Ever wondered what really happens inside an NLP model during training? We get it, the inner workings can seem complex and obscure.
However, understanding model architecture and the training process is key to building and applying NLP systems effectively.
In this post, we’ll demystify NLP model training by breaking it down step by step.
You’ll learn how data is prepared, loss is calculated, parameters are updated, and model accuracy improves over time.
Whether you’re new to NLP or want to take your skills up a notch, let’s break it down together.
What is NLP?
Natural language processing is an Artificial Intelligence branch that enables interactions between computers and human language. It's about teaching machines to understand, interpret, and generate human language meaningfully and helpfully.
NLP is a broad field with many different subfields within it. Some of the most common subfields of NLP include:
- Natural language understanding (NLU): This is the task of understanding the meaning of text or speech.
- Natural language generation (NLG): This is the task of generating grammatically correct and semantically meaningful text.
- Question answering (QA): This is the task of answering questions in natural language.
- Sentiment analysis: This is the task of determining the sentiment of text, such as whether it is positive, negative, or neutral.
- Text summarization: This is the task of generating a shorter version of a text that retains the most essential information.
What is the Importance of NLP?
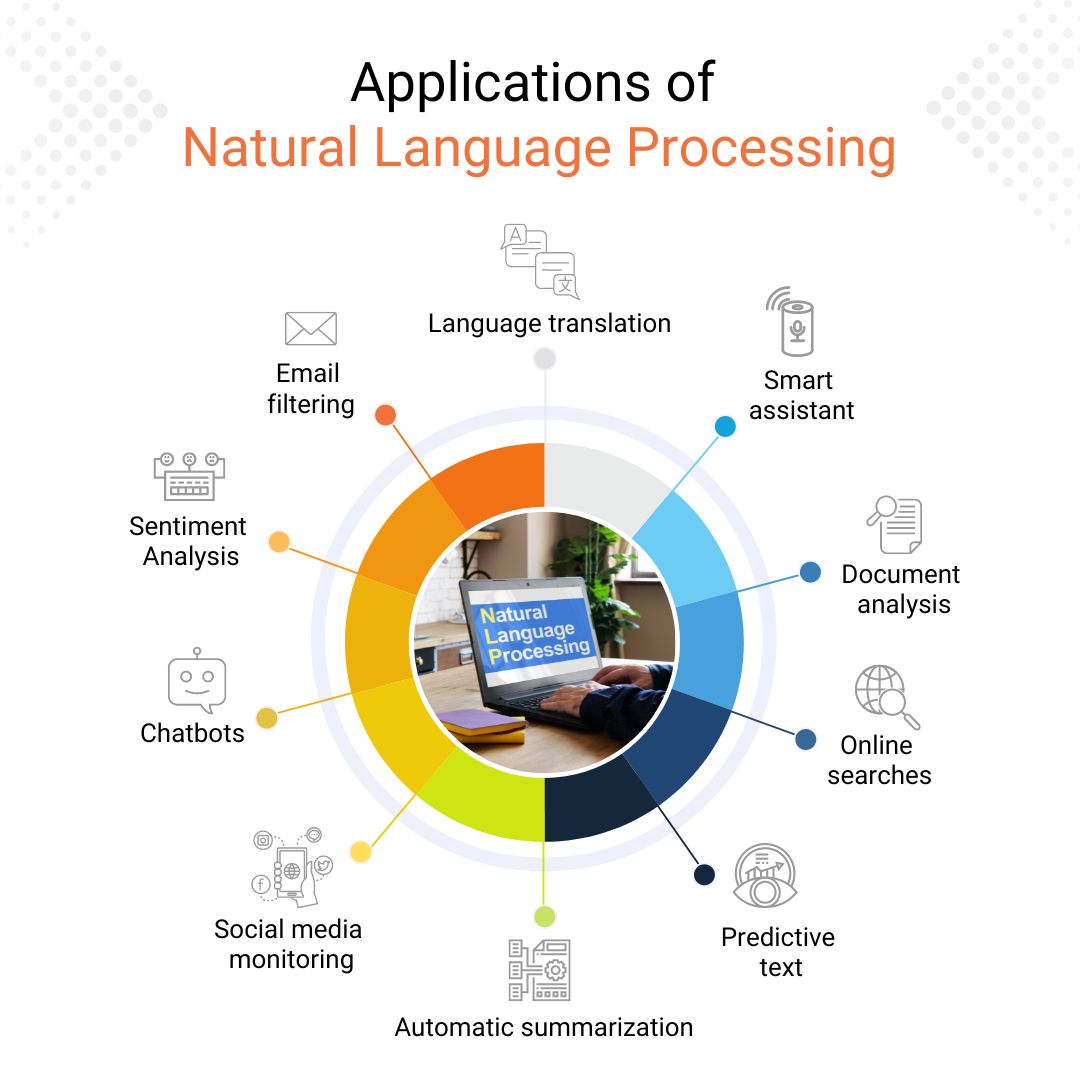
NLP is everywhere. Whether you realize it or not. NLP is behind the magic, from voice assistants like Siri and Alexa to language translation apps and chatbots.
