

10 Best Tools for Fine Tuning Machine Learning Models
Updated at Jun 22, 2026
9 min to read
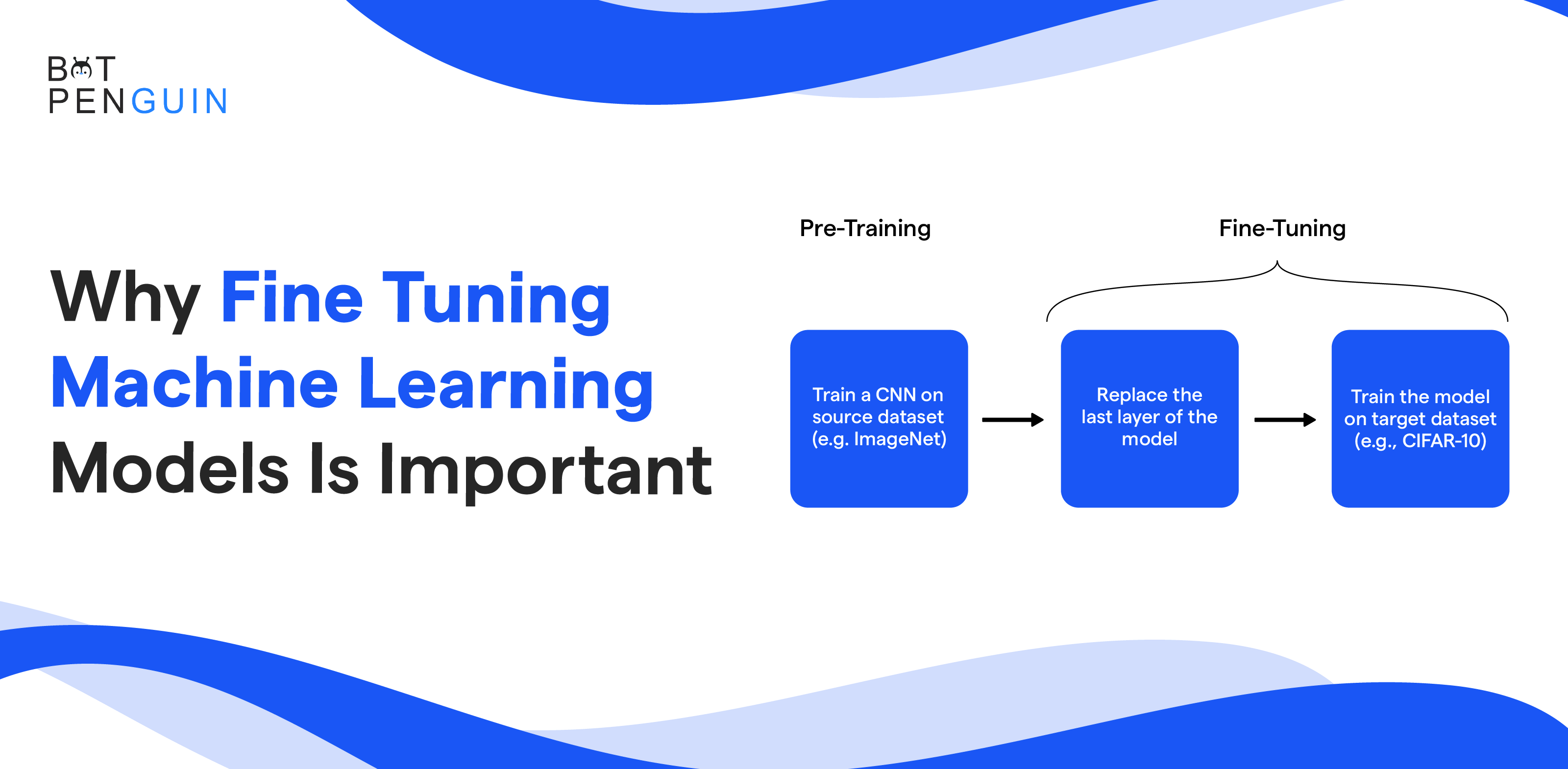
The advent of transfer learning has been a game changer in democratizing access to performant deep learning models, even with limited data.
