
Discovering the Capabilities of spaCy: Empowering NLP
Updated at May 28, 2026
5 min to read

Natural language processing enables extracting insights from unstructured text data across documents, emails, chats, etc.
As NLP adoption grows globally, industrial-strength libraries like spaCy have emerged as leading platforms for production text analysis.
According to Reports and Data, the NLP market size is projected to reach $80.68 billion by 2030, driven by rising demand to process high language data volumes as information generation explodes. spaCy has been proven to handle massive text analyses using advanced deep learning models without losing accuracy.
With versatile capabilities like named entity recognition, intent classification, key phrase extraction, and sentiment analysis, spaCy empowers deriving intelligence from text at scale.
It offers pre-trained statistical models out of the box so developers can avoid time-consuming model building from scratch. Integrations with data science stacks like NumPy, Pandas, and sci-kit-learn also ease pipeline creation for real-world NLP applications.
As businesses aim to quantify unstructured data for enhanced decision-making, leveraging robust libraries like spaCy is key.
Its balance of usability, customization, and performance makes spaCy the go-to choice to extract signals from text noise across diverse use cases, from chat analysis to document comprehension.
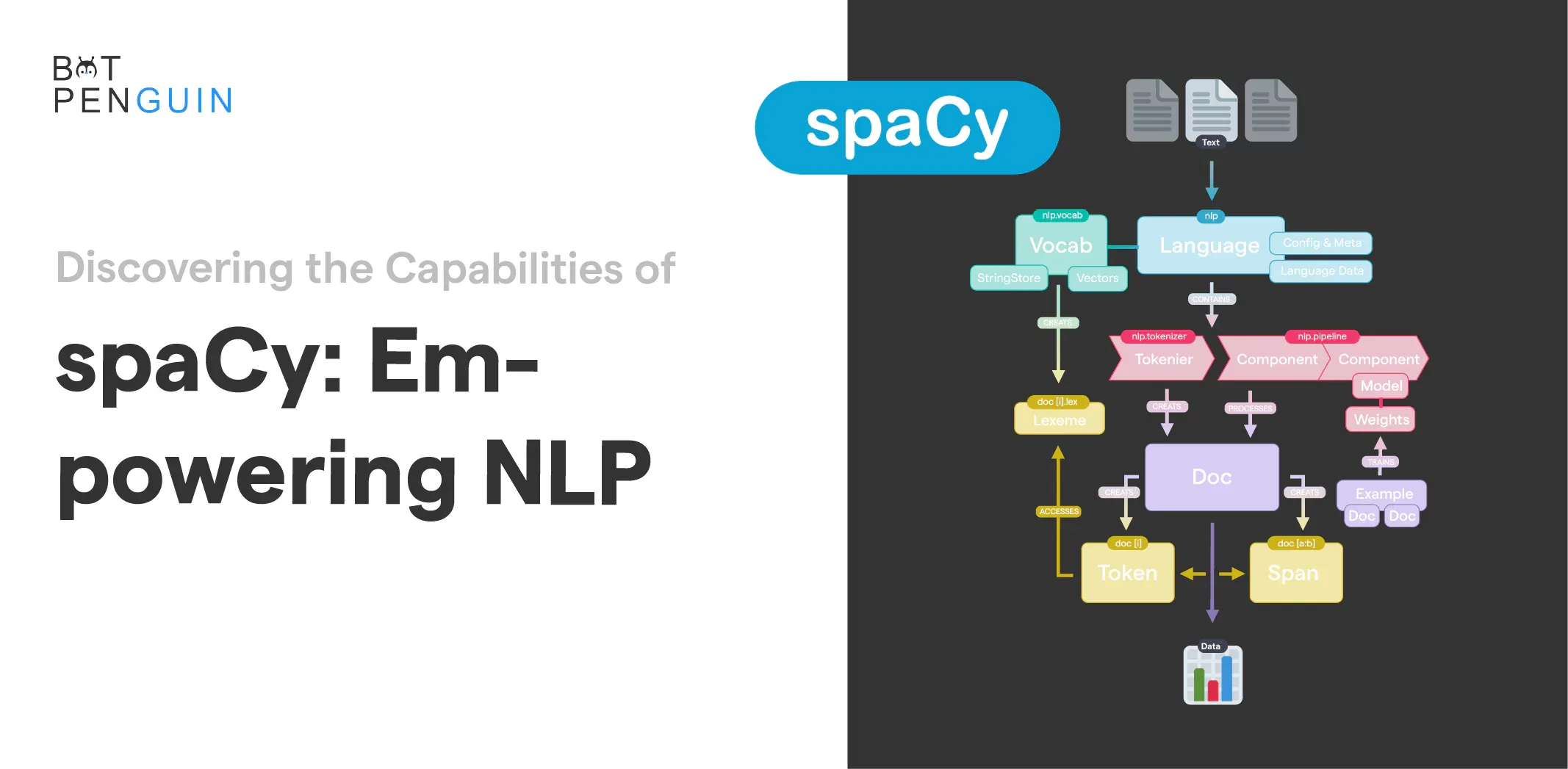
Spacy is a Python library that provides a simple and efficient way to process and analyze large volumes of text data.
It is built on the concept of pipelines, which allows easy integration and application of different NLP tasks.
By using Spacy, you can perform a wide range of text analysis tasks, such as tokenization, lemmatization, part-of-speech tagging, entity recognition, and dependency parsing.
Spacy offers several key features that make it a popular choice for text analysis tasks. Here are some of its notable features:
Advanced Tokenization: Spacy provides robust tokenization capabilities, allowing you to break down text into meaningful units called tokens.
These tokens could be individual words, punctuation marks, or even complete phrases.
Lemmatization and Part-of-Speech Tagging: Spacy enables lemmatization, which reduces words to their base or root form, and part-of-speech (POS) tagging, which assigns grammatical labels to words.
These features are crucial for understanding the context and meaning of words in text.
