Introduction
"How was your day?"
A simple question from your friend is answerable with the right intent.
But for machines, understanding the meaning behind this everyday language has challenged researchers for decades. Now with breakthroughs in natural language processing, AI is gaining the ability to comprehend not just words but full sentences and contexts.
Recent advances in Natural Language Understanding are accelerating thanks to innovators like Google and Anthropic.
Statistical language models can now analyze text to extract meanings and relationships with over 90% accuracy according to research from Stanford.
What makes this possible?
Massive datasets containing millions of sentences, passages, and documents that train Natural Language Understanding models through deep learning. Any AI assistant's architecture alone was trained on nearly a trillion words!
Natural Language Understanding unlocks new horizons for how machines interpret the complexity of human language.
In this blog post, we will explore how natural language understanding works.
What is Natural Language Understanding?
Natural Language Understanding is a branch of Artificial Intelligence (AI) that focuses on the ability of machines to understand and interpret human language.
While humans can easily understand the nuances, ambiguities, and context of language, it's a complex task for machines.
Get your own deep trained Chatbot with BotPenguin, Sign Up Today!
BotPenguin provides Chatbot creation for different social Platforms-
Key Features of Natural Language Understanding Techniques
In this section, you will find key components of Natural Language Understanding:
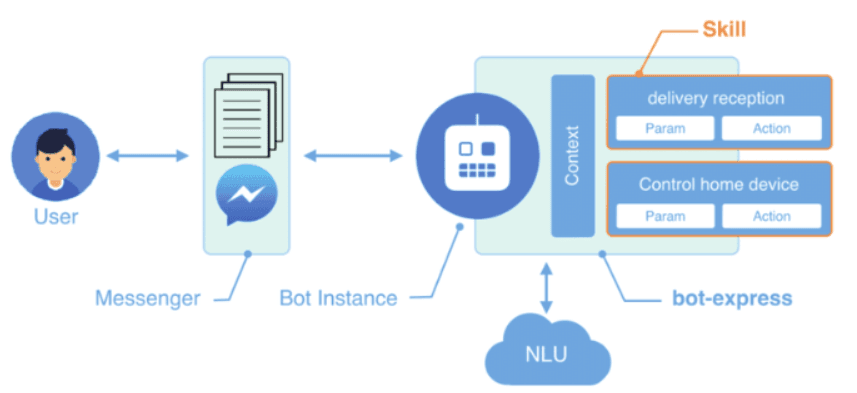
Tokenization
In the world of Natural Language Understanding (NLU), tokenization is a fundamental process that involves breaking down text into smaller, meaningful units called tokens.
Tokens can be individual words, punctuation marks, or even subwords, depending on the language and context.
Tokenization serves as a crucial step in language processing as it sets the foundation for all subsequent analysis and understanding.
Tokenization Techniques in NLU Systems
There are several techniques used in Natural Language Understanding systems for tokenization.
Some systems rely on heuristics and rules to determine the boundaries between tokens, while others utilize machine learning algorithms to learn tokenization patterns from large amounts of training data.
Additionally, tokenization techniques can differ based on the language being processed.
Best Practices in Tokenization and Common Challenges
When it comes to tokenization, some best practices can help ensure accurate and meaningful results. These include considering the context, taking punctuation into account, handling contractions and abbreviations appropriately, and dealing with special cases like hyphenated words.
Balancing efficiency and accuracy in tokenization is an ongoing challenge that NLU systems aim to overcome.
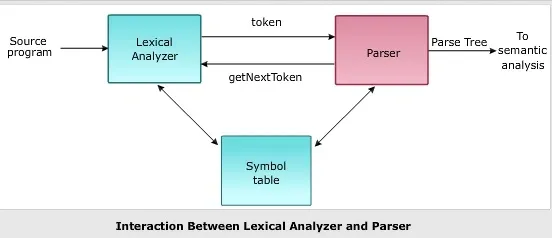
Syntactic Parsing
Syntactic parsing is a key component of Natural Language Understanding that involves analyzing the grammatical structure of sentences.
