What is Stemming?
Stemming is like cutting words down to their roots. Imagine you have the words "running," "runner," and "ran." Stemming trims these words to their base form, like "run." It's a simple and fast way to group words with similar meanings together. This technique helps search and analyze text by reducing words to their core components.

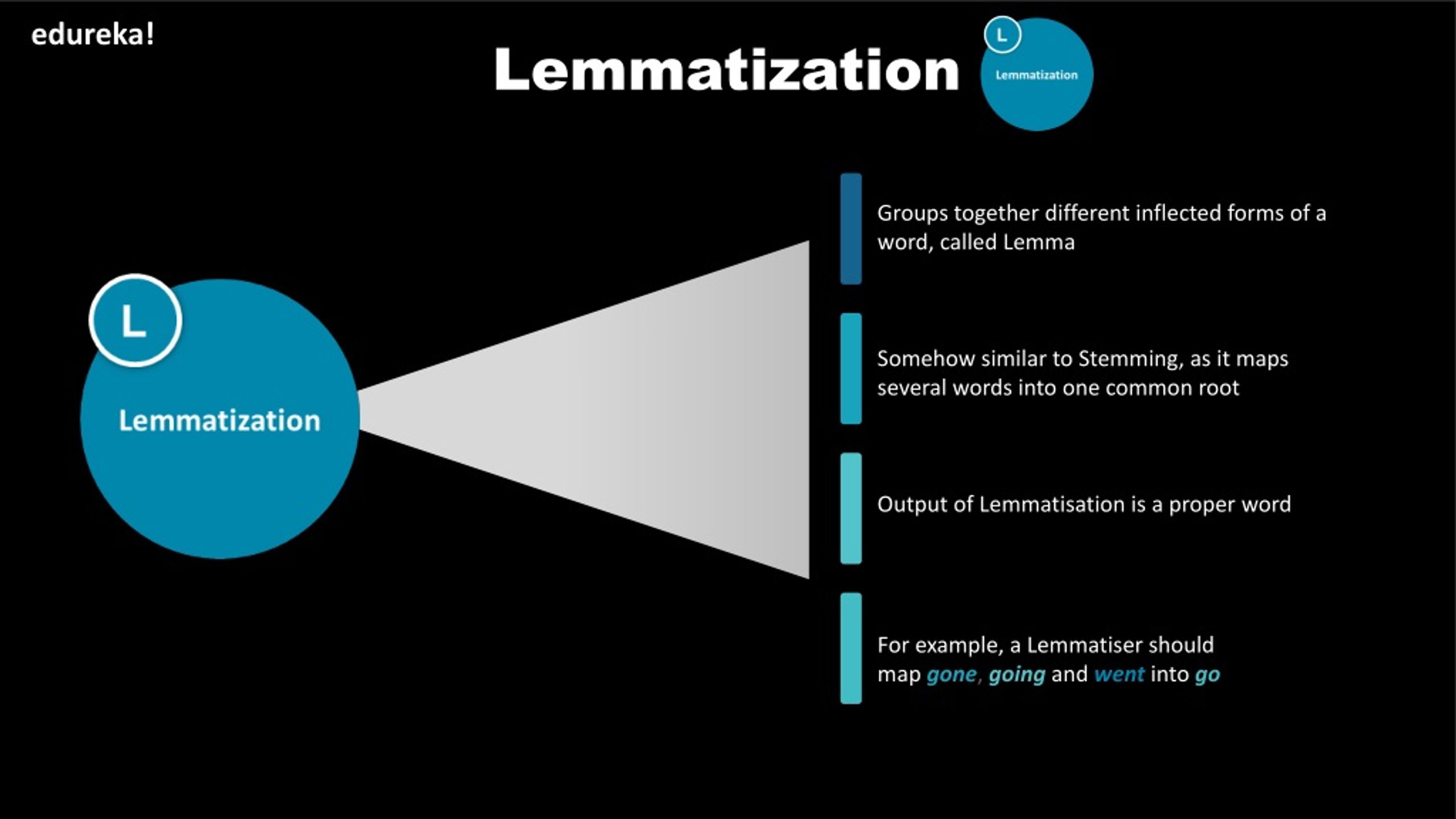
What is Lemmatization?
Lemmatization is a bit more refined than stemming. Instead of just chopping off endings, it looks at the word's meaning and reduces it to its proper root word, called a lemma. For example, "better" becomes "good," and "running" becomes "run." This process takes context into account, which makes it more accurate.
Why are Stemming and Lemmatization Important?
Stemming and lemmatization are crucial in processing text data. They simplify words to their base forms, making analyzing large amounts of text easier. This is especially useful in search engines, where matching the base form of words can improve search results. For instance, if you search for "running," you'll also get results for "ran" and "runner."
Improving Search Results: Search engines can match more relevant results by reducing words to their base forms. This leads to better and more accurate search outcomes.
Enhancing Text Analysis: Simplifying words helps compare and categorize text. It makes it easier to perform tasks like sentiment analysis and topic modeling.
Reducing Computational Complexity: Simplifying words reduces unique tokens, decreases dimensionality, and enables faster, more efficient text processing and analysis.
Improving Text Mining Accuracy: Normalizing text enhances algorithm accuracy, aiding in pattern recognition and improving results in text mining and NLP tasks.
Difference Between Stemming and Lemmatization
Stemming and lemmatization are essential techniques in natural language processing (NLP) for reducing words to their base forms. Understanding their differences helps in choosing the appropriate method for specific applications.
| Aspect | Stemming | Lemminization |
| Basic Concepts | Chops off word endings to get the root form. | Considers context, converts words to base form using dictionary. |
| Accuracy | Less accurate, produces words that may not exist. | More accurate, produces actual words.
|
| Processing Time | Faster, involves simple rules. | Slower, looks up words in a dictionary. |
| Use Cases | Useful for quick searches and basic text analysis. | Ideal for high accuracy applications like NLP and machine learning. |
| Complexity | Simpler to implement, involves straightforward rules. | More complex, requires understanding context and part of speech.
|
| Context Handling | Does not consider the context. | Takes context into account for accurate word reduction.
|
| Common Algorithms | Porter Stemmer, Snowball Stemmer. | WordNet Lemmatizer, spaCy's Lemmatizer.
|
| Example Scenarios | Quick, rough search engine indexing, basic text clustering. | Detailed text analysis, semantic understanding in chatbots. |
Benefits of Stemming and Lemmatization in Big Data
Stemming and lemmatization are crucial in big data processing. They optimize text data, enhance search results, improve analysis accuracy, and boost algorithm performance. Understanding stemming vs lemmatization helps in choosing the right technique for various applications
Improving Search Results
Stemming: Helps match different forms of a word, making searches faster and more efficient.
Lemmatization: Provides more accurate search results by matching words based on their meaning.
Enhancing Text Analysis
Stemming: Simplifies words for basic analysis, reducing the complexity of text data.
Lemmatization: Improves the understanding of text, aiding in sentiment analysis and topic modeling.
Optimizing Data Storage
Stemming: Reduces storage needs by shortening words, leading to fewer data to index and manage.
Lemmatization: Ensures meaningful words are stored, keeping data accurate and relevant.
Boosting Algorithm Performance
Stemming: Speeds up data processing tasks, making algorithms run faster.
Lemmatization: Enhances the precision of machine learning models, improving overall data quality.
Simplifying Data Integration
Stemming: Standardizes words for easy merging, helping combine data from different sources.
Lemmatization: Aligns data based on context, ensuring consistent data integration.
Enhancing User Experience
Stemming: Quickens response times in applications, making user interactions smoother.
Lemmatization: Provides more accurate results for users, improving content relevance.
Reducing Redundancy
Stemming: Cuts down on repetitive data, helping manage large datasets.
Lemmatization: Eliminates unnecessary variations, keeping the dataset clean and efficient
Facilitating Natural Language Processing
Stemming: Prepares text for further analysis, simplifying preprocessing steps.
Lemmatization: Enables better semantic understanding, enhancing NLP tasks like entity recognition.
Increasing Efficiency in Big Data Applications
Stemming: Reduces the size of the data, making handling large volumes of data easier.
Lemmatization: Improves the depth of data insights, supporting advanced data analytics.
Supporting Multilingual Data Processing
Stemming: Works across different languages, simplifying multilingual datasets.
Lemmatization: Ensures accurate translation and interpretation, handling language-specific nuances.
In the context of "stemming vs lemmatization," each technique offers unique advantages and is suited for specific needs in big data processing and text analysis.
How Stemming Works
Stemming is a way to simplify words. It cuts down words to their root form. For example, "running" becomes "run." This method helps computers understand text by focusing on the main part of the word.

