

Fine-tuning large language models like Dolly 2.0 has become a popular approach for creating customized AI assistants tailored to specific domains or tasks. According to a recent report by Anthropic, the company behind Dolly 2.0, their model has shown impressive performance in various natural language processing tasks, outperforming GPT-3 on several benchmarks.
The fine-tuning process involves taking a pre-trained language model like Dolly 2.0 and further training it on a dataset specific to the desired use case. This allows the model to learn and adapt to the unique language patterns, terminology, and domain knowledge required for that particular task or industry.
According to a study published in the journal Nature Machine Intelligence (Volume 5, Issue 3, March 2023), fine-tuned language models have proven to be highly effective in various applications, such as question-answering, text summarization, and even code generation. The study found that fine-tuned models outperformed their non-fine-tuned counterparts by a significant margin, with improvements ranging from 10% to 30% on various metrics.
As the demand for specialized AI assistants continues to grow, fine-tuning approaches like those used with Dolly 2.0 are expected to play a crucial role in enabling businesses and organizations to develop customized AI solutions tailored to their specific needs.
What is Dolly 2.0?

Dolly 2.0 is an open-source Language Model (LLM) that possesses ChatGPT-like capabilities. It is a part of the Pythia model family developed by EleutherAI. Dolly 2.0 has been fine-tuned using a dataset of human-generated instructions, allowing it to generate responses that simulate conversation with a human-like touch.
Advantages of Using Dolly 2.0
When it comes to building your own chatbot, Dolly 2.0 offers several advantages over proprietary models.
Accessible and Cost-effective: Dolly 2.0's open-source nature means it is accessible to everyone. There are no proprietary restrictions or costly licenses to worry about. You can freely use and modify the model to suit your requirements, making it a cost-effective solution for creating your own chatbot.
Customizable to Specific Purposes and Domains: Dolly 2.0 provides the flexibility to fine-tune the model according to your specific needs. Whether you're building a chatbot for customer support, content recommendations, or interactive storytelling, you can train Dolly 2.0 on your desired dataset to create a chatbot that fits your purpose and domain.
Open Source Enables Transparency and Control: Being open-source, Dolly 2.0 allows for complete transparency and control over the model. You can examine and understand the inner workings of the model, ensuring that it aligns with your ethical considerations and regulatory requirements. This transparency empowers you to have full control over your chatbot and its behavior.
Getting Started with Dolly 2.0
If you're eager to explore Dolly 2.0's capabilities, you're in the right place. In this guide, we'll walk you through the initial steps of working with Dolly 2.0, from setting up the necessary prerequisites to understanding the pre-trained dataset. Let's get started!
