What is LSTM?
LSTM stands for Long Short-Term Memory. It’s a type of artificial neural network used in machine learning. It helps computers understand and remember patterns in data over long periods.
In other words, LSTM is a special kind of neural network. It can learn and remember things for a long time.
Unlike regular neural networks, which forget quickly, LSTM can keep important information for many steps. This makes it perfect for tasks where the order of things matters, like understanding speech or predicting stock prices.
Importance of LSTM in Machine Learning
LSTM is very important in machine learning. It helps computers do tasks that need memory. Here are some key reasons why LSTM is so valuable:
Handling Sequential Data
LSTM is great for data that comes in a sequence. This includes text, time series, and speech. It can remember important details from earlier in the sequence and use them later. For example, in translating a sentence, LSTM can remember the context of words to make a better translation.
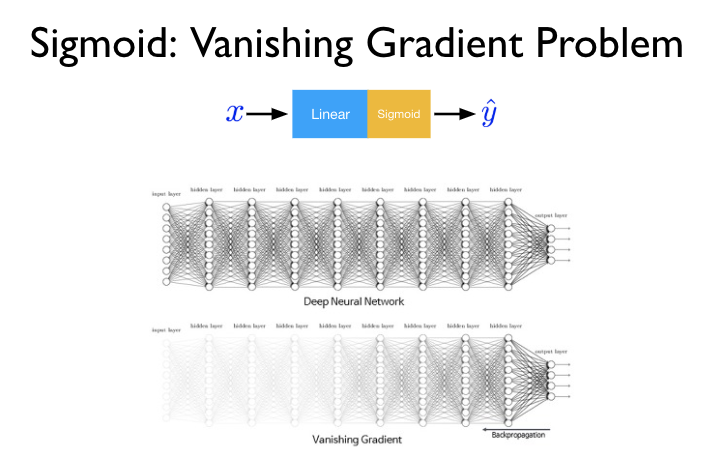
Solving the Vanishing Gradient Problem
One big advantage of LSTM is that it solves the vanishing gradient problem. This problem makes it hard for neural networks to learn from long sequences. LSTM’s design allows it to keep learning effectively, even from long sequences.
Wide Range of Applications
LSTM is used in many fields. In natural language processing, it helps with tasks like translation and text generation. In finance, it’s used to predict stock prices. In healthcare, it helps analyze patient data over time. This versatility makes LSTM a powerful tool in machine learning.
Improved Accuracy
