
Introduction
Recent data show that spaCy has emerged as one of the strongest and fastest NLP libraries available. It has earned the respect of researchers and engineers worldwide for its accuracy and speed of sound.
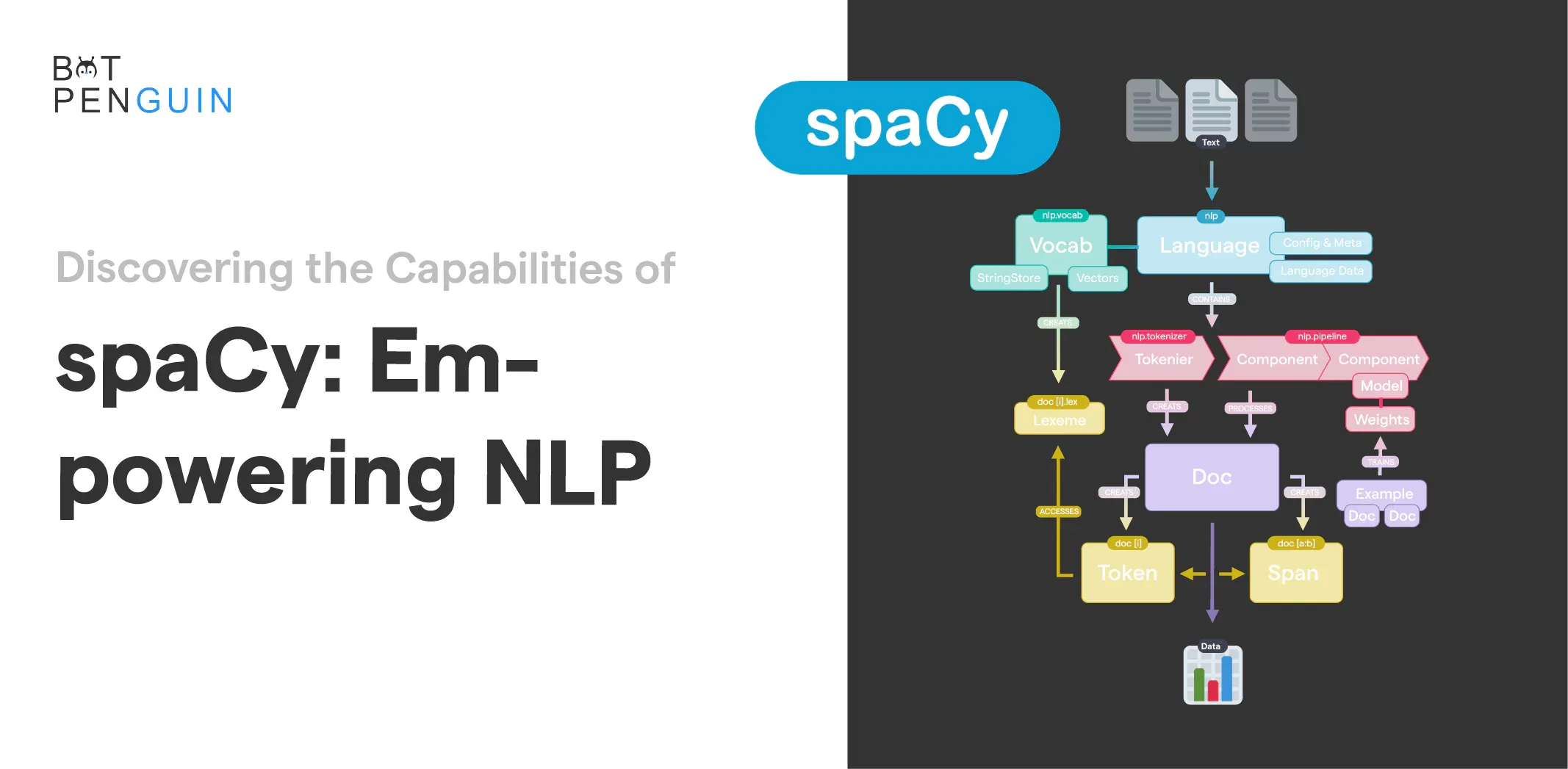
At its core, spaCy is a natural language processing library crafted to deliver cutting-edge performance in tasks ranging from basic tokenization to complex entity recognition and dependency parsing. Its design prioritizes speed without compromising accuracy, making it a preferred choice for both research and production environments.
