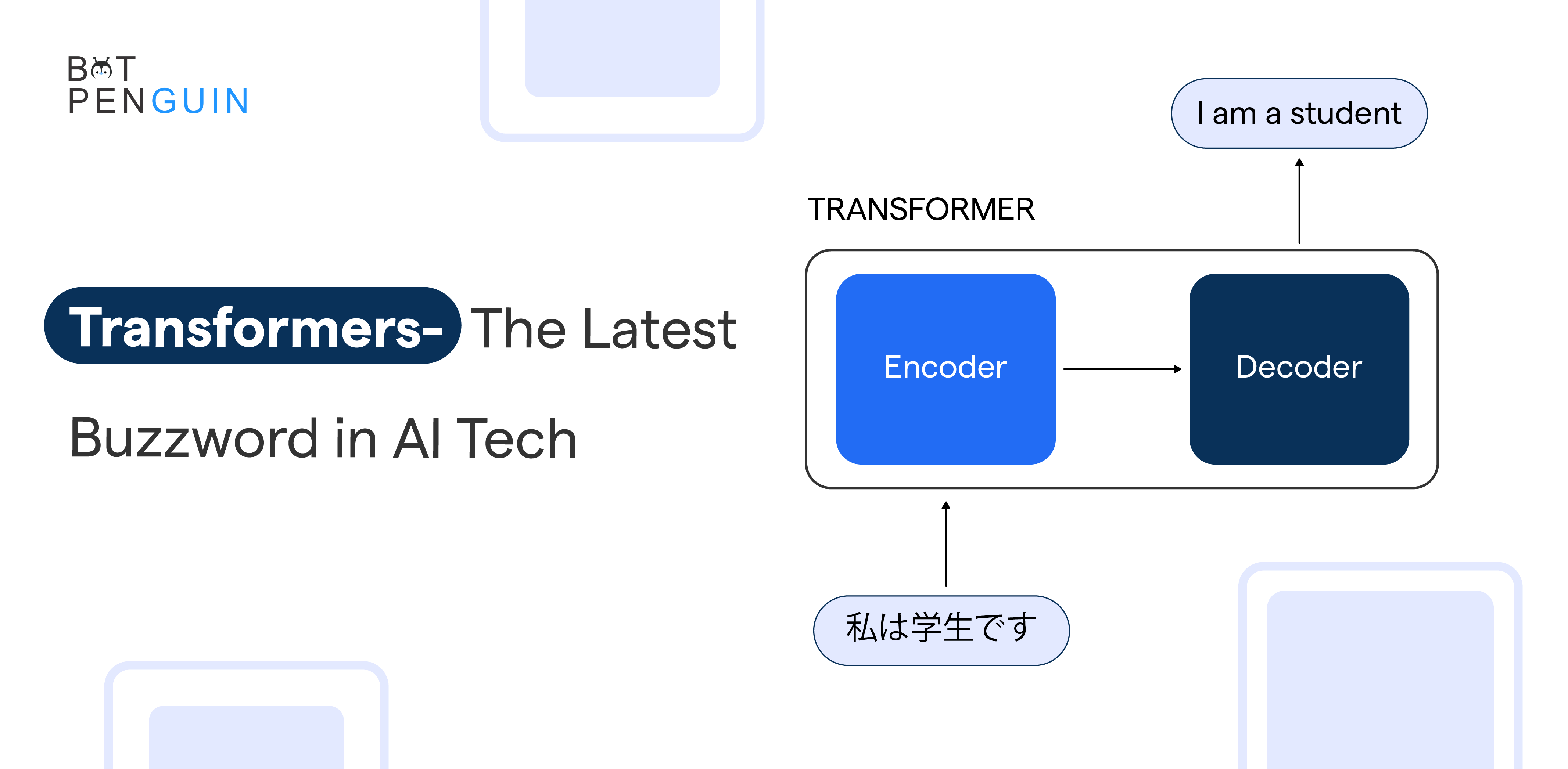
The encoder processes input and generates contextual embeddings. The decoder uses these embeddings to generate the output sequence, ideal for tasks like machine translation.
Padding and masking ensure uniform sequence length. The padding adds special tokens, and masking prevents attention to padded tokens.
Large models demand significant computational power and memory. Quadratic complexity in the self-attention mechanism is a challenge being addressed.
Subscribe to Our Newsletter
Get the latest business insights straight into your inbox.
Checkout our related blogs you will love.
Updated at May 9, 2026
7 min to read
Updated at Jun 21, 2023
10 min to read

Updated at Jul 3, 2026
15 min to read

Updated at Jul 3, 2026
10 min to read

Updated at Jul 1, 2026
16 min to read
Updated at Jun 30, 2026
3 min to read
Table of Contents