Here's why it's so important:
Communication
NLP allows computer programs to understand and respond to human language. It enables seamless communication and interceptions between humans and machines. Think about how much easier it is to ask Siri for directions or get recommendations from a chatbot.
Information Retrieval
With abundant online information, NLP helps us find what we're looking for quickly and accurately. Search engines like Google use NLP algorithms to understand search queries and deliver relevant results.
Sentiment Analysis
NLP enables analyzing and understanding the sentiments expressed in text, such as reviews, social media posts, and customer feedback. It can help businesses gain accurate insights into customer satisfaction and make data-driven decisions.
Machine Translation
Language barriers are no longer a problem, thanks to NLP. Translation tools like Google Translate use NLP techniques to convert text from one language to another. It is easier for people worldwide to communicate and understand each other.
Personalization
NLP algorithms can analyze and understand user preferences based on their language usage. It allows companies to deliver personalized content, recommendations, and offers. It's like having your virtual assistant who knows exactly what you need.
Understanding NLP Models
NLP models derive insights from text data and aid in automating routine tasks. It is essential to understand the NLP model training process.
But before that, let's begin with brief information about NLP models.
What are NLP Models?
NLP models are software programs that employ algorithms to comprehend, transform, and generate human language.
NLP models can analyze large volumes of data. Then, it can extract meaningful insights, including emotions, sentiments, entities, and themes.
NLP models leverage machine learning techniques such as classification, clustering, and regression to identify and quantify patterns in text data. These models get trained using different types of data. It includes structured data, semi-structured data, and unstructured data.
Data Preparation for NLP Models
Data preprocessing is an essential step while building NLP models. The quality of the input data significantly impacts the accuracy of the NLP model's output. It is crucial to clean and normalize the data before feeding it to the model.
Data preparation involves several steps: tokenizing, stemming, lemmatizing, and removing stop words. Tokenization consists of breaking down the text data into smaller units called tokens, usually words or phrases.
Stemming and lemmatization help to normalize the tokens by reducing words to their base form. Stop words, such as "the" or "and," must be removed as they add no value to the analysis.
Selecting the Right NLP Model
Selecting the suitable NLP model depends on the nature and complexity of the problem. Various models can be used to complete tasks like sentiment analysis, topic modeling, named entity recognition, and language translation.
For instance, sentiment analysis models classify text as having positive, negative, or neutral emotions. On the other hand, topic modeling models identify themes in text data. Meanwhile, named entity recognition models extracts and classify named entities in text data.
NLP Model Training
NLP model training is essential in developing powerful models. It can assist in understanding and processing human language effectively. This section will explore the critical aspects of NLP model training techniques.
