
Introduction
Ever wondered how chatbots seem so smart these days? The secret lies in large language models - AI systems trained on massive amounts of text data to understand natural language.
In this post, we'll uncover everything you need to know about building these intelligent models.
From choosing the right architecture to fine-tuning techniques, we'll guide you through the key steps for training performant models.
With practical tips on data preparation, optimization, and more, you'll learn the nuts and bolts of language model training.
Whether you're an AI newbie or seasoned expert, you'll find valuable insights here. So read on to master the mechanics of training remarkable language models that impress!
Understanding Language Models
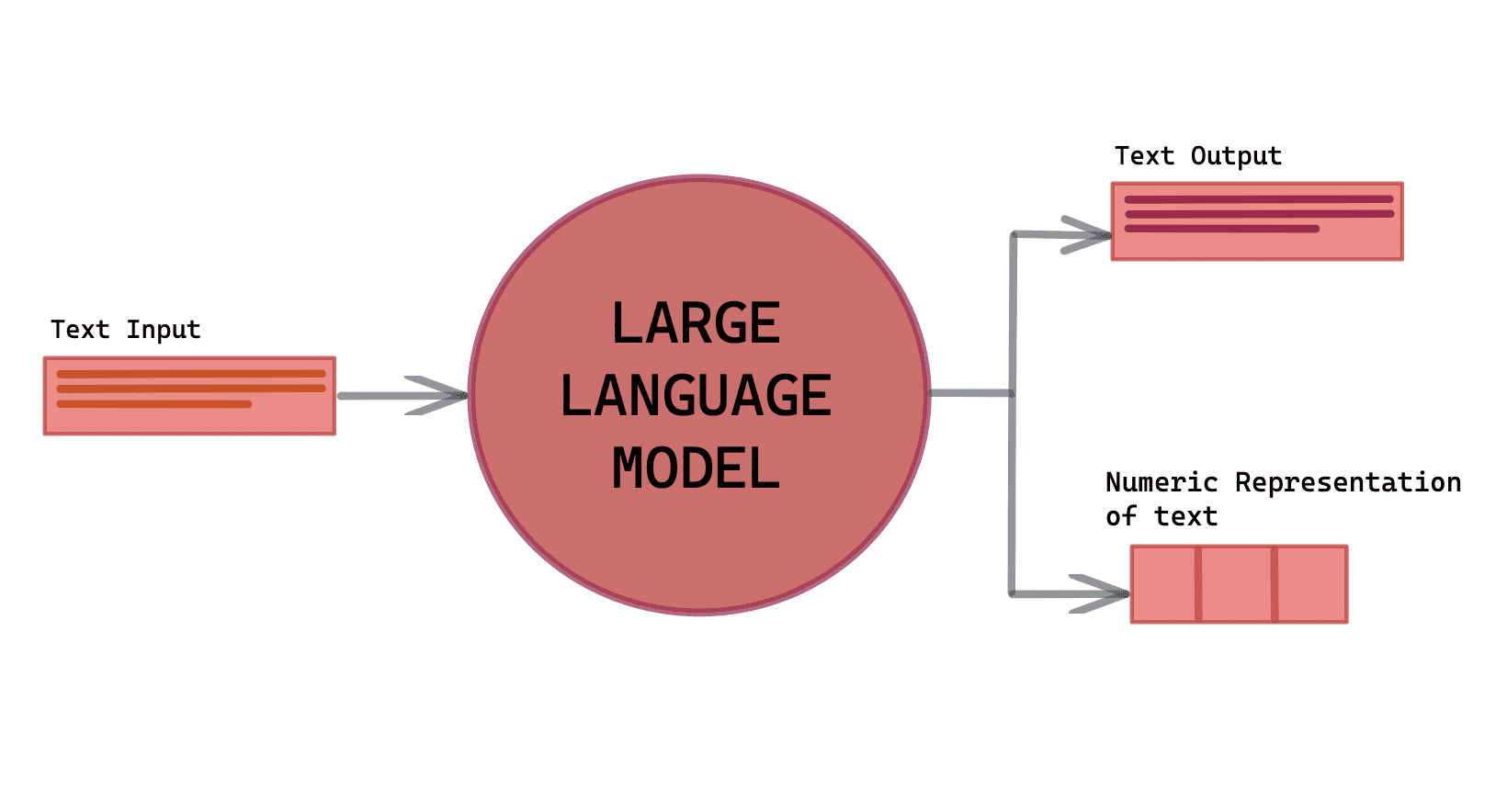
Language models are the heart of NLP and are designed to understand, generate, and translate human language.
They can process sequences of words and predict the likelihood of the next word in a given context.
Language models play a vital role in several NLP applications, including speech recognition, text generation, and machine translation.