SpaCy's user-friendly interface, which welcomes both seasoned NLP professionals and newbies, is what truly sets it apart.
One of the standout features of spaCy is its Named Entity Recognition (NER) capabilities, which enable the identification and classification of entities such as people, organizations, locations, and more within a given text. This functionality spaCy’s NER feature serves as a cornerstone for numerous NLP applications. It including information extraction, sentiment analysis, and content categorization.
But that’s not the end of the capabilities of spaCY. Continue reading to discover more capabilities of spaCy to empower NLP.
What is spaCy?
spaCy is an open-source natural language processing (NLP) library designed for efficiency and ease of use. It provides tools for tokenization, named entity recognition, part-of-speech tagging, dependency parsing, and more. spaCy's pre-trained models and customizable pipelines make it a popular choice for NLP tasks in various applications.
Key Features of spaCy
Let's examine the characteristics that set spaCy apart from the competition in more detail:
Efficient Tokenization
The technique of dividing text into smaller pieces, such as words or phrases, is known as tokenization. Tokenization is simple using spaCy. Contraction handling, punctuation, and special characters are among the sophisticated tokenization jobs that it is capable of performing.
Part-of-Speech Tagging and Dependency Parsing
With the help of spaCy's part-of-speech tagging feature, you can determine the grammar-related parts of each word in a phrase. Additionally, its dependency parsing capability enables you to extract important insights from text data by assisting you in understanding the links between words.
Named Entity Recognition (NER)
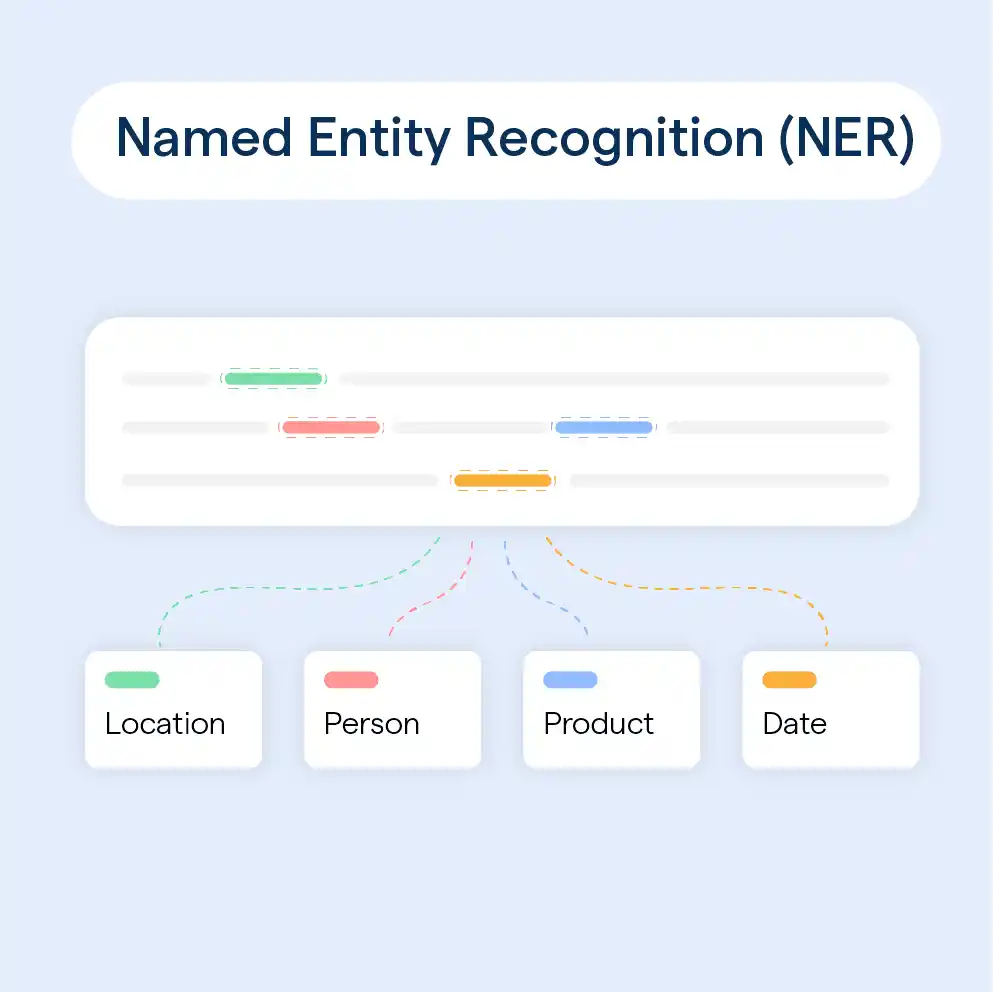
NLP's named entity recognition duty is essential, and spaCy does it exceptionally well. It can recognize and categorize named entities, including persons, groups, places, and more. This function works very well for information extraction.
