
Introduction
So, what exactly are LLMs? Well, imagine a language model on steroids – an intellectual powerhouse capable of comprehending and generating human-like text on a mind-boggling scale. We're talking about models like GPT-3, GPT-4, and others that have taken the AI landscape by storm.
LLMs have extensive textual training datasets. Common Crawl, The Pile, MassiveText, Wikipedia, and GitHub are a few examples of textual datasets that are often used. The datasets have a maximum word count of 10 trillion.
Ready to explore the wide-ranging applications of LLMs? We'll discuss how they transform natural language processing, chatbots, virtual assistants, content creation, and text summarization. From healthcare to customer service, LLMs are making their presence felt in various fields.
Throughout this blog, we'll provide practical insights on leveraging LLMs effectively. We'll share tips for training and integrating these models into your existing systems, along with best practices for evaluation and selection.
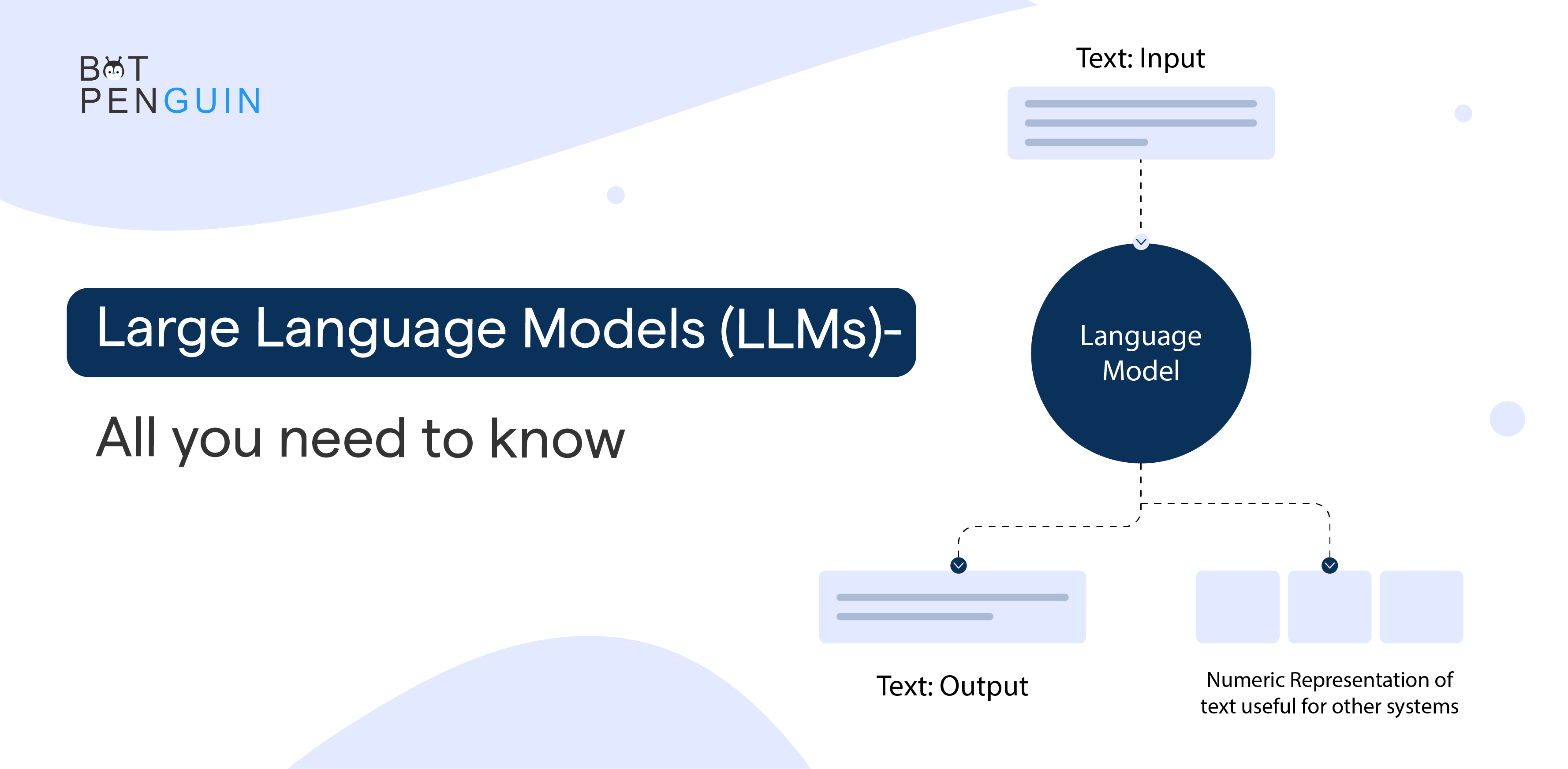
What are Large Language Models (LLMs)?