Yet effectively adapting these large pre-trained models across various tasks requires fine-tuning - an elegant technique to customize models for superior precision without extensive re-engineering.
According to a study by Google AI, fine-tuning can improve the performance of large language models (LLMs) by up to 10% on various natural language tasks.
Machine learning models learn from data and algorithms to make predictions, but picking and training a model doesn't guarantee the best results.
Fine-tuning is crucial. It tweaks a model's settings to improve its performance. This adjustment involves changing parameters and settings based on the task.
Fine-tuning adapts an existing pre-trained model to fit a specific job. It's efficient, saving time and resources compared to making a new model.
Transfer learning is a common method. It uses fine-tuned pre-trained models to solve real-world problems like image sorting, language understanding, or speech recognition.
This guide illuminates the multifaceted performance gains and efficiency unlocked by understanding best practices in fine-tuning vision, language, and speech models.
Discover how to efficiently morph a single foundation into highly accurate tailored solutions spanning diverse ML challenges.
While model parameters capture the relationships in the data, hyperparameters control model flexibility and performance.
Fine-tuning involves adjusting parameters and hyperparameters to optimize the model for a specific task and achieve the desired performance.
The next section will explore the benefits of fine-tuning machine learning models.
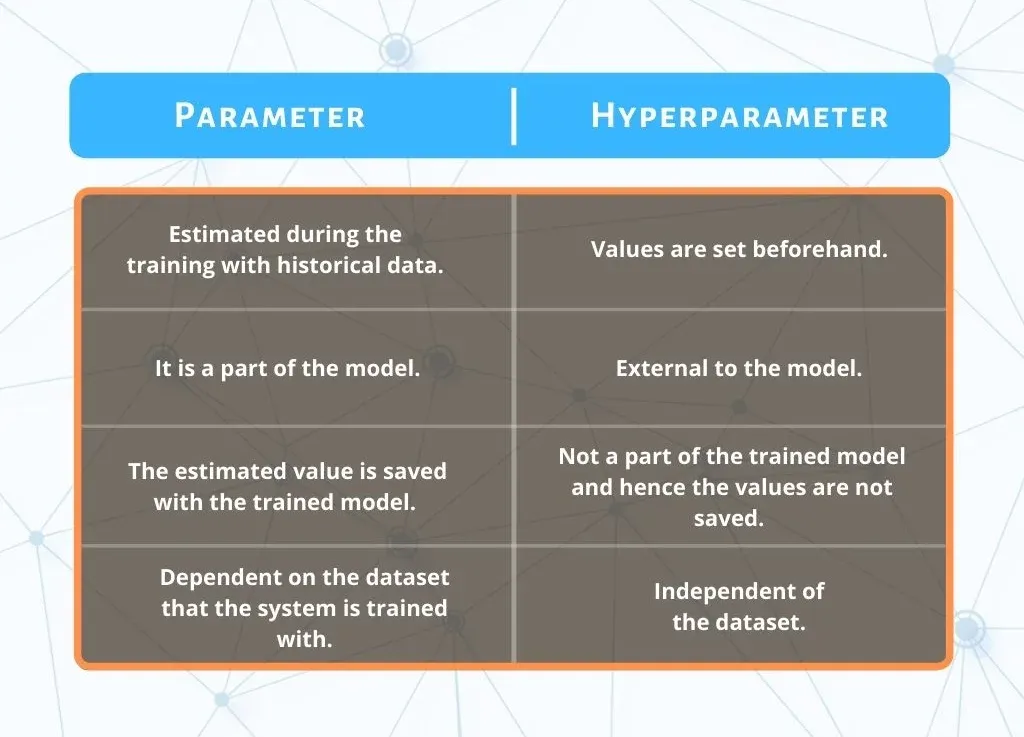
In machine learning, it's important to understand the distinction between model parameters and hyperparameters.