Because LSTM can remember important information for longer, it often performs better than other neural networks on tasks involving sequences. This leads to more accurate predictions and better performance overall.
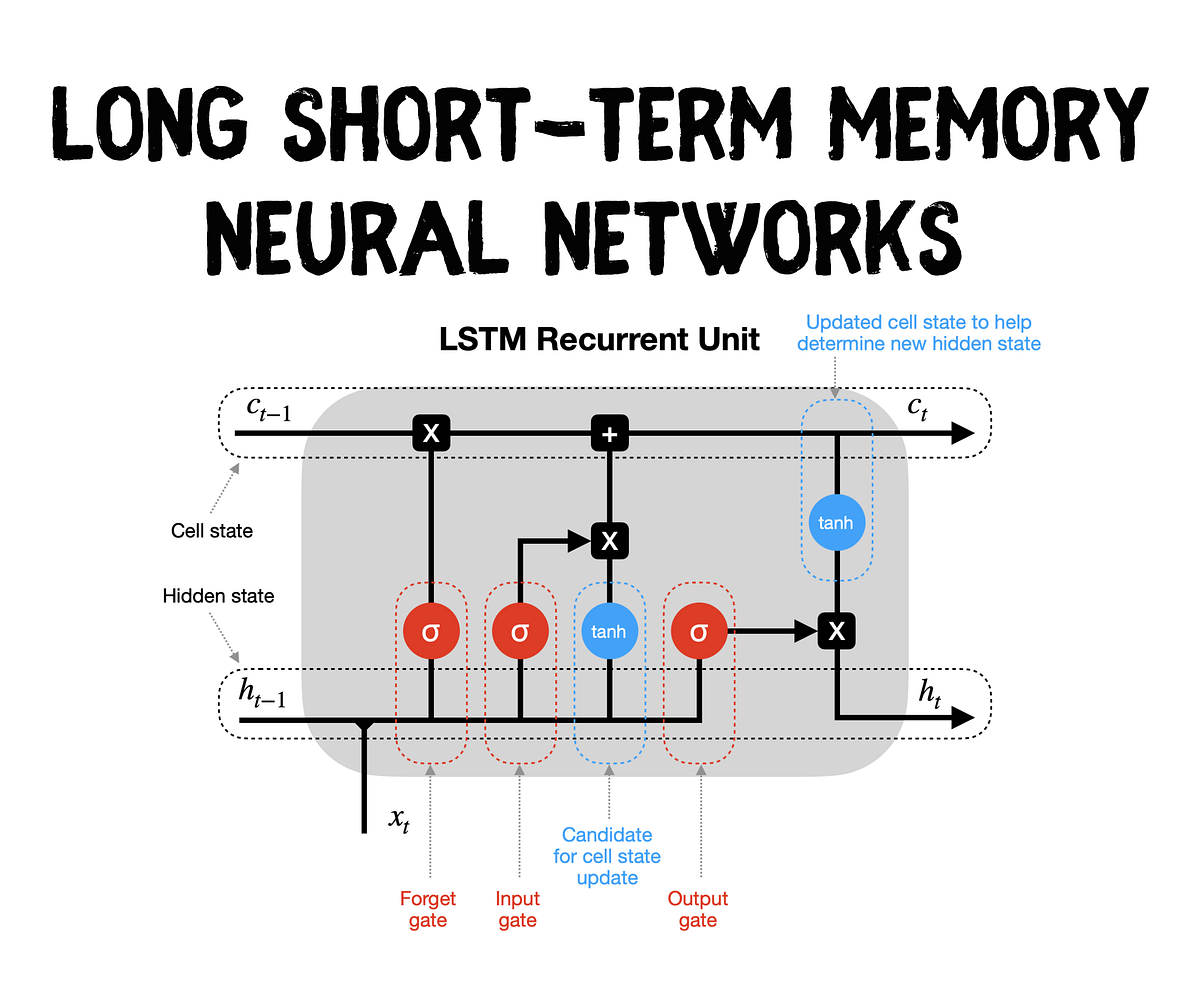
Key Components of LSTM
To understand why LSTM works so well, let's break down its key components:
- Memory Cell:
- Holds information over time.
- Allows the network to remember important details for many steps.
- Input Gate:
- Decides what new information to store in the cell.
- Regulates the flow of incoming data.
- Forget Gate:
- Decides what information to throw away from the cell.
- Helps the cell discard unimportant data.
- Output Gate:
- Decides what information to output from the cell.
- Controls the flow of information out of the cell.
Challenges with LSTM
LSTM, or Long Short-Term Memory, is a powerful tool in machine learning. However, it comes with its own set of challenges. Let's explore some common issues when training LSTM and how to overcome them.
Common Issues in Training LSTM
The common issue in training LSTM are the following:
Long Training Time
One of the main issues with LSTM is the long training time. Since LSTM processes sequences of data, it requires more computational power and time. This can be a problem if you have a large dataset.
Overfitting
Overfitting is when the model performs well on training data but poorly on new data. LSTM models are prone to overfitting because they are complex and can easily memorize the training data.
Vanishing and Exploding Gradients
Even though LSTM is designed to solve the vanishing gradient problem, it can still face this issue. Vanishing gradients make it hard for the model to learn long-term dependencies. On the other hand, exploding gradients can make the training process unstable.