Let's start by defining what LLMs are all about. Large Language Models are highly sophisticated artificial intelligence models with an extraordinary ability to comprehend and generate human-like text. These language virtuosos take traditional language models to a new level, allowing machines to understand and respond to us naturally and coherently.
How do LLMs Differ from Traditional Language Models?
What sets LLMs apart from their predecessors? Traditional language models typically relied on statistical methods and limited contextual understanding. On the other hand, LLMs leverage state-of-the-art deep learning techniques and vast amounts of training data to achieve a remarkable level of language comprehension. They have a deeper understanding of context, nuances, and even subtleties, enabling more accurate and contextually appropriate responses.
Examples of Popular LLMs
The LLM landscape boasts some impressive models that have garnered significant attention. One notable example is GPT-3 (Generative Pre-trained Transformer 3), developed by OpenAI. GPT-3 took the world by storm with its ability to generate coherent and contextually appropriate responses. It showcased the power and potential of LLMs in various applications. Other models, such as GPT-4, are on the horizon, promising even more advanced language capabilities.
Why are Large Language Models Important?
LLMs have emerged as a crucial breakthrough in natural language processing. They have the uncanny ability to accurately comprehend human language, enabling them to understand our queries, requests, and commands more effectively. Moreover, LLMs excel at generating human-like text, making interactions with machines feel more natural and engaging.
LLMs offer several advantages over traditional language models. Their vast size and training on massive datasets give them a broader knowledge base, allowing them to provide more comprehensive and accurate responses.
LLMs also excel at context understanding, enabling them to generate responses tailored to the specific context and user intent. With LLMs, the gap between human and machine-generated text is rapidly shrinking.
The impact of LLMs stretches across numerous industries and fields. LLMs aid in medical research, diagnosis, and even patient care in healthcare. Customer service experiences are being transformed with the help of LLM-powered chatbots and virtual assistants.
Content generation, including automated article writing and social media posts, is becoming more efficient and effective. LLMs are paving the way for exciting advancements and innovations in various domains.
How Do Large Language Models Work?
Wondering how LLMs work? Let's delve into the inner workings of these powerful models to unravel their fascinating capabilities.
Pre-training and Fine-tuning
LLMs undergo a two-step process: pre-training and fine-tuning. In pre-training, the models are exposed to vast amounts of text data from the internet, learning to expect the next word in a sentence. This process helps LLMs acquire a general understanding of language and its patterns. On the other hand, fine-tuning involves training the models on specific tasks or domains to make them more specialized and accurate in their responses.
Understanding Transformer Architecture in LLMs
The Transformer architecture forms the backbone of LLMs. It enables efficient processing of long-range dependencies, allowing the models to capture contextual information effectively. Transformers consist of self-attention mechanisms that help the models focus on relevant input parts and generate coherent and contextually appropriate outputs. This architecture has proven highly effective in achieving state-of-the-art language generation and understanding.
Data Sources and Training Methodologies for LLMs
LLMs rely on vast and diverse datasets for their training. These datasets comprise texts from books, articles, websites, and various other sources available on the internet. The training process involves optimizing model parameters using powerful GPUs and extensive computational resources.