Model parameters are internal variables learned during the training process to capture the relationships in the data. These parameters are adjusted to minimize the difference between the predicted and actual values.
For example, in linear regression, model parameters refer to the coefficients assigned to each feature. In neural networks, parameters include weights and biases.
On the other hand, hyperparameters are external variables that determine the behavior of the learning algorithm.
They are set before the learning process begins and cannot be learned from the data. Hyperparameters control model complexity, regularization, learning rate, number of hidden layers in a neural network, etc.
The selection of hyperparameters significantly impacts model performance but is not directly learned from the data.
Model parameters play a crucial role in capturing the relationships in the data. By adjusting parameters during training, the model can effectively map the input data to the output.
The optimization process aims to find the best values for the parameters that minimize the difference between predicted and actual outcomes.
Proper adjustment of parameters allows the model to generalize well to new, unseen data and make accurate predictions or decisions.
The learning algorithm adjusts the parameters by iteratively updating them based on the training data and the chosen optimization method (e.g., gradient descent).
Hyperparameters have a significant impact on model performance and flexibility. They affect the learning process and determine the overall behavior of the model.
For example, the learning rate hyperparameter controls the step size taken during parameter updates in gradient descent. Choosing an appropriate learning rate ensures convergence and avoids overshooting or slow learning.
Similarly, other hyperparameters like the number of hidden layers in a neural network, regularization strength, and activation functions substantially impact model performance.
Suggested Reading:
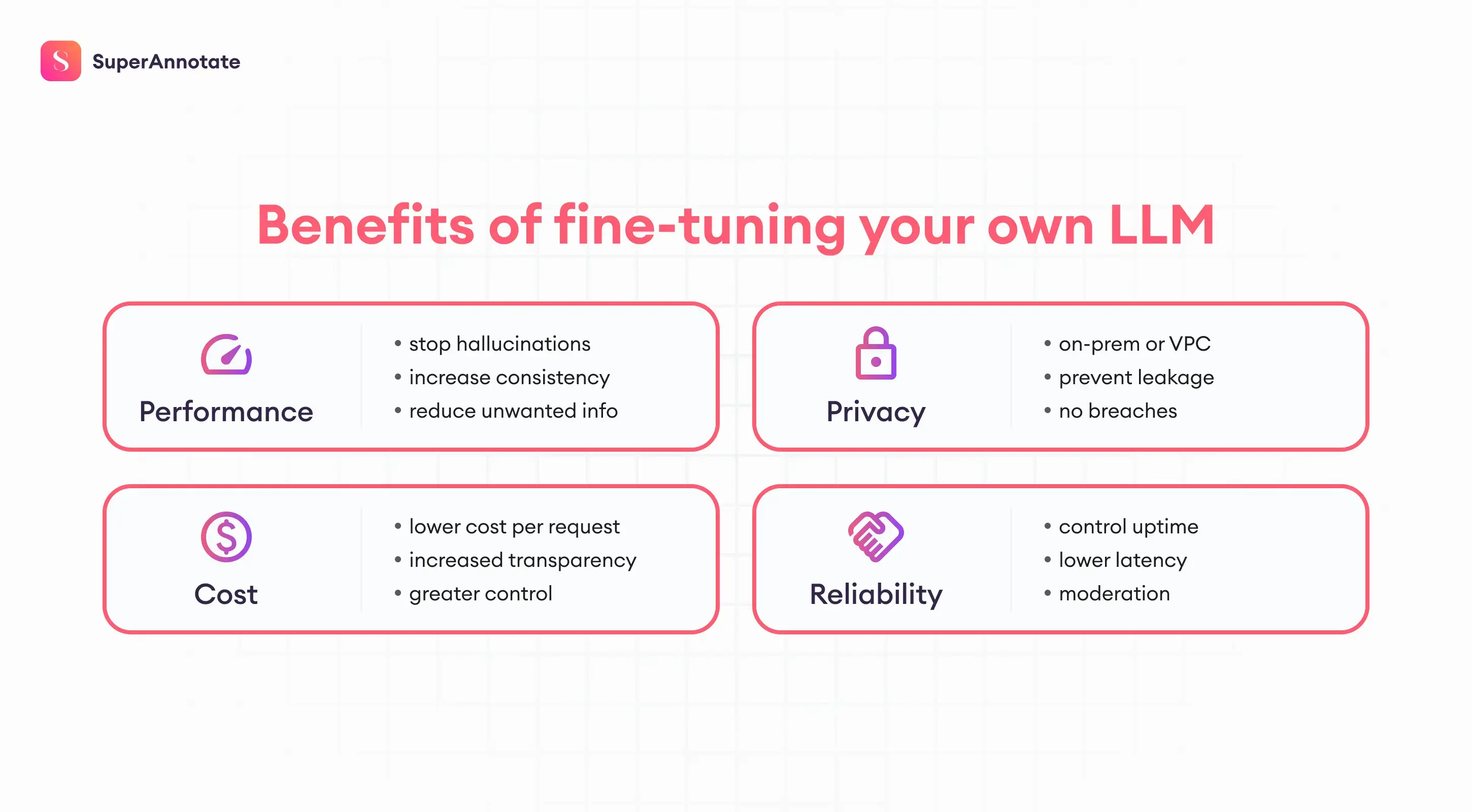
With the benefits of fine-tuning, researchers and practitioners can optimize ML models for specific tasks, achieve higher accuracy and performance, prevent overfitting, and enhance interpretability and explainability.
