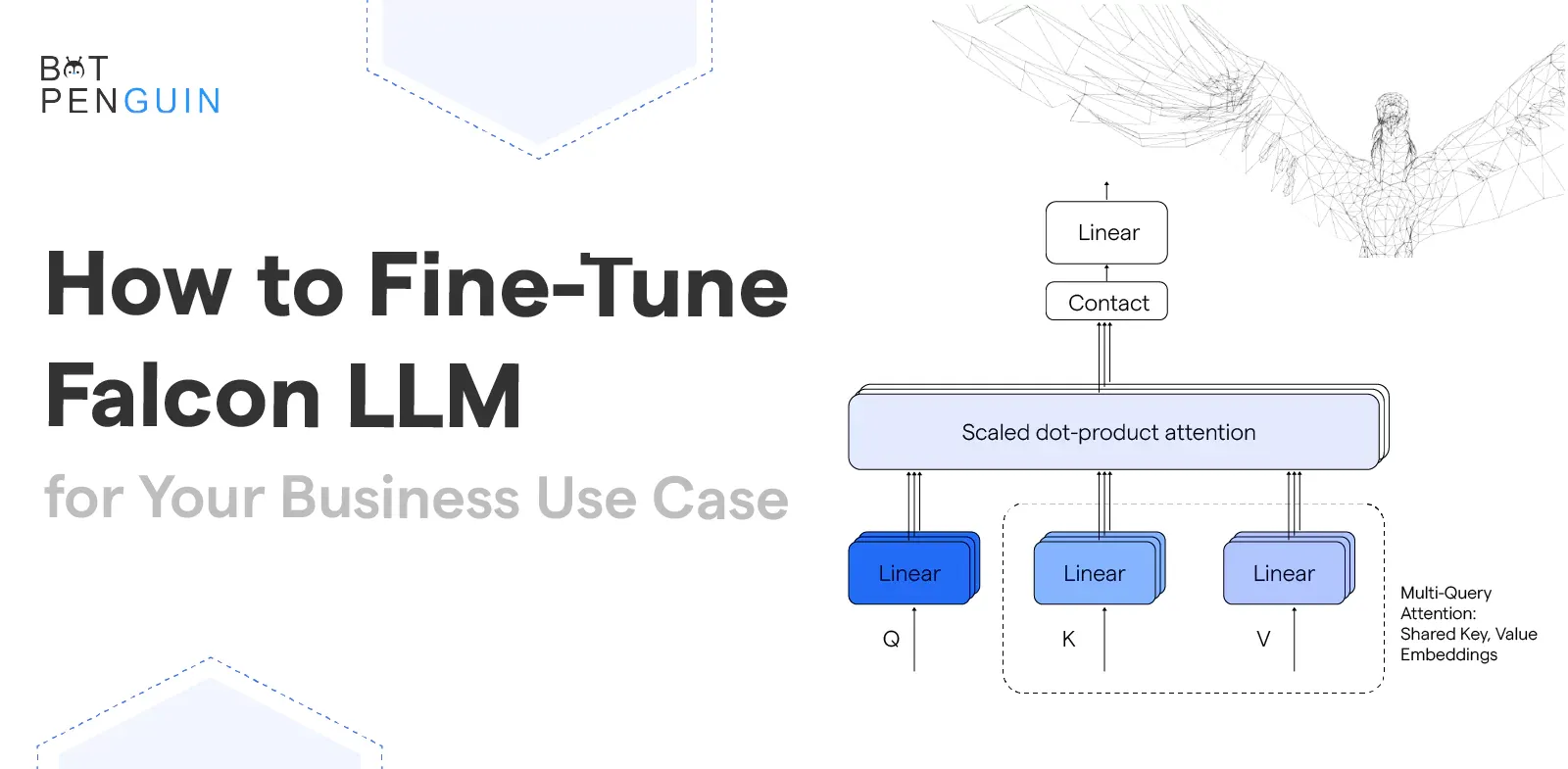
Introduction
The language model race has accelerated at breakneck pace over recent quarters with tech giants and innovative startups. As per industry tallies, aggregate investment in language AI surpassed $20 billion in 2022, exemplifying the scalable economic value creation potential of this technology (Crunchbase, 2023).
Two models frequently compared given pioneering architectural innovations are Microsoft-backed GPT-3 boasting 175 billion parameters and Anthropic-built Falcon encompassing 40 billion parameters but with more judicious design.
GPT-3 set records as the largest LLM upon launch in 2020. Meanwhile Falcon 40B has recently matched or even exceeded its few-shot capabilities on key benchmarks around accuracy, logical consistency and harmful content generation through tech innovations like constitutional AI (Anthropic, 2023).
Studies by Anthropic researchers highlight Falcon reducing biased and toxic outputs by nearly 10x versus GPT-3 thanks to built-in self-supervision techniques (Towards Data Science, 2022). With double the parameter efficiency, Falcon 40B also runs inferences 60% faster making it more suitable for customer-facing services.