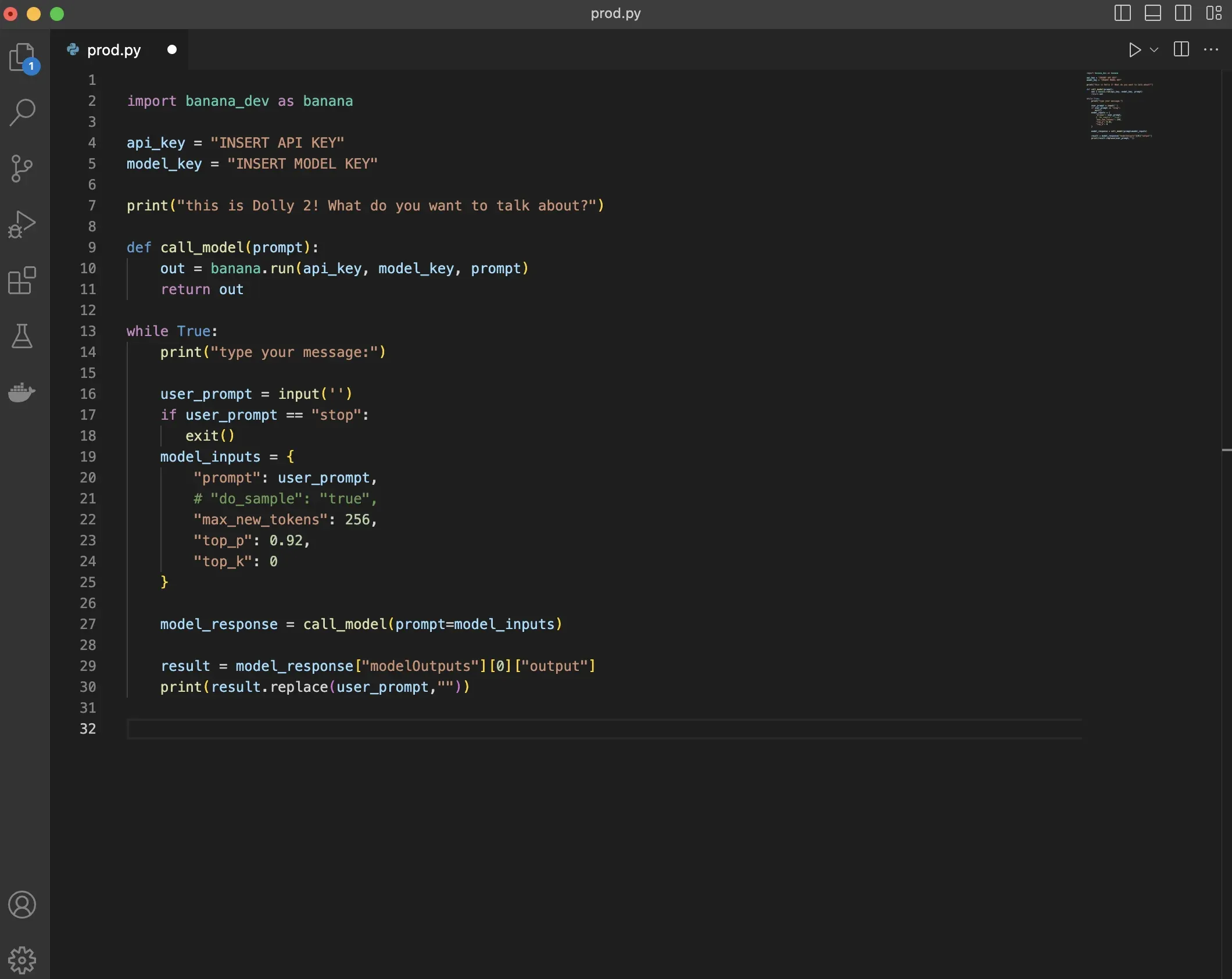
Prerequisites
Before you begin, make sure you have the following prerequisites in place:
Hardware: Ensure that you have a computer or server with sufficient resources, such as CPU and RAM, to handle the training process.
Software: Install Python and the necessary libraries, such as TensorFlow, PyTorch, and Hugging Face's Transformers, which are essential for working with Dolly 2.0.
Data: Obtain the pre-trained Dolly 2.0 model and the associated dataset. This dataset, known as databricks-dolly-15k, contains pairs of instructions and responses that serve as the foundation for training the model.
Choosing Your Training Environment
Once you have the prerequisites in place, you need to decide on your training environment. You have two main options: a local setup on your own machine or utilizing a cloud-based solution.
Local Setup: If you prefer to train Dolly 2.0 on your local machine, ensure that you have enough computational resources and available storage space to handle the training process effectively.
Cloud-Based Solution: Alternatively, you can leverage cloud platforms like Google Cloud or Amazon Web Services (AWS) to train Dolly 2.0. With a cloud-based setup, you can take advantage of powerful computing resources and scale your training capacity as needed.
Installing and Setting up Dolly 2.0
To install and set up Dolly 2.0, follow these steps:
Install the required Python libraries, such as TensorFlow and PyTorch, on your machine.
Download the Dolly 2.0 model and the associated dataset (databricks-dolly-15k).
Import the Dolly 2.0 model into your Python environment.
Preprocess the databricks-dolly-15k dataset to prepare it for training with Dolly 2.0.
Train Dolly 2.0 using the preprocessed dataset, allowing it to learn from the provided instruction-response pairs.
Just cutting this in between, but on second thoughts, you need not go the long way to create smart AI chatbots when you can just create your own AI chatbots in a few clicks!
Because if you want to create a chatbot but have no clue about how to use language models to train your chatbot, then check out the NO-CODE chatbot platform, named BotPenguin.
With all the heavy work of chatbot development already done for you, BotPenguin allows users to integrate some of the prominent language models like GPT 4, Google PaLM, and Anthropic Claude to create AI-powered chatbots for platforms like:
- WhatsApp Chatbot
- Facebook Chatbot
- Wordpress Chatbot
- Telegram Chatbot
- Website Chatbot
- Squarespace Chatbot
- Woocommerce Chatbot
- Instagram Chatbot
Exploring the databricks-dolly-15k Dataset
Before you dive into training, it's important to understand the structure and composition of the databricks-dolly-15k dataset.
Structure and Composition of the Instruction Pairs
The dataset consists of pairs of instructions and responses. Each instruction serves as a prompt for Dolly 2.0, and the corresponding response represents the desired reply from the model. The dataset contains a diverse range of prompts and responses, covering various topics and scenarios.