It helps machines understand how words relate to each other, uncovering the subject, verb, objects, and other syntactic elements in a sentence.

Dependency and Constituency Parsing in NLU Systems
There are two primary approaches to syntactic parsing: dependency parsing and constituency parsing.
- Dependency parsing focuses on understanding the relationships between words in a sentence, represented as directed links or dependencies.
- Constituency parsing, on the other hand, aims to identify the hierarchical structure of a sentence, dividing it into its constituent phases and subphases. Both approaches have their merits and are used in different NLU systems depending on the specific requirements and goals.
Challenges and Limitations of Syntactic Parsing
While syntactic parsing has proven to be immensely valuable in Natural Language Understanding, it also comes with challenges. The ambiguity of natural language poses difficulties, as words can have multiple interpretations and syntactic structures.
Handling complex sentences with embedded clauses, ellipses, and idiomatic expressions can be particularly challenging.
Entity Recognition
Entity recognition is a crucial aspect of NLU that involves identifying and classifying named entities within a piece of text. Named entities can range from people, organizations, and locations to dates, times, and numerical expressions.
Accurately recognizing and categorizing entities is fundamental in extracting relevant information and understanding the context of a text.

Named Entity Recognition (NER) Techniques in NLU Systems
NER techniques in NLU systems utilize various approaches such as rule-based methods, statistical models, and deep learning algorithms. These techniques aim to identify and classify named entities by recognizing patterns, semantic features, and contextual clues.
Suggested Reading:
Named Entity Recognition (NER)
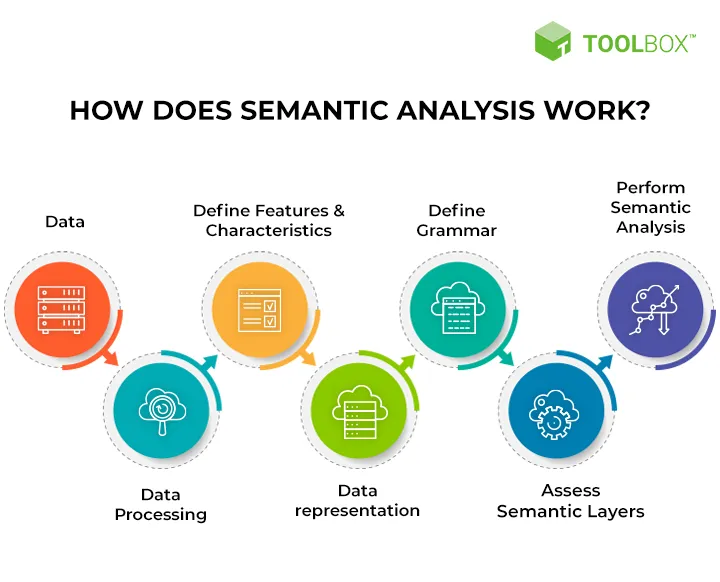
Semantic Analysis
Semantic analysis is a critical component of Natural Language Understanding that focuses on uncovering the meaning and relationships between words and phrases.
It goes beyond syntax to understand the deep meaning and intent behind language, enabling more advanced understanding and interpretation. By analyzing semantic roles and annotating concepts, NLU systems gain a deeper understanding of language and can derive more meaningful insights.
Semantic Role Labeling and Concept Annotation in NLU Systems
Semantic role labeling involves identifying the roles that words or phrases play in a sentence, such as the agent, patient, or location. This labeling provides information about the relationships between words and their respective roles in a particular context.
Concept annotation, on the other hand, involves annotating words or phrases with specific concepts or semantic categories, enabling machines to understand the underlying concepts being expressed.
Challenges and Limitations in Semantic Analysis
Semantic analysis poses challenges in disambiguating word senses, handling context-dependent meanings, and identifying nuanced relationships between words. Additionally, semantic analysis can be impacted by variations in language use, cultural references, and evolving linguistic conventions.