Entity Recognition: Spacy offers built-in support for named entity recognition (NER), the task of identifying and classifying named entities, such as persons, organizations, locations, and more. It helps in extracting important information from text.
Dependency Parsing: Spacy's dependency parsing allows you to analyze the syntactic structure of sentences by identifying the relationships between words.
This feature is particularly useful for understanding how words are related to each other in a sentence.
Customization and Training: Spacy allows you to train and customize its existing models to suit your specific needs.
You can train your models using labeled data to improve their performance on domain-specific tasks.
Before diving into the exciting world of Spacy, let's go through the installation process and ensure compatibility with your system.
To install Spacy, you can use pip, the Python package installer. Open your command prompt or terminal and run the following command:
pip install spacy
Once the installation is complete, you can verify it by importing the library into your Python environment. Open a Python terminal or a Python file, and run the following code:
import spacy
If no errors occur, congratulations! You have successfully installed Spacy.
Suggested Reading:
Spacy supports various versions of Python, including Python 2.7 and Python 3. x. However, it is recommended to use Python 3. x as Python 2.7 has reached its end of life.
Make sure you have a compatible version of Python installed on your system to work smoothly with Spacy.
Spacy provides pre-trained linguistic models for various languages, allowing you to process text in different languages with ease.
These models are trained on large datasets and generalize well for a wide range of NLP tasks. Some of the popular pre-trained models available in Spacy are:
en_core_web_sm: A small English model that includes tokenization, POS tagging, NER, and dependency parsing.
en_core_web_md: A medium-sized English model that also includes word vectors, which capture the meaning and similarity between words.
en_core_web_lg: A large English model with expanded vocabulary and more accurate word vectors.
Apart from English, Spacy also supports several other languages, such as French, German, Spanish, Portuguese, and more.
Each supported language has its own set of pre-trained models, making it easier to perform text analysis in multilingual scenarios.
In the next section, we will dive into the important step of preprocessing text using Spacy, which lays the foundation for various text analysis tasks.