Who Develops Large Language Models?
Various companies and organizations have been crucial when developing Large Language Models.
Companies and Organizations
Several entities are actively involved in LLM development, from tech giants to cutting-edge research institutions. Companies like OpenAI, Google, Microsoft, Facebook, and Amazon have dedicated significant resources and expertise to push the boundaries of language models.
OpenAI's Contributions to LLM Advancements
OpenAI, a prominent organization in the artificial intelligence domain, has been at the forefront of LLM advancements. They have developed groundbreaking models like GPT-3 (Generative Pre-trained Transformer 3) that have garnered immense attention and acclaim for their impressive language generation capabilities.
Collaborations and Partnerships
Collaborations and partnerships have been instrumental in driving LLM research and development. Companies and research institutions often join forces to leverage their collective knowledge and resources. OpenAI, for instance, has collaborated with academic institutions and industry partners to accelerate progress and foster innovation.
Where are Large Language Models Used?
The applications of Large Language Models are vast and ever-expanding. Let's explore some key domains where LLMs are making a significant impact.
Natural Language Processing (NLP)
LLMs have revolutionized Natural Language Processing. They excel at sentiment analysis, language translation, text classification, and information retrieval tasks. With their ability to comprehend and generate human-like text, LLMs have enhanced the accuracy and efficiency of NLP algorithms.
Chatbots and Virtual Assistants
LLMs have become the backbone of intelligent chatbots and virtual assistants. By leveraging the power of language models, chatbots can engage in dynamic and contextually relevant conversations with users. LLMs enable chatbots to understand user queries and provide accurate and helpful responses, greatly enhancing the user experience.
Content Creation and Text Summarization
LLMs have become invaluable tools for content creation and text summarization. They can generate coherent and contextually appropriate text, aiding in content generation for articles, social media posts, and even creative writing. LLMs can also condense lengthy documents into concise and informative summaries, saving time and effort.
When were Large Language Models Introduced?
The development of Large Language Models can be traced back to the early days of language modeling research. Over time, advancements in deep learning and the availability of vast training data paved the way for the emergence of LLMs as we know them today.
Milestones in LLM Development
The field of LLMs has witnessed significant milestones. Each milestone has pushed the boundaries of language understanding and generation from early language models like Elman Networks and Hidden Markov Models to more recent breakthroughs like GPT-3 and GPT-4.
Current State and Future Prospects
LLMs have reached unprecedented levels of sophistication and performance, but the journey is far from over. Ongoing research addresses limitations, such as biases and ethical concerns, while exploring avenues for further improvement. The future holds immense potential for LLMs to transform how we communicate and interact with technology.
Potential Benefits and Concerns with Large Language Models
As we embark on this LLM adventure, let's first explore the potential benefits and concerns that come with these language wizards.
Advantages of LLMs in Improving Efficiency and Productivity
LLMs bring many advantages, making them invaluable tools for boosting efficiency and productivity. These models can swiftly generate coherent text, saving time and effort in content creation. Need a product description? A blog post? LLMs have got your back! They can even assist in customer service interactions, providing quick and accurate responses.
Ethical Considerations and Potential Biases in LLMs
But with great power comes great responsibility. LLMs aren't immune to ethical considerations and potential biases. They learn from vast amounts of data; if that data contains preferences, the models might inadvertently perpetuate them. As responsible users, we must be conscious of these prejudices and take action to lessen them.
Risks Associated with LLMs and Responsible Use
Mitigating associated risks is crucial to ensure the responsible use of LLMs. Transparency and accountability are key. Researchers and developers are working on techniques to reduce biases and make LLM decision-making more understandable. Additionally, establishing clear guidelines and ethical frameworks can help navigate potential pitfalls.
Limitations and Challenges of Large Language Models
As we marvel at the capabilities of LLMs, it's essential to recognize their limitations and the challenges they present.