Suggested Reading:
Sentiment Analysis
Sentiment analysis plays a crucial role in Natural Language Understanding (NLU) by uncovering emotions, opinions, and attitudes expressed in a piece of text. It involves analyzing the sentiment behind words and phrases to determine whether they are positive, negative, or neutral.

Techniques for Sentiment Analysis in NLU Systems
NLU systems employ various techniques for sentiment analysis. These include rule-based approaches using lexicons and predefined sentiment lists, machine-learning algorithms that learn from labeled data to classify sentiments, and hybrid methods that combine both rule-based and machine-learning approaches.
Challenges and Approaches in Sentiment Analysis
Sentiment analysis faces several challenges, including sarcasm, irony, and the context-dependent nature of sentiment. Addressing these challenges requires approaches such as context-aware sentiment analysis, which considers the surrounding context to understand the intended sentiment.
Other important tasks in sentiment analysis include aspect-based sentiment analysis. This focuses on identifying sentiments toward specific aspects or features of a product or service Sentiment intensity analysis, which aims to measure the strength of the expressed sentiment.
Suggested Reading:
Unleashing the Power of Natural Language Understanding
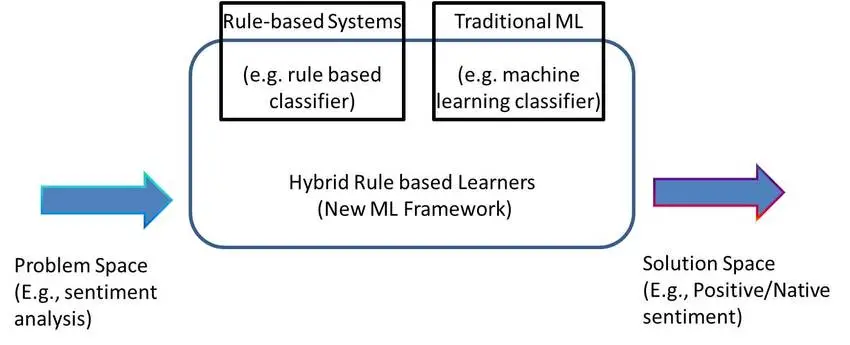
Rule-Based Models in Natural Language Understanding
Rule-based models in NLU operate on predefined linguistic rules and patterns, enabling precise control over language interpretation. They are highly interpretable, customizable, and effective for handling specific domains or languages.
However, rule-based models can be labor-intensive to develop and maintain, requiring manual rule creation and updates. Additionally, they may struggle with generalization and handling language nuances beyond the specified rules.
Regular Expressions and Pattern Matching in Rule-Based Systems
Rule-based systems often rely on regular expressions and pattern matching to identify and extract relevant information from text.
Regular expressions allow for the definition of specific patterns or sequences of characters to match against. It enables the extraction of desired entities, dates, or other structured information.
Pattern matching aids in capturing linguistic patterns that help determine the syntactic structure, sentiment, or intent within the text.
Hybrid Development of Rule-Based Models and Machine Learning
To combine the strengths of both rule-based and machine-learning approaches, hybrid models have been developed in Natural Language Understanding. These models incorporate linguistic rules as well as statistical methods, allowing for improved accuracy and flexibility.
By leveraging both rule-based and machine-learning techniques, hybrid models can handle complex language scenarios while benefiting from data-driven learning and generalization.
Applications of Natural Language Understanding in AI
NLU plays a pivotal role in personal assistants, chatbots, and virtual assistants by enabling them to understand user queries and respond intelligently.
By leveraging sentiment analysis, entity recognition, and semantic analysis, NLU systems facilitate personalized recommendations, provide accurate information, and engage in natural conversations, enhancing the overall user experience.
Speech Recognition and Voice Interfaces
With advancements in speech recognition technology, NLU has become a key component in converting spoken language into text and understanding user intent accurately.