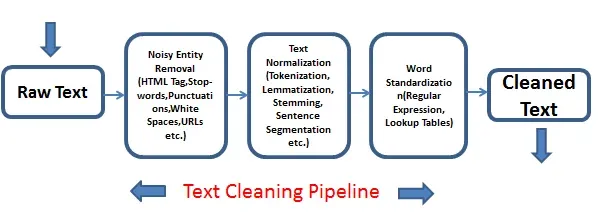
Preprocessing is a crucial step in text analysis as it involves transforming raw text data into a format that can be easily understood and processed by machine learning algorithms.
In this section, we will explore the necessary preprocessing steps using Spacy.
Text preprocessing typically involves several steps, each serving a specific purpose. Here are the essential preprocessing steps:
Tokenization: Tokenization refers to the process of splitting text into individual units called tokens. Tokens usually represent words, but they can also include punctuation marks or other meaningful entities.
Tokenization helps in breaking down text into manageable chunks for further analysis.
Lemmatization: Lemmatization involves reducing words to their base or root form. For example, lemmatizing the words "running," "runs," and "ran" would result in the base form "run." This process helps in normalization and reduces the dimensionality of the data.
Stop Word Removal: Stop words are commonly occurring words that do not carry significant meaning or contribute much to the overall understanding of the text.
Examples of stop words include "the," "and," "is," etc. Removing stop words helps in reducing noise and improving analysis accuracy.
Handling Special Characters and Numerical Data: Text data often contains special characters, symbols, or numerical data that may need special handling.
It could involve removing special characters, replacing them with appropriate values, or converting numerical data to a standardized format.

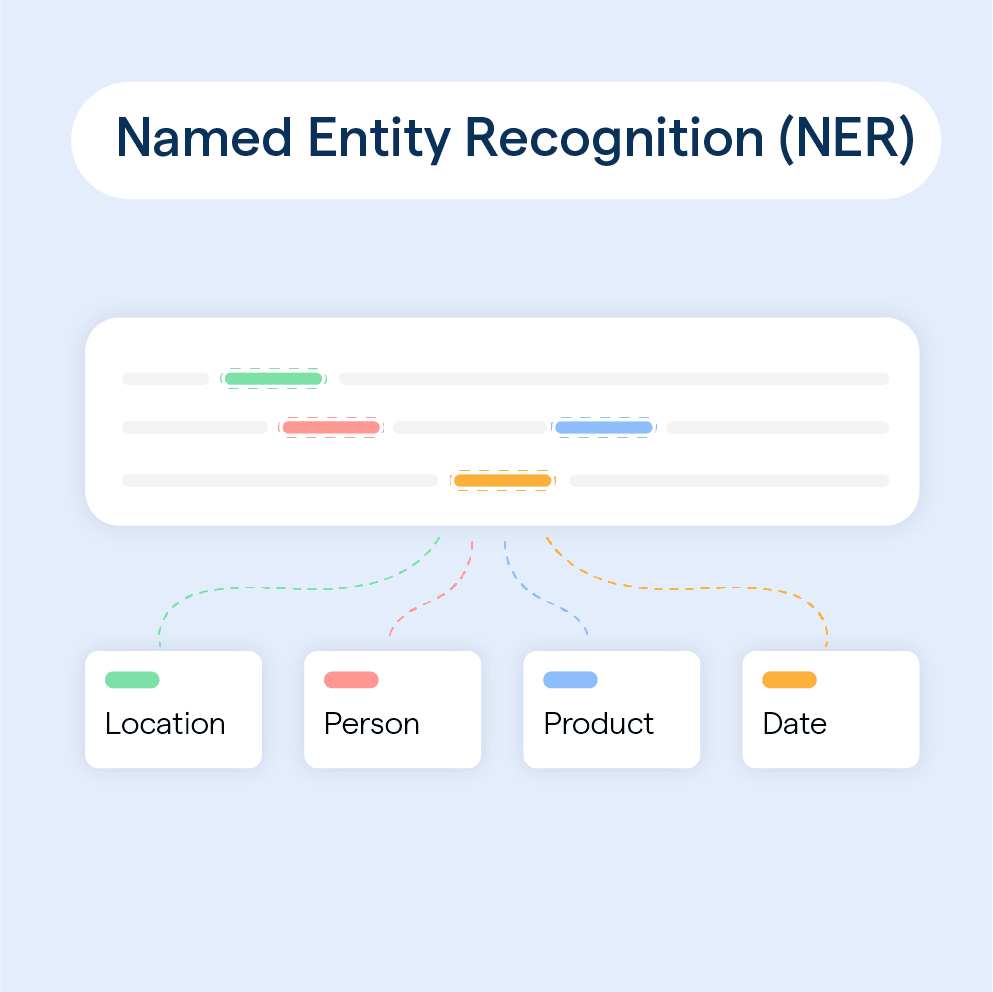
Named Entity Recognition (NER) is a Natural Language Processing (NLP) technique that involves the identification of entities like names, locations, organizations, and time expressions in text data.