Types of Language Models
There are two main types of language models: n-gram and neural.
N-gram models use a simple probability-based approach that utilizes the frequency of words or phrases in a text corpus.
Neural language models, on the other hand, use deep learning techniques to model the probabilities of words based on their context.
Next, we will see how to choose the right architecture for LLM model training.
Understanding the Architectural Landscape of Large Language Models (LLMs)
When it comes to training a high-level language model, selecting the perfect architecture is crucial because it lays the groundwork for efficient operations and expected outcomes. Over the years, various architectures have emerged, each with its strengths and weaknesses.
An Overview of Popular Architectures
There are several notable architectures that have garnered attention for their effectiveness in training LLMs:
- Transformer model: This architecture forms the basis of multiple LLMs with its articulate network of stacked attention layers.
- GPT series: This includes models like GPT-2 or GPT-3, which are known for their generative quality.
- BERT (Bidirectional Encoder Representations from Transformers): As the name suggests, BERT is unique for its bidirectional understanding of language.
- T5 (Text-to-Text Transfer Transformer): T5 has taken the world of LLMs by bringing customization and versatility to the forefront.
Pros and Cons of Different Architectures
Each of these architectures touts unique strengths and limitations. It's essential to match these features with the expectations and requirements of a project to make a suitable choice.
Transformer Model
Pros:
- Highlights: Successful in capturing long-term dependencies in languages, superior performance in NLP tasks.
- Extensive Usage: Used in machine translation, text generation, and language understanding.
- Efficient Processing: The attention mechanism paves the way for parallelization, increasing computational efficiency.
Cons:
- Constraints: Demand a high level of computation and memory resources, limiting their use on constrained devices.
- Time-Consuming: The training of larger transformer models tends to take longer, especially with an extensive dataset.
GPT (Generative Pretrained Transformer) Series
Pros:
- Robust Performance: GPT models excel in a range of natural language understanding (NLU) tasks.
- Text Generation Ability: Generate coherent and contextually accurate text, apt for applications like auto-complete suggestions, customer service chatbots, and content generation.
- Versatility: They can be fine-tuned to handle specific tasks via transfer learning.
Cons:
- Content Generation Limitations: Tend to fall short in generating diverse or novel content, may occasionally produce repetitive or senseless content.
- Not Always Best: May not always be the most efficient at capturing syntax and semantic information compared to alternatives.
BERT (Bidirectional Encoder Representations from Transformers)
Pros:
- Revolutionary Models: Considered a game-changer in NLP tasks with state-of-the-art performance across benchmarks.
- Deep Understanding: Outstanding understanding of sentence-level and context-dependent semantics, capturing bidirectional relationships with words.
- Customization: Can be fine-tuned for specific downstream tasks, manifesting improved performance.
Cons:
- High Resource Demand: They demand a high level of computational resources for training and inference.
- Size Matters: BERT's large size makes it unsuitable for deployment on devices with limited computational capabilities.
T5 (Text-to-Text Transfer Transformer)
Pros:
- Text-to-Text Approach: Demonstrates the concept of "text-to-text" transfer learning, representing multiple NLP tasks as text-generation problems.
- High Performance: Achieves impressive results across diverse NLP tasks, from answering questions and summarizing to translation.
- Unified Architecture: A single architecture manages both training and deployment, providing a streamlined solution.
Cons:
- Resource-Heavy: The training process with large datasets can be resource-intensive and time-consuming.
- Deployment Challenges: Size-related issues can arise while deploying T5 models in resource-constrained scenarios.
Considerations for Selecting the Architecture Based on Specific Use Cases
When selecting an architecture for a language model, it is important to consider the specific use case and requirements.
Different architectures have their strengths and weaknesses that may make them more suitable for certain applications.
Use Case Specificity
It is essential to understand the requirements and objectives of the use case.
Consider whether the task primarily involves text generation, understanding, translation, summarization, sentiment analysis, or any other objective.
Each architecture may excel in different areas, so aligning the model's capabilities with the use case is crucial.
Performance Benchmarks
Reviewing performance benchmarks and research papers can provide insights into the effectiveness of an architecture for specific tasks.
It is beneficial to compare the model's performance on relevant benchmarks or datasets to evaluate its suitability.
Resources and Deployment Constraints
Consider the available computational resources and deployment constraints. Some architectures, like transformer models, are resource-intensive and require significant processing power and memory. If the application will be deployed on devices with limited resources, the architecture's size and efficiency should be considered.
Training Data Availability
Evaluate the availability and size of training data. Some architectures may require large amounts of pretraining data, while others can be fine-tuned with smaller datasets.
If limited training data is available, architectures that offer transfer learning or pretraining on large corpora may be advantageous.