Gathering and Preprocessing Data
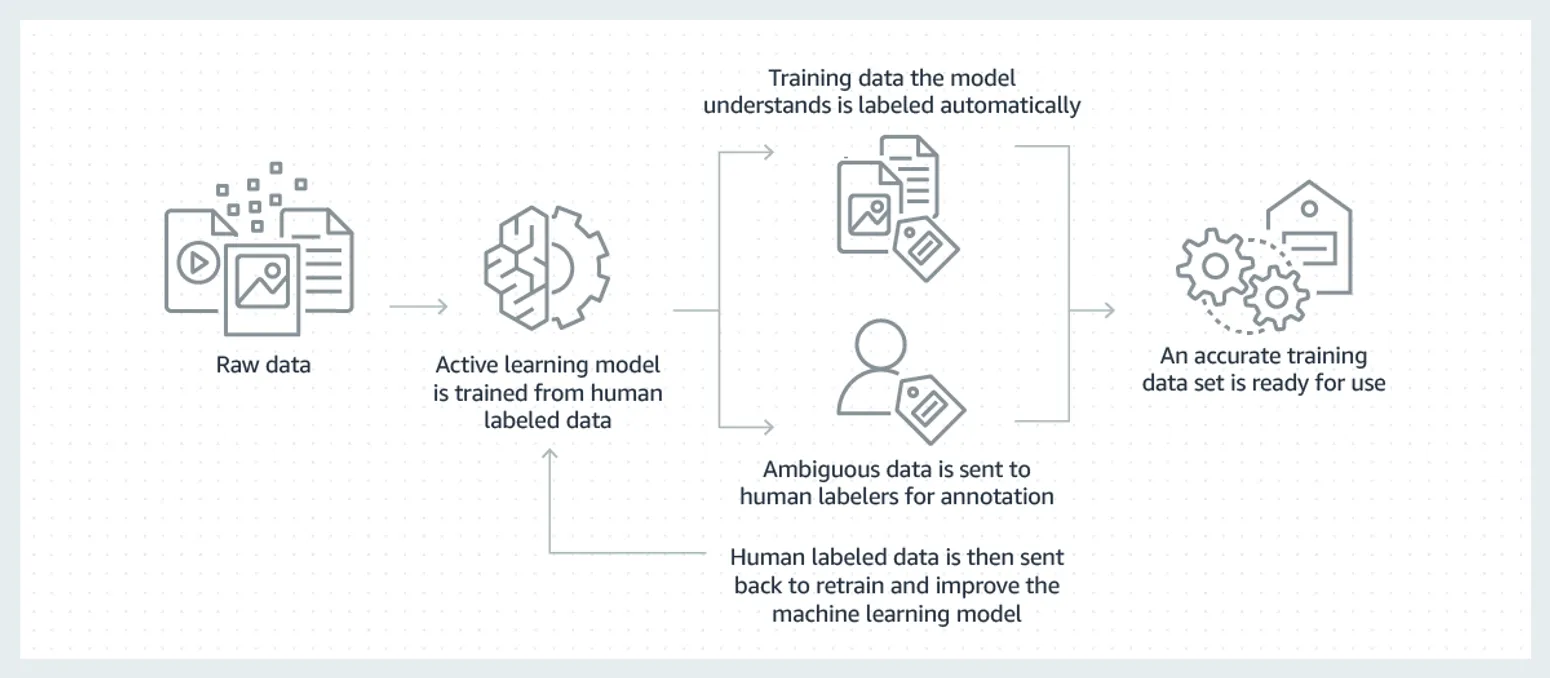
The first step in the NLP model training process is to gather and preprocess the data. Data plays a crucial role in training an effective model. It is essential to have a diverse and representative dataset for the best results.
Preprocessing the data involves several steps, such as tokenization, cleaning, and normalizing the text. Tokenization consists in breaking the text into individual words or phrases.
Cleaning the text includes removing unnecessary characters, punctuation, and special symbols. Normalizing the text involves converting the text to a standardized format, such as lowercase or removing accents.
Additionally, handling outliers, missing data, and redundant information in the dataset is crucial. It ensures that the data is in the best form for training the NLP model.
NLP Model Training Process
Once the data is gathered and preprocessed, the next NLP model training technique is to train the NLP model. The model training process involves selecting the appropriate model architecture and optimizing the model's parameters.
Different NLP models exist, including rule-based, statistical, and deep-learning models. Each model depends on the specific task and the complexity of the data.