The next section will explore various techniques for fine-tuning, including regularization techniques and hyperparameter optimization methods.
Fine-tuning ML models offers the benefit of achieving higher accuracy and performance. By adjusting model parameters and hyperparameters, fine-tuning enables the model better to capture the underlying patterns and relationships in the data.
Fine-tuning allows the model to adapt to the specific task, potentially improving model accuracy and ensuring higher performance on new, unseen data.
The model can effectively learn from the available data and make more accurate predictions or decisions through fine-tuning, leading to improved performance metrics such as precision, recall, or F1 score.
Another significant benefit of fine-tuning is improving model generalization by reducing overfitting.
Overfitting occurs when the model becomes too complex and fits the training data too closely, incorporating noise or irrelevant patterns. This can lead to poor performance on new data as the model needs to generalize better.
Fine-tuning allows for regularization techniques, such as L1 or L2 regularization or dropout, which helps prevent overfitting.
Regularization techniques effectively control the complexity of the model, leading to better generalization and improved performance on unseen data.
Fine-tuning can also enhance the interpretability and explainability of ML models. Deep learning models and complex algorithms may be seen as black boxes, making understanding how they arrived at their predictions or decisions difficult.
By fine-tuning, researchers and practitioners can simplify or modify the model architecture, adjust hyperparameters, or introduce specific constraints to render the model more transparent and interpretable.
This is particularly important in fields where interpretability is crucial, such as healthcare, finance, or legal domains, where decisions need to be justified and explained to stakeholders.
Fine-tuning involves various techniques to optimize a pre-trained model for a specific task. Here are some common approaches:
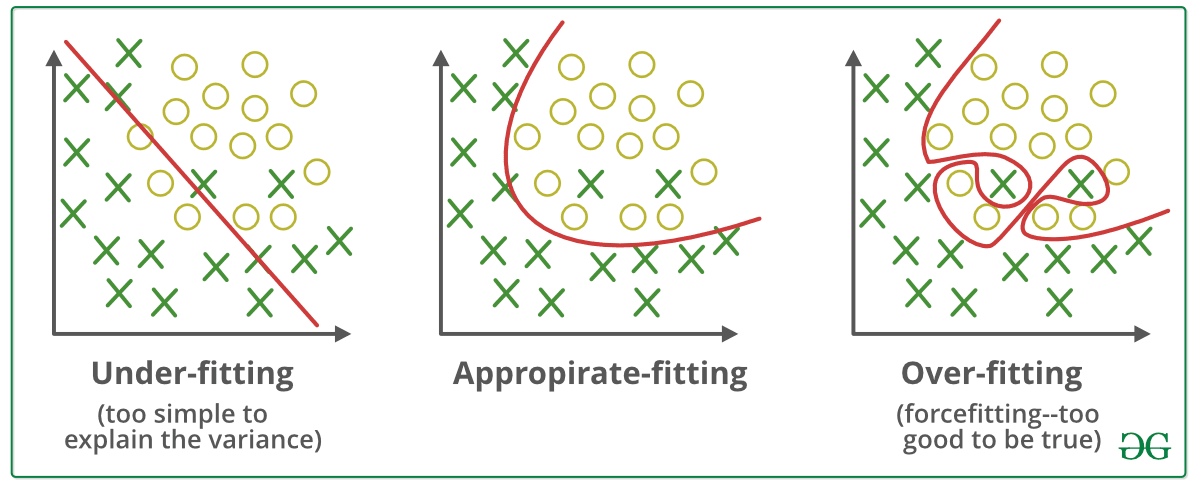
Regularization techniques play a crucial role in preventing overfitting during the fine-tuning process.