How Does spaCy Work?
SpaCy is based on effective algorithms and sound language foundations. Its design is pipeline-based, with each element in the pipeline carrying out a distinct NLP job. This modular architecture enables adaptability and simple customization.
Any NLP pipeline starts with tokenization, and spaCy is excellent at it. Text may be intelligently divided into tokens while considering linguistic conventions. The tokenization capabilities of spaCy are excellent, whether dealing with contractions, punctuation, or unusual characters.
After the text has been tokenized, spaCy may provide each token part-of-speech tag, giving useful details about its grammatical function. Additionally, you may derive valuable insights from text data by using spaCy's dependency parsing capability to comprehend the syntactic links between words.
Getting Started with spaCy
In this section, you will find how to begin your journey with spaCy.
Step 1
Installation
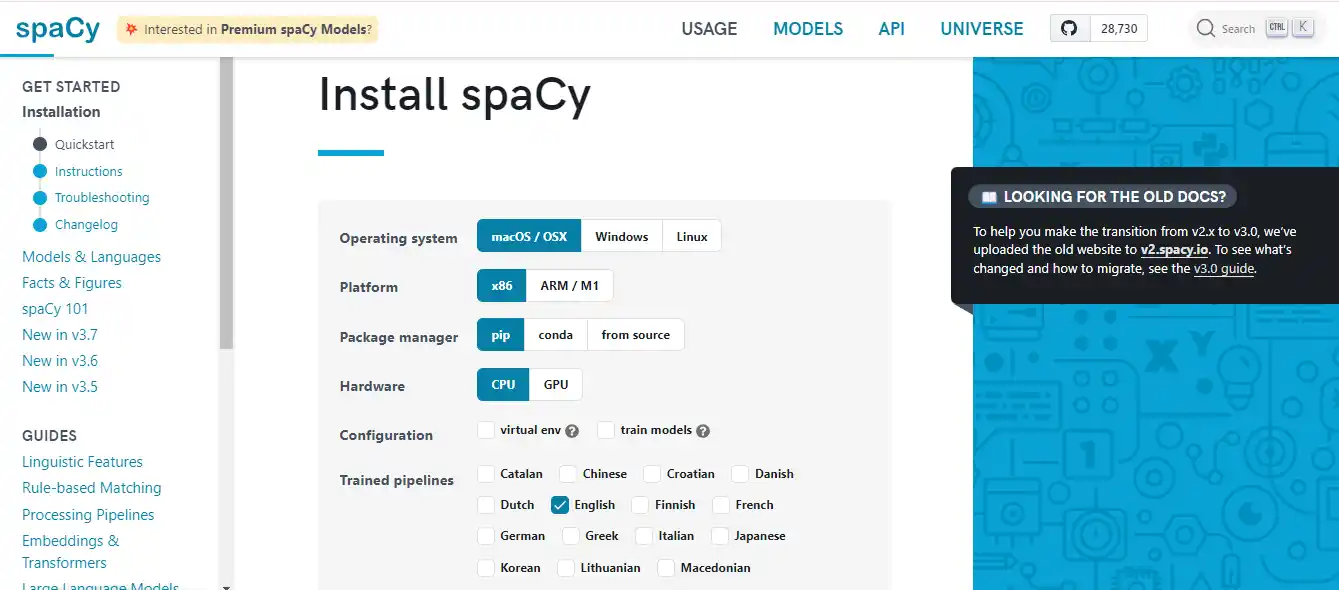
Start by installing spaCy via pip: pip install spacy.