Rule-based models rely on predefined linguistic rules. Statistical models use statistical techniques to analyze the text. And deep learning models leverage neural networks to learn patterns in the data.
During the training process, the model gets exposed to the labeled data, and the model learns to make predictions based on the input text. The NLP model training process involves iterating through the data multiple times to optimize the model's performance.
Suggested Reading:
Performance Evaluation
After training the NLP model, the next step is to evaluate its performance. Performance evaluation helps us determine how well the model performs on unseen data. Various evaluation metrics can be used, such as precision, accuracy, recall, and F1 score.
It is essential to use a separate validation dataset not used during the training process to evaluate the model's performance. It helps to assess the model's generalization capability.
Based on the evaluation results, further optimization and fine-tuning of the model can be performed.
Advanced NLP Model Training Techniques
NLP model training can be a complex task. But with the proper techniques, you can enhance the performance and efficiency of NLP models.
This section will explore some advanced techniques for NLP model training.
Transfer Learning in NLP
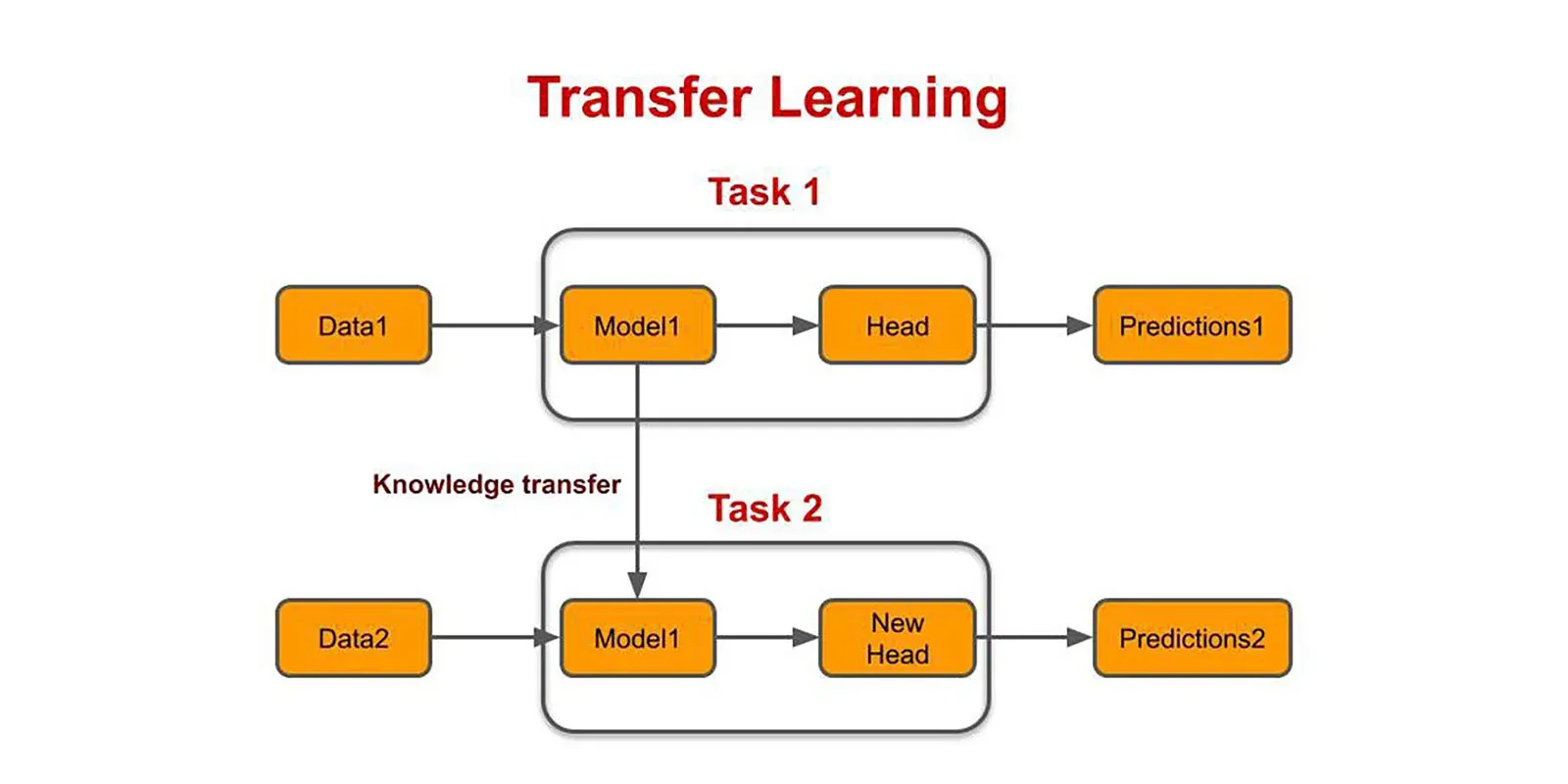
Transfer learning has gained significant popularity in the field of NLP. It allows users to leverage pre-trained models trained on massive amounts of data. These pre-trained models have learned valuable linguistic features and patterns to transfer new tasks and datasets.