Overfitting occurs when the model becomes too complex and fits the training data too closely, resulting in poor generalization to new data.
Regularization helps control model complexity and improves model generalization by adding additional constraints or penalties to the model's loss function. Two commonly used regularization techniques are L1 and L2 regularization.
L1 regularization, also known as Lasso regularization, adds a penalty to the loss function proportional to the absolute value of the model's parameters' weights. This penalty encourages sparsity in the model by forcing some of the weights to become exactly zero, effectively selecting a subset of features. In this way, L1 regularization can prevent overfitting by reducing the model's complexity and improving interpretability.
L2 regularization, also known as Ridge regularization, adds a penalty to the loss function proportional to the squared value of the model's parameters' weights. This penalty encourages smaller weights, smoothing the overall model and reducing the impact of outliers. L2 regularization can help prevent overfitting and improve model generalization by preventing any single feature from having too much influence on the model's predictions.
Another effective regularization technique is dropout regularization. Dropout randomly sets a fraction of the model's activations to zero during training, effectively deactivating these units in the network.
This technique forces the model to learn redundant representations and reduces reliance on a specific subset of features.
Dropout regularization helps prevent model overfitting by increasing the model's robustness and improving generalization.
Hyperparameter optimization methods are crucial for fine-tuning the model and finding the best hyperparameter settings to achieve optimal performance.
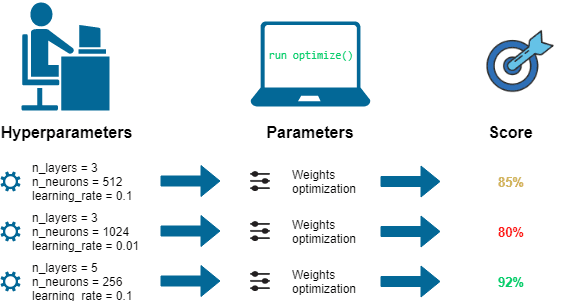
Grid search is a brute-force approach that exhaustively searches a pre-defined hyperparameter space by evaluating each combination. It considers all possible values for each hyperparameter, and the model is trained and evaluated for each combination. Grid search can be computationally expensive but ensures that all possible combinations are explored.
Random search randomly samples hyperparameters from a pre-defined distribution or range of values. This approach does not explore all possible combinations but can be more efficient in finding good hyperparameter settings than grid search. By exploring a subset of the hyperparameter space, random search can discover promising regions more efficiently.
Bayesian optimization is a more advanced method that uses a probabilistic model of the hyperparameter space to decide which hyperparameters to sample next. It learns from previously sampled points and their corresponding model performance to predict the best next point. Bayesian optimization efficiently finds good hyperparameter configurations, especially when the hyperparameter space is large and computationally expensive to explore exhaustively.
Suggested Reading:
Fine-tuning significantly impacts training outcomes in machine learning models. Here's how:
Fine-tuning ML models can significantly impact time and computational resource considerations. Fine-tuning often requires retraining the model on a subset or the entirety of the training data, adjusting hyperparameters, or exploring different regularization techniques.These processes can be computationally intensive, especially for complex models or large datasets. Fine-tuning may increase training time, as more iterations could be needed to optimize the model.