NLU systems analyze the transcriptions of speech and apply techniques like sentiment analysis and intent recognition. This is done to provide a comprehensive understanding of user commands and queries. As it enables voice-controlled interfaces and interactive speech-enabled applications.
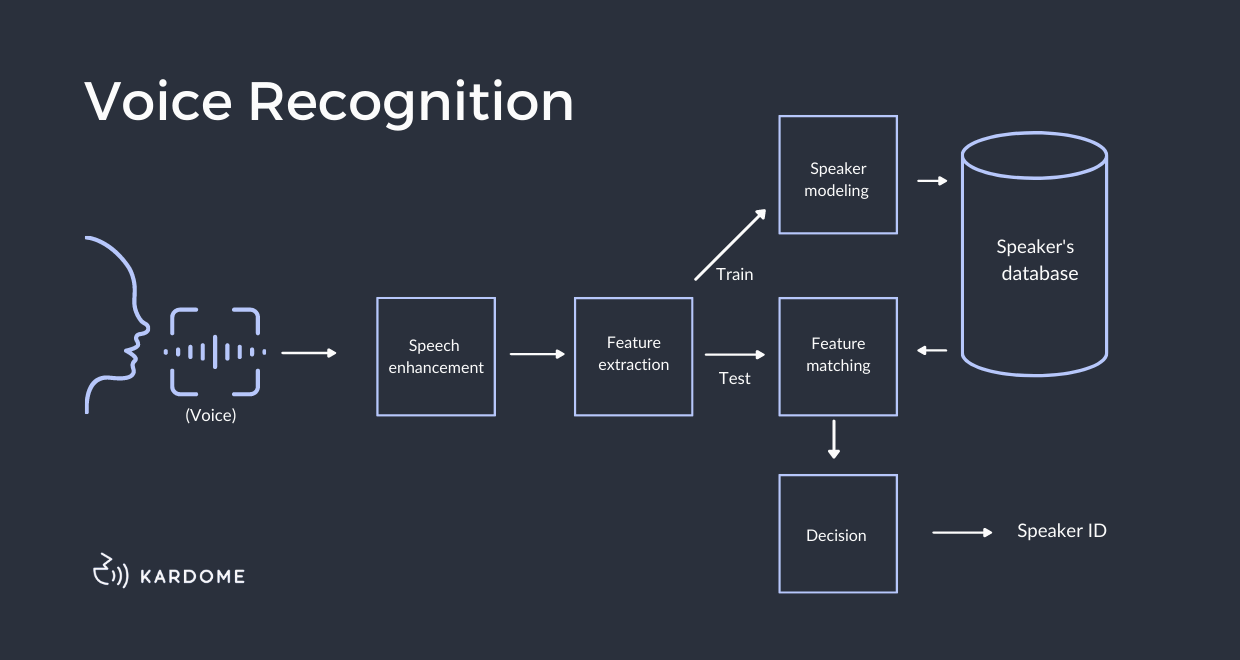
NLU in Machine Translation and Natural Language Programming
NLU is instrumental in machine translation by enabling systems to understand the context, meaning, and intent behind sentences in different languages. This understanding facilitates accurate translations and improves the overall quality of machine translation systems.
Certain top-notch tech companies like BotPenguin use NLP to power their chatbots, making them more efficient and effective at handling customer queries. This helps in moving the customer toward conversion!
Additionally, natural language programming leverages NLU to enable machines to understand and interpret human-like commands, expanding the possibilities for human-machine interaction in software development and automation.
Sentiment Analysis and Opinion Mining for Customer Feedback
NLU allows businesses to analyze customer feedback, reviews, and social media posts to gain insights into customer sentiments and opinions.
By applying sentiment analysis and opinion mining techniques, NLU systems categorize and analyze customer feedback to identify pain points and improve products and services.
Analyzing sentiment helps businesses make data-driven decisions, improve customer relationships, and drive growth.