By using transfer learning, you can save time and computational resources by starting with a pre-trained model and fine-tuning it on our specific task or dataset. This approach is beneficial when working with limited labeled data.
Popular pre-trained models in NLP include BERT, GPT, and ELMO. They have achieved impressive results on various NLP tasks like sentiment analysis, question answering, and named entity recognition.
Handling Large Datasets and Speeding up Training
NLP model training on large datasets can be challenging due to computational requirements and time constraints. However, techniques are available to handle large datasets and speed up the training process.
One such technique is mini-batch training, where instead of training the NLP model on the entire dataset at once, it divides the data into smaller batches. It allows users to update the model parameters more frequently, leading to faster convergence.
Another technique, Distributed training that parallelizes across multiple machines or GPUs. It helps speed up the training process by simultaneously processing different parts of the data.
Additionally, techniques like data augmentation can increase the dataset size artificially. Data augmentation involves creating new samples by applying transformations like random rotation, translation, or noise addition to the existing data.
Fine-tuning and Customization
Fine-tuning is a crucial step in NLP model training. It involves adjusting the pre-trained model's parameters to adapt it to our specific task or domain. Fine-tuning allows the NLP model to learn task-specific features. It improves the model's performance on the target task.
During the fine-tuning process, you can customize various aspects of the pre-trained model. Such as the learning rate, the number of training epochs, and the choice of optimizer.
Fine-tuning helps refine the model's performance and make it more suitable for the specific task.
Conclusion
And there you have it - we've gone under the hood to demystify how NLP models are trained. With the step-by-step process unpacked, you can now see what's happening behind the scenes during each iteration.
Understanding the data preparation, loss calculation, parameter updates and accuracy improvements that occur opens up new possibilities for tweaking and optimizing your NLP models.
Armed with this inside view, you can train more efficient models that squeeze out every bit of performance possible.
As you continue your AI journey, revisit these core concepts to gain deeper mastery of model training.
The future of NLP is bright, and now you hold the key to unlocking that potential. Ready to start training some cutting-edge models? The inner workings await your exploration!
Frequently Asked Questions (FAQs)
What is the process of training NLP models?
Training NLP models involves feeding large datasets of labeled text into machine learning algorithms. The models learn patterns and relationships within the data. It enables them to understand and intercept human language.
What are the critical components of NLP model training?
NLP model training involves data preprocessing, tokenization, feature extraction, and building neural networks. It also includes fine-tuning and transfer learning from pre-trained language models.
How does data preprocessing impact NLP model performance?
Data preprocessing is crucial in NLP model training. Tasks like text cleaning, tokenization, and normalization enhance data quality and contribute to better model accuracy and generalization.
What is transfer learning in NLP?
Transfer learning leverages pre-trained models to initial and fine-tune NLP models for specific tasks. This approach accelerates training and enables models to perform well with limited labeled data.
Which algorithms are commonly used in NLP model training?
NLP model training commonly employs algorithms like Word2Vec, GloVe, and BERT. These algorithms provide effective word embeddings and language representations for NLP tasks.