NER has a wide range of applications, including chatbots, search engines, and sentiment analysis.
Spacy is one of the most popular open-source libraries that offer advanced features for NLP and text analysis.
With its in-built NER support, Spacy allows the efficient extraction of named entities from text.
The library can recognize and classify standard entities, such as persons, organizations, locations, date/time expressions, and product names with high accuracy.
Spacy's NER model uses machine learning algorithms, which have been trained on millions of texts to improve its accuracy.
To extract named entities from a given text using Spacy, you must first load the appropriate Spacy model and tokenize the input text. Here's how you can achieve this:
import spacy
# Load the Spacy small model
nlp = spacy.load("en_core_web_sm")
# Tokenize the input text
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
Once you have tokenized the input text, you can extract the named entities and their respective labels using the ents attribute of the Doc object.
# Extract named entities from the input text
for ent in doc.ents:
print(ent.text, ent.label_)
The above code will output the following named entities and their respective labels:
Apple ORG
U.K. GPE
$1 billion MONEY
The Spacy model has correctly identified "Apple" as an organization, "U.K." as a geopolitical entity, and "$1 billion" as a monetary value. This demonstrates the impressive capabilities of Spacy's NER model.
Part-of-speech (POS) tagging is another important technique in NLP that involves the identification of the grammatical category of each word in a sentence.
POS tagging typically involves labeling words as nouns, verbs, adjectives, adverbs, and other classes. POS tagging helps understand the context and meaning of a sentence.
Spacy provides advanced support for POS tagging and dependency parsing.
Dependency parsing involves the identification of the grammatical relationships between words in a sentence.
Spacy's efficient pipeline architecture allows you to perform POS tagging, dependency parsing, and other related tasks simultaneously.
import spacy
# Load the Spacy small model
nlp = spacy.load("en_core_web_sm")
# Tokenize the input text
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
# Perform POS tagging and dependency parsing
for token in doc:
print(token.text, token.pos_, token.dep_, token.head.text)
The above code will output the following POS tags, dependency relations, and their respective heads:
Apple PROPN nsubj looking
is AUX aux looking
looking VERB ROOT looking
at ADP prep looking
buying VERB pcomp at
U.K. PROPN compound startup
startup NOUN dobj buying
for ADP prep buying
$ NUM quantmod billion
1 NUM compound billion
billion NUM pobj for
As you can see, Spacy has correctly identified the POS tags, dependency relations, and their respective heads for each word in the input text.
Suggested Reading:
spaCy vs TensorFlow: Selecting the Ideal NLP Framework
Spacy also offers several advanced techniques for analyzing relationships between words.
For instance, you can use named entity recognition and coreference resolution to identify references to entities that have previously been mentioned in a text.
Additionally, you can use Spacy's entity linking feature to associate named entities with external knowledge bases, such as Wikipedia.
