What is Concept Drift?
Concept drift happens when the patterns and data users rely on change over time. Think of it like the shifting sands of a desert. One day, the landscape looks a certain way, and the next, it's different. In the world of data and machine learning, concept drift means the data patterns that models were trained on no longer match the current reality. For instance, if an online retailer trained a model to predict shopping trends before a major event like the pandemic, those patterns would change drastically when the pandemic hits, causing concept drift.
Importance of Understanding Concept Drift
Here are the importance of understanding concept drift:

Ensures Accuracy
- Keeps models up-to-date with the latest data.
- Prevents outdated predictions and decisions.
Improves Decision-Making
- Helps in making informed and relevant decisions.
- Avoids the pitfalls of relying on old data.
Enhances Performance
- Maintains the effectiveness of machine learning models.
- Ensures consistent, high-quality performance.
Increases Reliability
- Builds trust in the predictive capabilities of models.
- Ensures models remain dependable over time.
Avoids Risks
- Minimizes the chances of errors in critical applications, such as healthcare or finance.
- Reduces the risk of costly mistakes due to outdated information.
Adapts to Change
- Allows models to evolve with changing environments.
- Keeps systems flexible and responsive to new data trends.
Supports Continuous Improvement
- Encourages regular updates and improvements to models.
- Fosters a proactive approach to model maintenance.
Types of Concept Drift
Concept drift refers to the change in the statistical properties of the target variable that a machine learning model is trying to predict. Understanding the types of concept drift is crucial for maintaining model performance in dynamic environments.
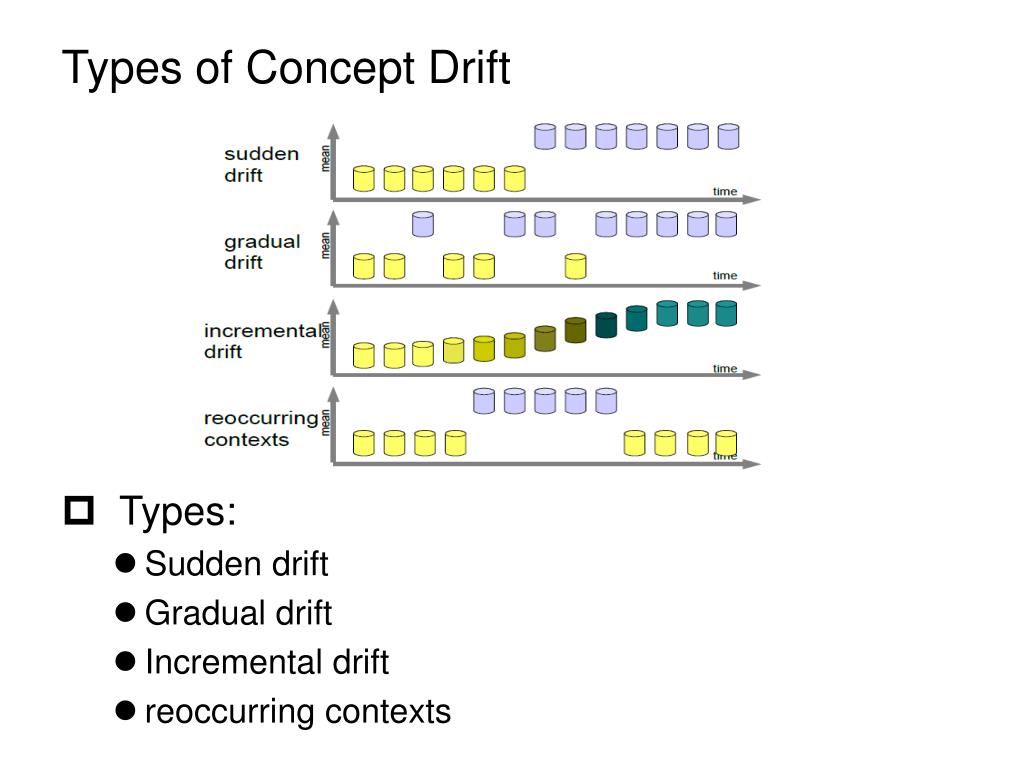
The main types of concept drift are:
- Sudden Drift: This occurs when there is an abrupt change in the data distribution. For instance, a model predicting stock prices may become ineffective overnight due to a sudden market crash. Sudden drift requires rapid detection and adaptation to prevent significant performance degradation.
- Gradual Drift: Gradual drift happens slowly over time. The changes are not immediately apparent but accumulate, eventually causing noticeable model performance issues. An example might be changing consumer preferences influencing sales predictions over several months. Regular monitoring and incremental model updates can mitigate the impact of gradual drift.
- Incremental Drift: Similar to gradual drift but occurring in a step-wise manner. Changes happen in small increments, creating a staircase pattern in data distribution. This type of drift requires continuous tracking and periodic model adjustments to stay aligned with the new data patterns.
- Recurrent Drift: In this type, the data distribution changes temporarily and then reverts to a previous state. This is common in seasonal patterns, such as retail sales fluctuating during holiday seasons. Models need to incorporate mechanisms to recognize and adapt to these recurring patterns.
- Blip or Noise: This type is characterized by temporary changes in the data that are not sustained over time. These can be due to outliers or short-term anomalies, like a sudden spike in social media activity due to a trending topic. Blips should be distinguished from actual drift to avoid unnecessary model updates.
Suggested Reading: Proof of Concept
Where Concept Drift is Observed
Concept drift can be found in many fields. Let's look at some industries where it shows up the most.
Industries Impacted by Concept Drift
The list of industries impacted by concept drift:
Finance
The effects of concept drift in Finance is:
- Stock Market Changes: Financial models need constant updates to stay relevant.
- Fraud Detection: Patterns of fraudulent behavior evolve, so models must adapt.
- Economic Shifts: Changes in the economy can make old models useless if not updated.
Healthcare
Healthcare is impacted by concept drift is:
- Disease Patterns: As diseases evolve, models predicting outbreaks must be updated.
- Medical Research: New findings can change treatment protocols and data patterns.
- Patient Behavior: Changes in how patients seek care can affect predictive models.
Suggested Reading: Healthcare Chatbot
E-commerce
The effects of concept drift in E-commerce are:
- Consumer Preferences: Shopping trends change, and models must reflect these shifts.
- Marketing Strategies: What worked last year might not work this year.
- Product Demand: Models must adjust to changes in what people buy.
Tools and Frameworks for Managing Concept Drift
Understanding concept drift is important, but knowing how to manage it is key. Let's explore some popular tools and how to integrate them into your existing machine-learning pipelines.