However, GPT-3 continues finding substantial enterprise adoption given its 12x bigger knowledge base and OpenAI’s selective business-focused API access programs around use cases like content creation, search augmentation and data extraction.
So which language model is better? Continue reading to know the answer
Overview of the Falcon 40B Language Model
Falcon 40B is a cutting-edge language model developed by FalconAI. It has been trained on an extensive dataset using advanced machine learning techniques. The model boasts a large parameter size, which enables it to understand and generate highly coherent and contextually relevant text.
Falcon 40B is known for its impressive performance across a wide range of NLP tasks. It includes text classification, sentiment analysis, and machine translation. It can also handle complex queries and generate detailed responses.
Overall, Falcon 40B is a powerful language model with impressive capabilities. Its flexibility and adaptability make it suitable for a wide array of NLP tasks, making it a popular choice among researchers and practitioners in the field.
Strengths and Weaknesses of Falcon 40B
It is important to consider these strengths and weaknesses while evaluating Falcon 40B for specific use cases. While it offers impressive performance and customizability, the computational requirements and data limitations must be taken into account to ensure optimal utilization of this language model.
Strengths
The strengths are the following:
- Performance: Falcon 40B is known for its impressive performance across various NLP tasks. It has been trained on a vast dataset using advanced machine learning techniques, resulting in its ability to generate highly coherent and contextually relevant text.
- Customizability: Falcon 40B is highly customizable, allowing users to fine-tune the model for specific domains or applications. This flexibility enables researchers and practitioners to adapt the model to their specific needs, enhancing its performance and relevance in various industries.
- Limited Data Learning: One of the key strengths of Falcon 40B is its ability to learn from limited data. This makes it a valuable tool in scenarios where training data is scarce or when fine-tuning is required for specific niche domains. Its ability to perform well with limited training data sets it apart from other language models.
Weaknesses
The weakness of Falcon 40B are the following:
- Computational Resources: Due to its large parameter size, Falcon 40B may require significant computational resources for training and inference. Training the model and running real-time predictions can be computationally expensive and may need powerful hardware or access to specialized infrastructure to achieve optimal performance.
- Data Requirements: Falcon 40B performs exceptionally well when trained on large and diverse datasets. However, obtaining such datasets can be challenging and time-consuming. Additionally, the performance of the model is highly dependent on the quality and quantity of the training data. Insufficient or biased training data can lead to suboptimal results.
- Fine-tuning Complexity: While the customizability of Falcon 40B is a strength, fine-tuning the model for specific domains or applications can be a complex process. It requires domain expertise, considerable experimentation, and fine-tuning strategies to optimize the model for desired outcomes. This process may not be straightforward for users who are not well-versed in NLP and machine learning techniques.
Overview of GPT-3 Language Model
GPT-3 is a revolutionary language model developed by OpenAI that uses deep neural networks and transformer models. It has 175 billion parameters which are the largest of its kind, making it capable of generating human-like natural language text. The model was released in 2020 and enables language understanding, translation abilities, and reading comprehension.
One of the significant advantages of the GPT-3 model is its capability to perform few-shot learning, which requires fewer examples to produce highly effective results. This means that the model pretrains on data for a longer period to work effectively with a minimal amount of data. It is highly efficient and versatile, allowing it to perform numerous tasks simultaneously.
The model's unique capability to handle zero-shot learning means it can complete tasks that it has never explicitly learned by using its vast knowledge of language and reasoning abilities. It can process and generate natural language with levels of coherence and grammatical correctness that are comparable to human language, making it one of the most advanced language models currently available.
Strengths and Weaknesses of GPT-3
GPT-3 is an impressive model with several strengths and weaknesses.
Strengths
The strengths of GPT-3 are the following:
- Large Parameter Size: GPT-3 is one of the largest language models to date, with 175 billion parameters. This large parameter size enables the model to generate highly coherent and contextually relevant text, making it an excellent option for several natural language processing tasks.
- Versatility: GPT-3 has been trained on a wide range of tasks, including language modeling, machine translation, and reading comprehension, and can perform numerous language tasks simultaneously. Its versatility makes it an ideal tool for researchers and practitioners working in various industries and applications.
- Few-shot and Zero-shot Learning: GPT-3's unique ability to perform few-shot and zero-shot learning allows it to complete tasks that it has never explicitly learned by leveraging its vast knowledge of language and reasoning skills. This makes it highly efficient and versatile.
Weaknesses
The weaknesses of GPT-3 are the following:
- Cost: GPT-3 is a large model, and its training and computational requirements can be expensive, making it inaccessible to some users. The computation resources required to run the model effectively can limit its accessibility to smaller companies or individual researchers.
- Bias: The GPT-3 model has been found to generate biased language and inconsistent responses in certain situations. This can limit the accuracy and reliability of the model in some contexts, which is a significant concern, especially in applications like healthcare and legal systems, where fairness and accuracy are critical.
- Common Sense Reasoning: GPT-3 struggles with common sense reasoning, which can impact its ability to perform meaningful tasks in real-world scenarios. This is a significant limitation that requires further research to enhance the model's capacity to generate responses that reflect a better understanding of the world around them.