When working with natural language processing (NLP), text classification is a fundamental task that involves categorizing text into different predefined classes or categories.
It has several applications, such as sentiment analysis, spam detection, and topic classification. Spacy, a popular Python library for NLP, provides powerful features for text classification.
Text classification is the process of assigning pre-defined labels or categories to text documents based on their content.
For example, movie reviews can be classified as positive or negative sentiments. It involves training a model on a labeled dataset and then using that model to predict the class of new, unseen text.
Text classification can be approached using various algorithms, including machine learning and deep learning techniques.
Spacy simplifies training a text classifier by providing an easy-to-use interface. Here are the steps to train a text classifier with Spacy:
Gather and Prepare Labeled Data: Collect a dataset containing samples of text and their corresponding labels or categories.
Preprocess the data by cleaning, tokenizing, and normalizing the text.
Load Spacy and Initialize the Text Classification Pipeline: Import the necessary libraries and load the Spacy model.
Initialize a blank text classification pipeline using the spacy.pipeline function.
Adding Text Classification Labels: Add the classification labels to the text classification pipeline using the pipe.add_label method.
For example, if you have two classes, "positive" and "negative," use pipe.add_label("positive") and pipe.add_label("negative").
Training the Text Classifier: Split your dataset into training and evaluation sets. Train the text classifier using the pipe.train method, providing the training data and the number of training iterations.
Evaluating the Performance of the Text Classifier: After training, evaluate the performance of the text classifier on the evaluation dataset.
The evaluation metrics include accuracy, precision, recall, and F1 score. These metrics provide insights into how well the model is performing.
Suggested Reading:
Crafting Chatbots Using Spacy NLP: Beginner's Guide
Several metrics can be used to evaluate the performance of a text classifier. These metrics help assess how well the classifier is predicting the correct labels. Here are some common evaluation metrics for text classification:
Accuracy: The ratio of correctly predicted instances to the total number of instances. It provides an overall understanding of how well the model performs.
Precision: The ratio of true positive predictions to the sum of true positive and false positive predictions. It measures the proportion of correctly predicted positive instances out of all instances predicted as positive.
Recall: The ratio of true positive predictions to the sum of true positive and false negative predictions. It measures the proportion of correctly predicted positive instances out of all actual positive instances.
F1 Score: The weighted average of precision and recall. It balances between precision and recall, providing a single metric to evaluate the model's performance.
Evaluating these metrics helps in understanding the strengths and weaknesses of the text classifier. It allows for fine-tuning and improving the model's performance by adjusting hyperparameters or incorporating additional features or techniques.
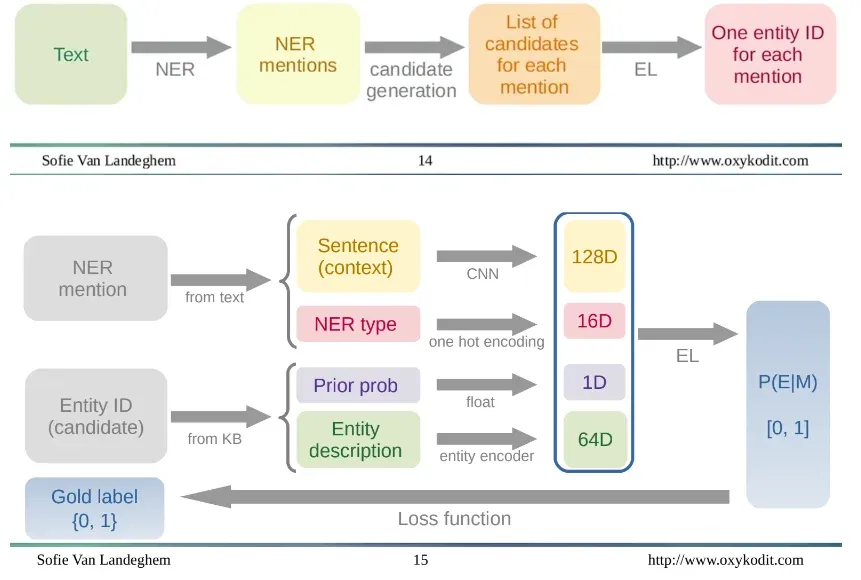
Entity Linking is the process of connecting named entities mentioned in text to a knowledge base, such as Wikipedia or Freebase.