Popular Tools for Concept Drift Detection and Management
Here are the popular tools for concept drift detection and management are:
Scikit-multiflow
Scikit-multiflow is a popular tool for concept drift:
- Open-source: Free to use and backed by a community.
- Real-time Processing: Ideal for handling streams of data as they come in.
- Algorithms: Offers a variety of methods to detect and adapt to concept drift.
River
Rive is another tool for concept drift deletion and management:
- Lightweight: Designed to be efficient with memory and processing power.
- Incremental Learning: Updates models continuously with new data.
- Versatile: Can be used for classification, regression, and more.
Integrating Tools with Existing Machine Learning Pipelines
Here are a few integrating tools with existing machine learning pipelines:
Seamless Integration
- Compatibility: Both tools are compatible with popular libraries like scikit-learn.
- Easy Setup: Simple to add to your current workflow without major changes.
Continuous Monitoring
- Real-time Detection: Monitor for concept drift as new data arrives.
- Automated Updates: Automatically update models to reflect the latest data trends.
Improved Accuracy
- Consistent Performance: Ensures models remain accurate over time.
- Adaptability: Quickly adapts to changes, keeping predictions reliable.
Concept Drift vs Data Drift
In this section, you’ll find the differences of concept drift vs data drift.

Concept Drift
The concept drift is about:
- Definition: Changes in the statistical properties of the target variable and its relationship with input features over time.
- Impact: Affects the predictive accuracy of models as the underlying concept they are trained on evolves.
- Types: Sudden, gradual, incremental, recurrent, and blip.
- Detection: Requires monitoring of model performance and accuracy metrics.
- Response: Involves retraining or adapting models to the new concept.
Data Drift
Data drift is about:
- Definition: Changes in the input data distribution over time without necessarily altering the relationship with the target variable.
- Impact: Can lead to model input data being out of sync with training data, causing decreased performance.
- Types: Covariate shift, prior probability shift, and feature distribution shift.
- Detection: Identified by statistical tests and monitoring changes in input data characteristics.
- Response: May require feature recalibration or preprocessing adjustments and sometimes retraining the model.
Frequently Asked Questions (FAQs)
How does concept drift impact predictive models?
Concept drift impacts predictive models by degrading their performance over time as the model's assumptions about the data no longer hold true due to changes in underlying data patterns.
What are the main types of concept drift?
The main types of concept drift are sudden, incremental, gradual, and recurring, each representing different patterns of how the concept changes over time.
How can we detect concept drift in data streams?
Concept drift in data streams can be detected by monitoring performance metrics over time, using statistical process control methods, or applying specific drift detection algorithms.
What approaches are available for handling concept predictive analytics?
Key approaches for handling concept drift include regularly updating the model with new data, employing adaptive models that automatically adjust to change, and using ensemble methods for improved robustness.
Can concept drift be prevented?
While it's challenging to prevent concept drift due to its nature related to evolving data, it can be managed effectively through proactive detection and continuous model adaptation.