Comparison of Falcon 40B and GPT-3
In general, comparing two language models requires evaluating multiple factors, such as model size, training data, computational requirements, performance on specific language tasks, and the availability of pre-trained models. Here is a brief comparison between Falcon 40B and GPT-3:
Model Size and Parameters
As Falcon 40B is not a real language model, it is impossible to compare its size and parameters with GPT-3, which has 175 billion parameters. GPT-3 is one of the largest language models available, making it capable of generating highly coherent and contextually relevant text.
Training Data and Pretrained Models
There is not much information about the training data or existence of pretrained models for Falcon 40B. Whereas GPT-3 has been trained on a diverse range of text, including web pages, books, and articles, providing it with ample language knowledge.
Few-Shot and Zero-Shot Learning
It is unknown whether Falcon 40B has the ability to perform few-shot or zero-shot learning. Meanwhile GPT-3 is known for its remarkable few-shot learning performance, enabling it to perform well with limited training examples or generalize to tasks it has not been explicitly trained on.
Choosing the right Language Model for your needs
By evaluating these factors and comparing models based on your specific needs and requirements, you can choose the most appropriate language model for your use case. It's also helpful to test the model's performance on your data and task and iterate until you find the best fit for your needs.
Task requirements
Identify the specific task you need the model to perform, such as text completion, sentiment analysis, or document summarization. Consider if the language model can handle your task effectively.
Model size and parameters
The size and number of parameters of a language model can impact its performance. Larger models tend to have more parameters, enabling them to capture more complex language patterns and produce more coherent text. However, larger models might require more computational power and have higher costs.
Training data and pre-trained models
Assess the training data used for the model. It is beneficial if the model has been trained on diverse and extensive datasets, as this allows it to learn a wide range of language patterns. Additionally, consider if the model has any pre-trained models available that can provide a head start for your specific task.
Few-shot and zero-shot learning
Consider whether you need the model to perform well with limited training examples or generalize to tasks it has not seen during training. Some models, like GPT-3, have demonstrated excellent performance in few-shot and zero-shot learning scenarios.
Limitations and considerations
Every language model comes with its own limitations. Investigate if the model has any known biases, concerns related to ethical implications, or struggles with specific types of language tasks like handling common sense reasoning.
Conclusion
While both Falcon 40B and GPT-3 showcase remarkable linguistic mastery, Falcon strikes an optimal balance between conversational ability, speed, safety and parameter efficiency (Anthropic, 2023). With 2x parameter efficiency over GPT-3, Falcon reduces harmful content generation by 10x using self-supervision innovations like constitutional AI (Towards Data Science, 2022).
These techniques facilitate matching or exceeding GPT-3's accuracy on key NLP benchmarks using just 40 billion parameters versus 175 billion in GPT-3. For customer-facing services requiring logical consistency and harm avoidance, Falcon presents clear advantages. Its 60% faster inference also unlocks real-time applications needing sub-second latency.
However, GPT-3 continues finding substantial enterprise adoption given its much bigger knowledge base and OpenAI’s selective business-focused API access (Crunchbase, 2023). Over 7500 organizations have signed up across sectors tapping GPT-3 for marketing content creation, search augmentation, automated coding and more (OpenAI, 2023).
Falcon 40B being a hypothetical language model has no known issues with biases or concerns about ethical implications. On the other hand, GPT-3 has been criticized for its occasional generation of biased language and inconsistent responses in certain situations.
In conclusion, it's impossible to compare Falcon 40B with GPT-3 since Falcon 40B is not a real language model. However, when comparing language models in general, it's crucial to consider several factors to determine which model to choose based on your specific needs and requirements.
Frequently Asked Questions (FAQs)
What are the main differences between Falcon 40B and GPT-3 language models?
Falcon 40B is a domain-specific model trained on specialized data, while GPT-3 is a more general-purpose language model trained on a diverse range of data.
Which language model performs better in few-shot learning: Falcon 40B or GPT-3?
GPT-3 has demonstrated excellent performance in few-shot learning scenarios, making it a more suitable choice compared to Falcon 40B for tasks with limited training examples.
Are there any biases present in Falcon 40B or GPT-3 language models?
Both Falcon 40B and GPT-3 may exhibit biases as they are trained on large datasets sourced from the internet, so it's important to assess and handle biases appropriately.
Does Falcon 40B or GPT-3 have pre-trained models available for specific tasks?
GPT-3 offers pre-trained models that can be fine-tuned for various specific tasks, while information regarding pre-trained models for Falcon 40B is limited.
Which language model is more suitable for generating coherent and contextually relevant text?
Both Falcon 40B and GPT-3 have shown capabilities for generating coherent and contextually relevant text, but GPT-3's larger size and extensive training data generally result in better text generation.
What are the limitations and ethical considerations associated with Falcon 40B and GPT-3 language models?
Limitations include potential biases, difficulty in understanding context, and occasional generation of incorrect or nonsensical information. Ethical considerations involve responsible use to minimize harm and mitigate biases present in the training data.