The Limitations of Natural Language Understanding
Natural Language Understanding (NLU) is a rapidly evolving field with numerous applications, from speech recognition to machine translation. While these strides are impressive, NLU still faces certain challenges.
Difficulties in Comprehending Non-Literal Expressions
One of the biggest challenges of NLU is the ability to comprehend non-literal expressions like idioms, metaphors, and similes. These expressions convey a different meaning from the literal sense of the words used.
For example, “kick the bucket” means “to die” and not to kick a bucket. This poses a challenge for NLU systems as they rely heavily on literal interpretations of language. This challenge can be addressed by mapping such expressions to their intended meanings using advanced machine-learning techniques.
Handling Language Nuances and Cultural References
Culture and context can greatly affect the meaning of words and phrases.
For instance, using the word “pants” in the UK refers to underwear, while in the US, it refers to trousers.
Similarly, cultural references like idioms or common expressions can be challenging for an NLU system to comprehend if they are unfamiliar with the culture. This challenge can be tackled by building NLU systems that can identify the user's cultural background and adapt accordingly.
Dealing with Multiple Possible Interpretations
Another significant challenge of NLU is handling ambiguous language, which can lead to multiple possible interpretations.
For instance, the sentence, “I saw her duck” can be interpreted in two ways: “I observed her ducking” or “I observed a duck that belonged to her”. Resolving such ambiguities requires understanding contextual clues, sentence structure, and other cues within the text.
Understanding Complex Sentence Formations
Natural language is often complex, with lengthy and intricate sentence structures that can be a challenge for NLU systems.
For example, the sentence, “Although she sang well, she didn’t get a call back” is a complex sentence structure with multiple clauses. NLU systems must be capable of breaking down such sentences into smaller components to understand the intended meaning.
Extracting Implicit Information and Context
NLU systems also need to extract implicit information and context as they are often ambiguous or unclear in the text.
For example, an NLU system needs to understand the context of the sentence, “I need to book a flight” to determine the destination and date of the flight. An advanced NLU system can put together all the implicit information to fully understand the user’s intent.
Conclusion
The journey to true language comprehension remains ongoing for AI. Yet innovations in deep learning, vast datasets, and computing power have enabled astounding advancements.
According to Microsoft, its advanced NLU model matches or exceeds human performance on the SuperGLUE language benchmark.
While nuanced language mastery still exceeds current NLP capabilities, platforms like BotPenguin, a chatbot platform that uses NLP enable businesses to automate their customer support and improve customer satisfaction. BotPenguin uses NLP to power its chatbots, making them more efficient and effective at handling customer queries.
But technology alone cannot replicate human language abilities. Progress relies on ongoing research and testing by dedicated scientists across industry and academia. To them the linguistic puzzles we solve effortlessly still present the ultimate challenge.
And for the chance to build technology that truly understands us? Many would say - that's a goal worth pursuing relentlessly.
Frequently Asked Questions (FAQs)
What is the role of machine learning in Natural Language Understanding?
Machine learning plays a critical role in NLU. It allows the system to learn patterns and relationships from large amounts of language data, enabling it to make predictions and improve its understanding over time.
Supervised and unsupervised learning algorithms are commonly used in NLU to train models on labeled or unlabeled data.
How does Natural Language Understanding handle ambiguity in language?
NLU addresses language ambiguity by considering contextual information. It takes into account the surrounding words, sentence structure, and the broader context.
This contextual understanding helps machines make more accurate interpretations of language.
How does Natural Language Understanding process multiple languages?
NLU supports multiple languages by utilizing language-specific linguistic rules, resources, and models. It can apply different techniques for tokenization, parsing, and semantic analysis based on the language being processed.
Multilingual NLU systems can understand and process text or speech in multiple languages simultaneously.
Can Natural Language Understanding be used in real-time applications?
Yes, NLU can be used in real-time applications like chatbots or voice assistants.