It involves identifying the specific entity being referred to and linking it to its corresponding entry in the knowledge base.
Entity Linking plays a crucial role in text analysis by enhancing the understanding of textual data and enabling further analysis and insights.
Spacy provides built-in capabilities for performing Entity Linking tasks.
By integrating Spacy with external knowledge bases, it becomes possible to link recognized named entities in text to their corresponding entries in those knowledge bases.
Spacy leverages its powerful NLP capabilities to accurately detect and classify named entities and map them to relevant entities in the knowledge base.
While Spacy offers valuable features for Entity Linking, it is important to know its limitations and challenges. Some of these include:
Ambiguity: Textual data can contain ambiguous mentions of named entities, making it challenging to link them accurately to the correct entry in a knowledge base.
Coverage: The knowledge base used for Entity Linking may not cover all possible named entities, leading to incomplete or inaccurate linkages.
Domain-specific Entities: Spacy's pre-trained models might struggle with domain-specific named entities not well-represented in the training data.
Disambiguation: Resolving entity ambiguity, especially for entities with multiple possible referents, can be a complex task that requires additional context.
Performance: Entity Linking can be computationally expensive, especially when dealing with large volumes of textual data.
By being aware of these challenges, researchers and practitioners can better understand the potential limitations and strategize ways to overcome them when using Spacy for entity-linking tasks.
As the volume of generated text data explodes, deriving value from unstructured sources becomes pivotal for data-driven decisions.
Industrial NLP libraries like spaCy enable scalable text analytics leveraging the latest advancements in deep learning and transformers.
With pre-trained statistical models, spaCy delivers enterprise-grade performance out of the box for common tasks like named entity extraction, intent classification, keyword flagging, and sentiment analysis. The ability to handle text processing across massive datasets suits high throughput use cases.
According to projections by Expert.ai, NLP adoption will be near 80% by 2025 across verticals. Solutions like spaCy simplify deploying text analytics by abstractions like pre-processing pipelines and model packaging.
Integrations with leading data science stacks also ease end-to-end workflow creation from ingestion to visualization.
As global data volumes grow exponentially, extracting intelligence from multilingual text is key to value creation. With proven accuracy, scalability, and active development, spaCy delivers versatility and reliability for production NLP.
Its balance of usability and customization makes spaCy the leading choice for unlocking text insights across applications.
SpaCy isn't primarily designed for sentiment analysis, but it can be combined with machine learning techniques to perform sentiment analysis by training models on labeled data or using pre-existing models.
SpaCy is favored in NLP for its speed, accuracy, and efficiency in handling various NLP tasks like tokenization, named entity recognition, part-of-speech tagging, and dependency parsing.
Text preprocessing in spaCy involves tasks like tokenization, lemmatization, removing stop words, and entity recognition, preparing text for analysis by converting it into a format suitable for machine learning models.
SpaCy can be used for a wide range of NLP tasks, including but not limited to named entity recognition, part-of-speech tagging, dependency parsing, text classification, and semantic similarity analysis.
SpaCy utilizes convolutional neural networks (CNNs) for sentence classification and deep learning models for tagging, parsing, and named entity recognition, offering high performance in NLP tasks.
Subscribe to Our Newsletter
Get the latest business insights straight into your inbox.
Checkout our related blogs you will love.
Updated at May 28, 2026
5 min to read

Updated at May 1, 2026
10 min to read

Updated at Jan 17, 2026
9 min to read
Updated at Dec 2, 2023
5 min to read

Updated at Jul 3, 2026
15 min to read

Updated at Jul 3, 2026
10 min to read
Table of Contents