The Process
Stemming works by chopping off the ends of words. It uses rules to decide which part to remove. For instance, the suffix "-ing" or "-ed" is often cut off. So, "hopped" turns into "hop." This makes it easier to group similar words together.
How Lemmatization Works
Lemmatization goes a step further than stemming. It finds the base form of a word, known as the "lemma." This process looks at the word and its context.

The Process
Lemmatization involves more than just chopping off ends. It uses a dictionary and grammar rules. The computer checks the word's meaning and part of speech. This helps it decide the correct base form.
Frequently Asked Questions(FAQs)
What is the main difference between stemming and lemmatization?
Stemming reduces words to their base or root form in a heuristic process, while lemmatization considers the context and converts the word to its meaningful base form, known as the lemma.
Stemming vs lemmatization: When should they be used?
Stemming should be used for applications that require speed over precision, such as in search engines where the broad matching can be beneficial, and not the detailed context of words is needed.
Does lemmatization require more computational resources than stemming?
Yes, lemmatization generally requires more computational resources than stemming because it involves a deeper linguistic analysis to accurately identify the lemma of each word.
How do stemming and lemmatization impact search engine optimization (SEO)?
Both techniques can improve SEO by enabling search engines to index different forms of a word, thus broadening search capability. However, lemmatization is more sophisticated, potentially providing more accurate search results.
Can stemming and lemmatization be used together in text preprocessing?
Yes, they can be used together in text preprocessing. While it's not common, combining both can allow for broad initial filtering with stemming and refined context understanding with lemmatization.
What are some common algorithms or tools used for stemming and lemmatization?
For stemming, the Porter and Snowball algorithms are widely used. For lemmatization, tools like WordNet Lemmatizer in the Natural Language Toolkit (NLTK) and spaCy's lemmatizer are popular choices among developers.