

Have you ever thought about how computers understand human language? Natural language processing (NLP) is a field of AI that allows machines to read, understand, and derive meaning from human language.
spaCy is a popular open-source NLP library that makes working with NLP tasks simple and intuitive.
Keep reading to understand how spaCy works under the hood to perform powerful NLP tasks with just a few lines of code.
We will explore spaCy features like tokenization, part-of-speech tagging, named entity recognition, and more.
By the end, you will have a solid grasp of the inner workings of this amazing library and be able to leverage its capabilities to add human-like language understanding to your projects.
Read on to demystify NLP and simplify your life with spaCy, start by understanding spaCy!
Understanding spaCy: Definition and Purpose
So, what exactly is spaCy?As we said above, it's an open-source library designed for advanced NLP tasks.
It's fast, efficient, and user-friendly, making it a top choice for developers and researchers.
With spaCy, you can perform a wide range of NLP tasks, such as tokenization, part-of-speech tagging, named entity recognition, and more.
Unlocking the spaCy features
Here are some of the spaCy features:
Lightning-Fast Processing: One of the spaCy features is its incredible speed. It's built with efficiency in mind, allowing you to quickly process large volumes of text. Whether you're analyzing a single document or dealing with massive datasets, spaCy's speed will impress you.
Support for Multiple Languages: spaCy is a multilingual library that supports multiple languages out of the box. Whether you're working with English, German, Spanish, or even lesser-known languages, spaCy has covered you. This versatility makes it a valuable tool for global applications and multilingual projects.
Pre-Trained Models: Another fantastic spaCy feature is its collection of pre-trained models. These models have been trained on vast amounts of data and can be used for various NLP tasks. Whether you need to perform named entity recognition, sentiment analysis, or text classification, spaCy's pre-trained models can save you time and effort.
Now after seeing spaCy features, it's time to see why choose spaCy for NLP.
Why Choose spaCy for NLP?
With so many options, it's hard to choose the right tool. This section will give you an insider's look at why spaCy should be your go-to for natural language processing.
We'll break down how it can save you time and boost your performance, so you can focus on the fun stuff.
Keep reading to find out if spaCy is the solution for you!
High-Performance and Efficient Processing
spaCy's speed and efficiency are unmatched. It's built with Cython, a programming language that compiles Python like code into highly optimized C code.
This means spaCy can process text at lightning speed, making it ideal for real-time applications or scenarios where processing time is crucial.
Support for Multiple Languages
As mentioned earlier, spaCy supports many languages. This is a huge advantage for projects that involve multilingual data or require language-specific processing. With spaCy, you don't have to worry about language barriers hindering your NLP tasks.
Availability of Pre-Trained Models
spaCy has various pre-trained models covering different languages and NLP tasks. These models are trained on massive datasets, allowing them to perform with impressive accuracy.
You can save time and effort training your models from scratch by leveraging these pre-trained models.
Easy Integration with Other Python Libraries
spaCy's compatibility with other Python libraries, such as TensorFlow, makes it a versatile tool for NLP. You can combine the power of spaCy's linguistic features with the deep learning capabilities of TensorFlow, opening up a world of possibilities for advanced NLP tasks.
How Does spaCy Work?
In this section, we'll explore how spaCy handles NLP tasks like tokenization, tagging, and parsing quickly and accurately.
By the end, you'll clearly understand what makes spaCy a powerful tool for any natural language project. Let's get started!
Tokenization
Tokenization is the process of breaking text into individual words or sentences. spaCy features are excels at tokenization, providing accurate and efficient results. It considers language-specific rules and exceptions, ensuring the text is split into meaningful units.
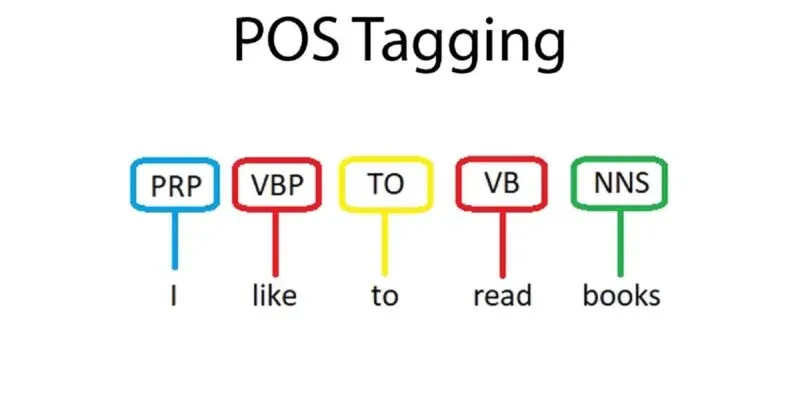
Part-of-Speech (POS) Tagging
POS tagging involves assigning grammatical tags to words in a sentence, such as nouns, verbs, adjectives, etc. spaCy's POS tagging is highly accurate, thanks to its trained models and linguistic algorithms. This information is crucial for many NLP tasks, like syntactic parsing and named entity recognition.
Named Entity Recognition (NER)
NER identifies and classifies named entities in text, such as person names, organizations, locations, and more. spaCy features of NER capabilities are impressive, allowing you to effortlessly extract valuable information from unstructured text.

Dependency Parsing
Dependency parsing involves analyzing the grammatical structure of sentences and determining the relationships between words. spaCy's dependency parser uses machine learning algorithms to parse sentences accurately, providing valuable insights into the syntactic structure.