Additionally, fine-tuning may require more computational resources, such as high-performance GPUs or distributed computing infrastructure, to handle the increased computational demands.
Therefore, it is important to consider the available resources and the associated time and cost implications before embarking on extensive fine-tuning.
Fine-tuning involves balancing model complexity and performance. Increasing model complexity, such as adding more layers or parameters, may allow the model to capture more intricate patterns in the data, potentially improving model performance.
However, overly complex models can lead to overfitting, where the model becomes too specialized to the training data and performs poorly on new data.
On the other hand, reducing model complexity may increase generalization but result in lower performance due to the limited capacity to capture important features or patterns. Fine-tuning requires careful consideration of the model complexity-performance trade-off.
Regularization techniques and hyperparameter optimization can strike the right balance and achieve optimal performance while avoiding overfitting.
Fine-tuning can impact the interpretation and understanding of optimized models. Deep learning models and complex algorithms are often considered black boxes, where it may be challenging to ascertain how they arrive at their predictions or decisions.
Fine-tuning the model can involve modifications to the architecture, hyperparameters, or regularization techniques, which may affect the model's behavior and interpretability. It is essential to carefully consider and evaluate the changes introduced during fine-tuning to ensure that the resulting model remains interpretable and understandable.
Techniques like L1 regularization, which can enforce sparsity and feature selection, or dropout regularization, which introduces randomness, can enhance interpretability.
However, it is important to note that fine-tuning may still result in some loss of interpretability, especially for highly complex models, and researchers must strike a balance between performance and interpretability based on the application's specific requirements.
Fine-tuning is a crucial step in machine learning model development that can greatly enhance model performance, generalization, and interpretability.
By adapting models to new tasks or data through adjustments in data, hyperparameters, or regularization techniques, fine-tuning allows models to evolve and improve their accuracy. It helps prevent overfitting, ensures robustness, and enables models to capture relevant patterns and features in the data.
However, fine-tuning requires careful consideration of various factors. Time and computational resource considerations are important, as fine-tuning can be computationally intensive and resource-demanding.
Researchers must carefully plan and allocate the necessary resources to achieve optimal results while managing time and cost constraints.
Suggested Reading:
Why Machine Learning Development is Pivotal for Your Business?
Fine-tuning is important because it allows models to adapt to new tasks or data, improving their performance and accuracy. It helps prevent overfitting, ensures robustness, and enables models to capture relevant patterns and features in the data.
Fine-tuning enables models to optimize performance by adjusting hyperparameters, incorporating new data, or applying regularization techniques. It helps models adapt to specific tasks or contexts, improving their accuracy and ability to generalize to unseen data.
Fine-tuning offers several benefits, including improved model accuracy, reduced overfitting, better capture of important patterns, and increased generalization to new data. It allows models to adapt to changing tasks or data, enhancing performance.
While fine-tuning may impact interpretability, techniques like regularization and hyperparameter optimization can strike a balance between performance and interpretability. Careful consideration of changes introduced during fine-tuning can enhance the interpretability of optimized models.
Fine-tuning can be computationally intensive and require high-performance GPUs or distributed computing infrastructure. Adequate time and computational resources must be allocated to run the fine-tuning process efficiently and effectively.
The frequency of fine-tuning depends on the specific application and the availability of new relevant data. ML models should be regularly monitored and updated to ensure that they remain effective and up-to-date for the tasks they are designed to perform.
Subscribe to Our Newsletter
Get the latest business insights straight into your inbox.
Checkout our related blogs you will love.
Updated at Jun 22, 2026
9 min to read

Updated at May 7, 2026
9 min to read

Updated at May 4, 2026
13 min to read

Updated at Jul 3, 2026
15 min to read

Updated at Jul 3, 2026
10 min to read

Updated at Jul 1, 2026
16 min to read
Table of Contents