Understanding the Diverse Prompts and Responses
The prompts in the dataset encompass a wide array of sentence structures, including questions, statements, and instructions. These prompts can cover different domains, such as customer support, entertainment, or information retrieval. The responses are designed to be fitting replies to the prompts, leveraging Dolly 2.0's capabilities to generate coherent and relevant replies.
Potential Limitations and Considerations
It's important to note that while the databricks-dolly-15k dataset is extensive, it may not cover all possible conversation scenarios. As a result, there may be instances where Dolly 2.0 might struggle to generate appropriate responses or fail to fully understand ambiguous or complex queries. These limitations highlight the constant evolution of language models and the need for ongoing training and improvement.
Fine-tuning Process and Techniques
Now that you have a solid understanding of Dolly 2.0, it's time to fine-tune the model to your specific use case. Fine-tuning involves adapting a pre-trained model to a specific domain by training it on a domain-specific dataset, which improves its performance and response accuracy. In this guide, we'll cover the key steps and best practices for fine-tuning Dolly 2.0.
Selecting Relevant Data for Your Specific Use Case
To fine-tune Dolly 2.0 effectively, you need a domain-specific dataset that's relevant to your use case. This dataset should be diverse and represent a wide range of scenarios you expect your Dolly model to handle. To select the relevant data:
Identify your use case, including the intended application and target audience.
Choose a dataset that corresponds to the specific domain and matches the audience's language patterns.
Evaluate the dataset to ensure it contains sufficient data samples and variations for your target application.
Optimizing Hyperparameters for Best Performance
Hyperparameters play a crucial role in fine-tuning Dolly 2.0. These parameters control various aspects of the model's training process and directly impact its performance. Some of the key hyperparameters to optimize include the learning rate, the batch size, the number of training epochs, and the loss function.
To optimize the hyperparameters for your specific use case, follow these steps:
Define the hyperparameters and their range of possible values.
Create a search space for these parameters using techniques such as grid search or random search.
Conduct experiments to find the best combination of hyperparameters for your use case.
Test and validate your top-performing model on a test or validation dataset to ensure it meets your performance criteria.
Monitoring and Evaluating the Training Process
To fine-tune Dolly 2.0 effectively, you need to monitor and evaluate the training process to ensure that the model is learning and improving. Here are some key steps to follow:
Define your training metrics, such as accuracy or F1-score, for tracking the model's performance during training.
Monitor the training process by visualizing the changes in the selected metrics over time.
Use early stopping to prevent overfitting by stopping the training process when the model's performance on a validation dataset begins to decline.
Evaluate the final model's performance on an unseen dataset to validate its generalization capability.
Troubleshooting Common Fine-tuning Issues
Despite following best practices, fine-tuning Dolly 2.0 may encounter some common issues that require attention. Here are some potential issues and ways to troubleshoot them:
Overfitting and Underfitting
Overfitting: Occurs when the model performs well on the training dataset but fails to generalize to unseen data. To prevent overfitting, reduce the model's complexity by optimizing the hyperparameters and increasing the size of the dataset or applying regularization techniques.
Underfitting: Occurs when the model fails to learn from the training data and struggles to achieve the target performance. To address underfitting, increase the model's complexity by adding more layers or neurons, increasing its capacity to learn from the data.
Data Quality and Quantity Limitations
Data Quality: When the dataset contains errors, duplicates, or missing samples, the model's effectiveness may be compromised. Ensure that the dataset is correctly labeled and preprocessed, removing any spam, irrelevant data, or inconsistencies.
Data Quantity: When there is a limited amount of data, the model may not generalize to new, unseen cases. That's why it's essential to collect sufficient data to ensure the model's learning capabilities.
Gradient Descent Challenges
Learning Rate: If the learning rate, which controls the magnitude of the model's weight adjustments during training, is too high or too low, the optimization process may become unstable. Choose a learning rate that's appropriate for your use case.
Convergence: If the gradient descent algorithm fails to converge, the model's performance may be impacted. To address this, experiment with different optimization algorithms or reduce the model's complexity.
Deploying and Using Your ChatGPT-like Model
Once you have fine-tuned your ChatGPT-like model, it's time to deploy it and start using it in real-world scenarios. Let's explore some important aspects of this process.
Integrating with Applications and Interfaces
To make the most of your model, you'll need to integrate it with different applications and interfaces. This could include chatbots, virtual assistants, customer support systems, and more. By seamlessly combining your model with these platforms, you can enhance their capabilities and provide better experiences for users.