Interpretability and Explainability
Consider the need for interpretability and explainability in the model's predictions.
Certain architectures, like transformer models, have multiple attention layers that can provide insights into the model's decision-making process.
On the other hand, models like GPT may produce outputs that are difficult to interpret due to their generative nature.
Time and Efficiency
Assess the time and efficiency requirements of the application.
Some architectures, such as BERT, can be slow to train and evaluate due to their large size and computational complexity.
Architectures that offer faster training or inference times may be preferred if time is a critical factor.
Considering these considerations can help in selecting an architecture that aligns with the specific requirements and constraints of the use case, leading to more effective and efficient language models.
Next, we will see how to partner and fine-tune large language models.
Pretraining and Fine-tuning in Large Language Models
Pretraining and fine-tuning are essential steps in training LLM models.
- Pretraining: Large language models are trained on a large text dataset to learn language patterns and relationships.
- Fine-tuning: The pre-trained model is further trained on a smaller labeled dataset specific to the task, adapting it for accurate predictions.
- Transfer learning: Pretraining and fine-tuning together enable the pre-trained model to be applied to various tasks, saving time and resources.
Next, we will cover how to prepare data for training LLM models.
Data Preparation for Training Large Language Models
Preparing the data is a crucial step in training large language models. The training data's quality, size, and diversity heavily influence the model's accuracy.
- Data Collection: Gather a diverse and representative dataset for training
- Text Cleaning and Preprocessing: Remove noise and normalize text
- Corpus Creation: Combine cleaned text data to represent the target domain
- Training Data Size and Sampling: Select the optimal size using sampling techniques
- Data Tokenization: Split data into meaningful units
- Data Formatting: Format tokenized data for training
- Dataset Split: Divide the dataset into training, validation, and test sets
- Data Augmentation (optional): Add synthetic data to enhance diversity
- Quality Control: Analyze the data for inconsistencies, errors, or biases
- Iterative Refinement: Continuously refine data preparation as the training progresses.
Next, we will see how to optimize techniques for training the LLM model.
Optimization Techniques for Training Large Language Models
Optimizing the training process can significantly improve the performance of large language models and speed up the training process.
- Learning Rate: The learning rate controls the step size during optimization and plays a crucial role in determining the final model's convergence speed and quality. Setting an appropriate learning rate is essential for efficient training.
- Batch Size: The batch size determines the number of training examples processed in each iteration. It affects both the memory requirements and the computational efficiency of training. Choosing an optimal batch size is important for balancing speed and resource constraints.
- Gradient Clipping: Gradient values can sometimes explode during training, leading to unstable optimization. Gradient clipping limits the gradient values to a specified threshold, ensuring stable optimization and preventing numerical instability.
- Regularization: Regularization techniques like dropout or weight decay help prevent overfitting, which occurs when the model memorizes the training data instead of generalizing well on unseen data. These techniques add penalties to the loss function, encouraging the model to learn simpler and more robust representations.
- Early Stopping: Monitoring the validation loss during training and stopping early when there is no improvement helps prevent overfitting and selects the best-performing model. This technique saves computational resources and avoids training for unnecessary iterations.
Conclusion
Training effective large language models requires careful planning.
Choose an optimal model architecture based on your use case and resources. Invest time in curating diverse, high-quality training data.
Optimize training by tuning hyperparameters like batch size and learning rate.
Use techniques like pretraining, transfer learning and regularization to improve model performance.
Monitor validation metrics to prevent overfitting. With robust data, computational power and sound training practices, you can develop advanced language models for conversational AI and other NLP applications.
The work is complex but rewarding if approached systematically.
Frequently Asked Questions (FAQs)
What are large language models?
Large language models are advanced AI systems trained on massive amounts of text data to understand and generate human-like text. They have a wide range of applications in natural language processing tasks.
How are large language models trained?
Training large language models involves feeding them vast amounts of text data, such as books, articles, and websites. They use powerful deep learning algorithms to learn patterns, grammar, and context to generate coherent and contextually relevant text.
What challenges are faced when training large language models?
Training large language models can be computationally intensive and time-consuming. It requires substantial computational resources, specialized hardware (such as GPUs), and effective optimization techniques to handle the massive data and model parameters involved in the training process.
What are the benefits of using large language models?
Large language models have the potential to significantly advance natural language processing tasks such as machine translation, text summarization, sentiment analysis, and chatbots. Their ability to generate human-like text can enhance applications across various domains.
Are there any ethical considerations with large language models?
Yes, developing and deploying large language models raise important ethical considerations. They can unintentionally amplify biased or harmful content from the training data. Ensuring fairness, transparency, and ethical use of these models is critical to mitigate potential biases and risks.