Lemmatization
Reducing Words to Base or Root Form: Lemmatization reduces words to their base or root form. spaCy's lemmatization capabilities ensure that words are transformed to their canonical form, making it easier to analyze and compare them. This is useful for tasks like text classification and information retrieval.
Now it's time to get started with spaCy! So, why wait just scroll down!
Suggested Reading:
Getting Started with spaCy
Getting started with spaCy is easier than you think. This beginner-friendly guide will have you up and running with Python's leading NLP library in no time.
By the end, you'll be well on your way to building your own NLP applications!
Let's scroll down.
Step 1
Installation and Setup of spaCy
To begin your journey with spaCy, you will first need to install the library and set up your Python environment.
This process is simple. Using your terminal/command prompt, install spaCy using the command "pip install spacy".
This will download spaCy and its dependencies to your system.
You'll also need to download one of spaCy's pre-trained models. For English, use the command "python -m spacy download en_core_web_sm" to download the small model.
Step 2
Loading and Using Pre-Trained Models
spaCy comes with several pre-trained models that are ready to use out of the box. You can load these models into your Python code and immediately start performing NLP tasks.
Import spaCy and load the model you downloaded, for example "en_core_web_sm", using the commands "import spacy" and "nlp = spacy.load('en_core_web_sm')".
Then you can analyze text by creating a document object from text, e.g. "doc = nlp('Hello world')" and accessing tokens, tags etc.
Step 3
Customizing spaCy's Pipeline for Specific Tasks
While the pre-trained models cover many common use cases, you may need to customize spaCy for your unique tasks.
You can modify spaCy's pipeline to suit your needs, for example adding your own components or adjusting existing ones.
While spaCy's pre-trained models are powerful, you may encounter scenarios where you need to fine-tune the library for your specific NLP tasks.
After setting up your spaCy, time to see the advanced techniques with spaCy features!
Advanced Techniques with spaCy
spaCy makes it simple to classify documents, identify entities, parse sentences and more - come learn how these advanced techniques into your work. From training custom model to, Integrating spaCy with Deep Learning Frameworks.
Let's get started!
Training Custom Models with spaCy
If the pre-trained models do not meet your needs, you can train custom models with spaCy.
You will need to prepare labeled training data from your domain. Then define the model architecture and hyperparameters.
spaCy makes it easy to train models on your own data.
Fine-Tuning Pre-Trained Models for Specific Domains
Sometimes the pre-trained models are close but need minor adjustments for your domain. SpaCy allows fine-tuning existing models further.
You can continue training models on your domain data to customize them.
Handling Large Datasets Efficiently
As your projects grow in scale, the dataset size may become large. SpaCy provides techniques to handle big data efficiently.
You can optimize memory usage and process text in batches. It can efficiently make predictions on large corpora.
Integrating spaCy with Deep Learning Frameworks
spaCy integrates well with deep learning frameworks like TensorFlow and PyTorch. You can combine spaCy's NLP features with the power of deep models.
This allows the training of complex neural architectures for advanced natural language understanding.
Wait wait! It's not ending, let’s see the spaCy language model.
spaCy Language Model (LLM)
spaCy's Language Model is a powerful tool that allows you to train and fine-tune your own language models. It provides a flexible framework for building custom models that can understand and generate natural language text.
Whether you're working on text generation, language translation, or chatbot development, spaCy's LLM has got you covered.
Benefits and Use Cases of spaCy LLM
Text Generation: With spaCy LLM, you can generate coherent and contextually relevant text, making it ideal for tasks like content creation, story generation, and dialogue systems.
Language Translation: spaCy LLM can be trained to perform language translation tasks, enabling you to build your own translation models tailored to specific domains or languages.
Chatbot Development: By leveraging spaCy LLM, you can create intelligent chatbots that can respond to user queries in a more natural and human-like manner.
Conclusion
We hope this guide has given you a solid understanding of how spaCy works and all it has to offer for natural language processing.
By leveraging spaCy's speed, pre-trained models, and extensive spaCy features set, you now have a powerful tool to add human-like language abilities to your projects.
Whether you need text analysis, information extraction, or advanced NLP tasks like language generation, spaCy equips you with everything you need to simplify development.
We encourage you to start experimenting with spaCy on your own data to truly experience its capabilities.
Don't stop here - your NLP journey with spaCy has only just begun.
Frequently Asked Questions (FAQs)
What is spaCy and how does it work?
spaCy is an open-source library for Natural Language Processing (NLP) tasks. It works by providing efficient and accurate processing of text, including tokenization, part-of-speech tagging, named entity recognition, and more.
What are the advantages of using spaCy for NLP?
spaCy features offers high-performance processing, support for multiple languages, pre-trained models, and easy integration with other Python libraries like TensorFlow. It simplifies complex NLP tasks and provides accurate results.
How can I get started with spaCy?
To get started with spaCy, you need to install it and load the pre-trained models. You can then use its various functions and methods to perform NLP tasks on your text data.
What are some of the key features of spaCy?
Some key spaCy features include tokenization, part-of-speech tagging, named entity recognition, dependency parsing, lemmatization, word vectors, and text classification.
Can spaCy handle multiple languages?
Yes, spaCy features supports multiple languages. It has pre-trained models for various languages, allowing you to process text in different languages with ease.