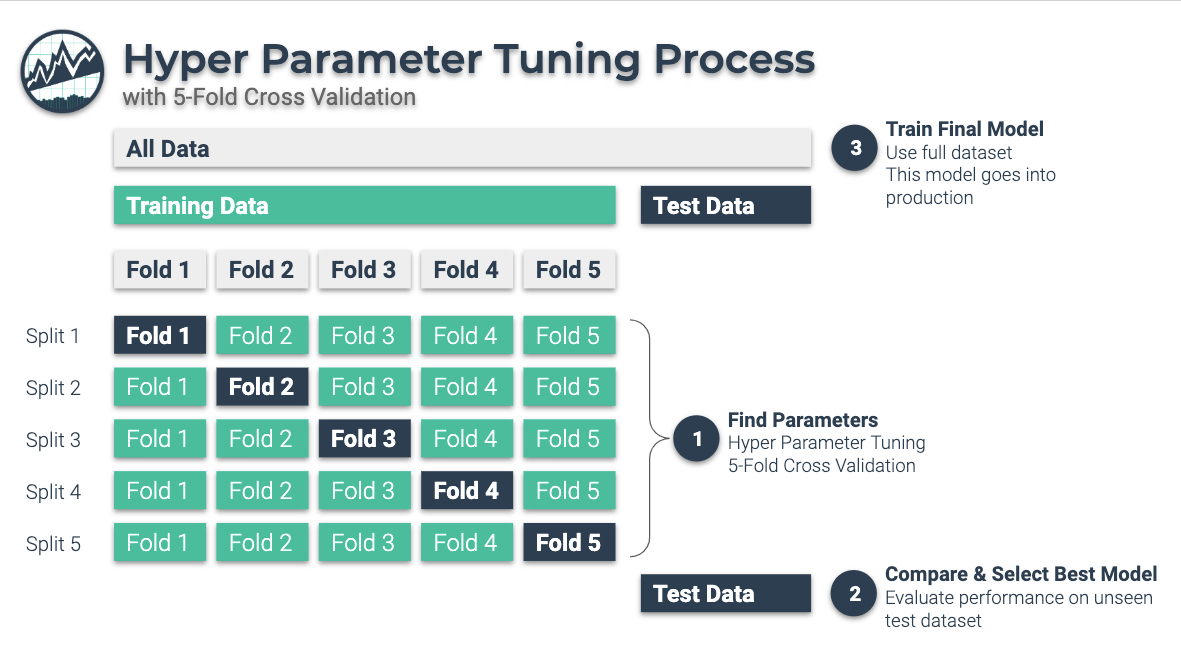
Hyperparameter Tuning
Choosing the right hyperparameters for LSTM can be tricky. Parameters like learning rate, number of layers, and hidden units need to be set carefully. If not, the model might not perform well.
Data Preprocessing
LSTM requires a lot of preprocessing. Sequences need to be of the same length, which means you have to pad or truncate them. This step can be time-consuming and affects the model's performance.
Overcoming LSTM Limitations
Now that you know about the issues, check the solutions to overcome the limitations of LSTM.
Using More Computational Resources
To tackle long training times, use more powerful hardware. GPUs and TPUs can significantly speed up the training process. You can also use cloud services that offer these resources.
Regularization Techniques
To prevent overfitting, use regularization techniques. Dropout is a popular method where random neurons are ignored during training. This helps the model generalize better and perform well on new data.
Gradient Clipping
Gradient clipping is a technique to handle exploding gradients. By limiting the gradient values, you can stabilize the training process. This helps in achieving better performance and faster convergence.

Careful Hyperparameter Tuning
Spend time tuning hyperparameters. Use techniques like grid search or random search to find the best parameters. You can also use automated tools to assist with this process.
Frequently asked questions(FAQs)
What is LSTM in machine learning?
LSTM, Long Short-Term Memory, is a type of RNN (Recurrent Neural Network) designed to remember information for long periods which is useful in sequential data tasks like language modeling and time series prediction.
How does LSTM differ from a traditional RNN?
LSTM differs from traditional RNNs by its ability to avoid the vanishing gradient problem, enabling it to learn long-term dependencies effectively through its specialized architecture of forget, input, and output gates.
What are the applications of LSTM networks?
LSTM networks are widely used in language translation, speech recognition, text generation, and time series prediction, among others, due to their proficiency in handling sequential data and remembering information for long periods.
How does the architecture of an LSTM unit work?
An LSTM unit works through a combination of gates: the forget gate decides what information to discard, the input gate decides which values to update, and the output gate controls the output based on cell state and input.
Can LSTM be used for time series prediction?
Yes, LSTM is particularly suitable for time series prediction due to its ability to remember past information for long periods, making it excellent for analyzing time-dependent data for predicting future values.
What are the challenges of training LSTM networks?
Training LSTM networks can be challenging due to issues like long training times, high computational resource requirements, and the need for large datasets to effectively learn the long-term dependencies between elements in the input sequence.