Step 2
Language Models
Download a pre-trained language model suitable for your task, like en_core_web_sm for English.
Step 3
Initialization
Load the downloaded model using spacy.load().
Step 4
Processing Text
Use the loaded model to process text data, which involves tokenization, part-of-speech tagging, and more.
Step 5
Accessing Annotations
Access annotations such as named entities, part-of-speech tags, and dependencies through spaCy's document object.
Step 6
Customization
Customize spaCy's pipeline for specific tasks by adding or modifying components like entity recognizers or parsers.
Step 7
Practice
Experiment with spaCy's functionalities through hands-on practice and explore its documentation for further guidance.
And beginning with NLP powered chatbot isn't that tough. Meet BotPenguin- the home of chatbot solutions.
With BotPenguin you can easily train your chatbot on custom data, paint them with your logo and branding, and offer human-like conversational support to your customers.
And that's not it. BotPenguin makes sure that you reach your customers where they are by offering AI chatbots for multiple platforms, thus making omnichannel support look easy:
- WhatsApp Chatbot
- Facebook Chatbot
- Wordpress Chatbot
- Telegram Chatbot
- Website Chatbot
- Squarespace Chatbot
- Woocommerce Chatbot
- Instagram Chatbot
- MS-Teams Chatbot
- Shopify Chatbot
Advanced NLP Tasks with spaCy
Utilizing spaCy, develop your NLP knowledge by taking on challenging assignments, like:
Named Entity Recognition (NER)
NLP's named entity recognition responsibility is important, and spaCy makes it simple. You may extract useful information from text data and obtain deeper insights with spaCy's NER capabilities.
Entity Linking
By linking named entities to a knowledge base, entity linking advances natural language processing (NLP). With the help of this potent method, you may improve the accuracy and contextual information of your NLP applications.
Suggested Reading:
Exploring Chatbot Frameworks that Integrate Well with spaCy
Text Classification and Sentiment Analysis

One frequent NLP problem is text categorization, and spaCy offers strong tools to handle it. You can train and improve the pre-trained text categorization models provided by spaCy. With sentiment analysis NLP can identify the mood or emotion communicated in a text.
Integrating spaCy with Other Tools and Libraries
By smoothly combining spaCy with other potent tools and libraries, you may advance your NLP efforts. So here’s it:
Python Ecosystem: Leverage spaCy within the Python ecosystem seamlessly due to its compatibility with other popular libraries like NumPy, Pandas, and scikit-learn.
Deep Learning Frameworks: Integrate spaCy with deep learning frameworks such as TensorFlow or PyTorch for advanced NLP tasks like text classification or sequence labeling.
Visualization Tools: Visualize spaCy's outputs using libraries like Matplotlib or Seaborn to gain insights into linguistic patterns or model performance.
Web Frameworks: Incorporate spaCy into web applications using frameworks like Flask or Django to build NLP-powered features such as sentiment analysis or chatbots.
Cloud Services: Deploy spaCy models on cloud platforms like AWS or Azure for scalable and efficient NLP applications.
Conclusion
In conclusion, delving into the capabilities of spaCy unveils a powerful toolkit that significantly empowers Natural Language Processing (NLP).
Through its integration with Python, spaCy offers an accessible yet robust solution for a diverse range of language-related tasks.
The features of spaCY include advanced functionalities like Named Entity Recognition (NER) and dependency parsing. It has uses in both research and industry settings.
The design of spaCy not only prioritizes speed and efficiency but also ensures high levels of accuracy. Hence, it is essential for extracting meaningful insights from vast amounts of unstructured text data.
Its NER capabilities enable the identification and classification of entities with remarkable precision. Thus laying the groundwork for many NLP applications, from information extraction to sentiment analysis.
As the field of NLP continues to evolve, spaCy stands as a beacon of empowerment for NLP.