Computational Requirements and Resource Constraints
LLMs, being powerhouses of language, have substantial computational requirements. Training and running these models can be resource-intensive, requiring specialized hardware and infrastructure. Cost and scalability can become hurdles that must be addressed for widespread adoption.
Dataset Biases and Limitations in Training Data
LLMs learn from the data they're trained on, and if the data is biased or limited, it can affect the output. Biases present in training data can inadvertently be reflected in the generated text. Ensuring diverse and representative training datasets becomes crucial to mitigate biases and improve fairness.
Ethical Concerns Surrounding LLM Deployment and Societal Impact
The deployment of LLMs raises ethical concerns. From deep fakes and misinformation to potential job displacement, the societal impact of LLMs needs careful consideration. It's essential to foster discussions and establish guidelines to navigate these ethical challenges responsibly.
Conclusion
We explored their potential benefits, ethical considerations, and tips for effective utilization. We also delved into the limitations and challenges that come with these linguistic marvels.
As we conclude, let's recap the key takeaways: LLMs can supercharge efficiency and productivity, but we must navigate ethical considerations and biases. By following best practices and responsible use, we can unlock the full potential of LLMs. Let's embrace the future possibilities and continue exploring and experimenting with these incredible language models.
Remember, the world of LLMs is constantly evolving for the latest developments and advancements. Now, go forth and embark on your linguistic adventures with LLMs. Happy exploring!
BotPenguin is a chatbot platform that leverages natural language processing (NLP) techniques to provide human-like conversations to users. It uses pre-built models and customizable conversational flows to respond to user queries and provide relevant information. So if you want the best customer service, connect with us today.
Frequently Asked Questions
What are Large Language Models (LLMs)?
Large Language Models (LLMs) are advanced AI models that use deep learning techniques to understand and generate human-like text. They are trained on massive amounts of data and can comprehend and generate language with impressive accuracy and fluency.
How do Large Language Models work?
Large Language Models work by utilizing deep learning algorithms and sophisticated neural networks. They learn patterns, context, and linguistic nuances from extensive training data to generate coherent and contextually relevant responses.
What are the applications of Large Language Models?
Large Language Models have a wide range of applications, including natural language understanding, machine translation, chatbots, content generation, virtual assistants, and more. They are being used across various industries to automate tasks and enhance human-computer interactions.
How are Large Language Models trained?
Large Language Models are trained on massive datasets that contain a vast amount of text from various sources. They undergo pre-training and fine-tuning processes, where they learn to predict the next word in a sentence based on the context provided by the training data.
What are some well-known Large Language Models?
Some well-known Large Language Models include OpenAI's GPT-3 (Generative Pre-trained Transformer 3), Google's BERT (Bidirectional Encoder Representations from Transformers), and Facebook's RoBERTa (Robustly Optimized BERT).
What are the limitations of Large Language Models?
Large Language Models may sometimes generate incorrect or biased responses due to the biases present in the training data. They also require significant computational resources and energy consumption, making them inaccessible to smaller organizations.
How can Large Language Models benefit businesses?
Large Language Models can benefit businesses by automating customer support with chatbots, generating the content, improving language translation, personalizing recommendations, and enhancing overall productivity through natural language processing capabilities.
Are Large Language Models Capable of understanding context?
Yes, Large Language Models have the ability to understand the context. They learn from vast amounts of training data, allowing them to capture and analyze the contextual information present in the input text to generate meaningful and relevant responses.
Can Large Language Models be fine-tuned for specific tasks?
Yes, Large Language Models can be fine-tuned for specific tasks by providing them with task-specific training data. Fine-tuning helps them adapt to a particular domain or application, improving their performance and accuracy in that specific task.
Are there any ethical concerns associated with Large Language Models?
Yes, there are ethical concerns surrounding Large Language Models. These include the potential for generating misleading or harmful content, amplifying biases present in the training data, and the implications of AI-generated text on misinformation and fake news. It is important to address these concerns and ensure responsible use of such models.