Prompt Engineering for Effective Interaction
Prompt engineering refers to the art of crafting effective instructions or prompts for your model. By providing clear and concise prompts, you can guide the model towards generating more accurate and desired responses. Experiment with different types of prompts to optimize the model's performance and achieve meaningful interactions.
Handling Potential Misuse and Biases
As powerful as AI models can be, they may also face potential issues related to misuse and biases. It's crucial to consider and address these concerns. Implement safeguards to prevent harmful or inappropriate behavior from the model. Additionally, be aware of biases that may exist in the training data and take steps to mitigate them.
Best Practices for Responsible AI Development
Responsible AI development involves upholding ethical standards and ensuring fairness and transparency. Consider data privacy and security concerns to protect user information. Take proactive measures to mitigate biases and promote fairness in the model's outputs. Strive for transparency and explainability so that users can understand how the model makes its decisions.
Advanced Techniques and Extensions
Once you have a solid foundation with your ChatGPT-like model, there are several advanced techniques and extensions you can explore to enhance its capabilities further.
Exploring Larger Pre-trained Models for Fine-Tuning
You can go beyond the initial model architecture and consider using larger pre-trained models as the starting point. These models have been trained on extensive datasets and may offer improved performance. Fine-tuning these models allows for even more powerful and sophisticated language understanding and generation.
Customizing the Instruction Dataset for Specific Domains
To make your model more relevant to particular fields or industries, you can customize the instruction dataset. By incorporating domain-specific prompts and responses, you can ensure that the model understands and generates accurate content tailored to a specific area of expertise.
Incorporating Multi-Modality and Real-time Data
Expanding the model's capabilities beyond text is an exciting area to explore. By incorporating multi-modality, such as images, videos, or audio, you can enable your model to understand and generate content from multiple sources. Additionally, working with real-time data allows the model to dynamically respond to changing contexts and situations.
Exploring the Future of ChatGPT-like Models
The future of ChatGPT-like models is filled with both potential applications and challenges. These models can revolutionize customer support, online learning, creative writing, and much more. Ongoing research and development efforts are constantly improving fine-tuning techniques, taking us closer to more accurate and coherent conversations. The democratization of large language models ensures that access to these technologies is not limited to a privileged few but is available to a wider audience.
Conclusion
In conclusion, the ability to fine-tune powerful language models like Dolly 2.0 has opened up new possibilities for creating highly specialized and customized AI assistants. As the demand for domain-specific AI solutions continues to rise, fine-tuning approaches have become a game-changer, allowing businesses and organizations to tailor these models to their unique requirements.
According to their findings, over 40% of Fortune 500 companies have already implemented or are actively exploring fine-tuned language models for tasks such as customer service, content creation, and data analysis.
BotPenguin has been at the forefront of this movement by making AI technology accessible to everyone with its simple DRAG-N-DROP AI chatbot builder.
As the capabilities of language models continue to evolve, simple one-click language model integration by BotPenguin is expected to play a pivotal role in unlocking the full potential of these powerful AI systems, enabling a future where highly specialized and intelligent assistants become an integral part of our daily lives.
Frequently Asked Questions (FAQs)
What is Dolly 2.0's fine-tuning feature and how does it work?
Dolly 2.0's fine-tuning feature allows users to customize the model to understand specific types of language by using smaller, domain-specific datasets. Users can use their own data to train Dolly 2.0 to understand and generate content related to a specific topic.
How to fine-tune Dolly 2.0 for my specific use case?
First, you'll need to source a dataset specific to your use case. Then, use Dolly 2.0's fine-tuning capability to train the model on your dataset. Once the fine-tuning process is complete, you can use the newly trained model to generate content or for semantic search purposes.
What are the benefits of fine-tuning Dolly 2.0 for a specific use case?
Fine-tuning Dolly 2.0 allows you to create a chatbot-like model that is tailored to your specific use case and can better understand the nuances of the language used within your domain. This, in turn, can lead to more accurate, relevant, and useful outputs.
Are there any limitations to Dolly 2.0's fine-tuning capability?
Dolly 2.0 still needs a significant amount of data to fine-tune properly. The larger the dataset and the higher the quality, the better the results. Additionally, depending on the complexity of the task, you may need to fine-tune Dolly 2.0 multiple times to achieve optimal results.
What is the best way to get started with fine-tuning Dolly 2.0?
Start by exploring documentation and tutorials related to fine-tuning Dolly 2.0 that are available online. Familiarize yourself with the model architecture, tasks, and use cases. Then, experiment with using Dolly 2.0's fine-tuning feature and continue to refine your approach until you achieve the desired results.


