
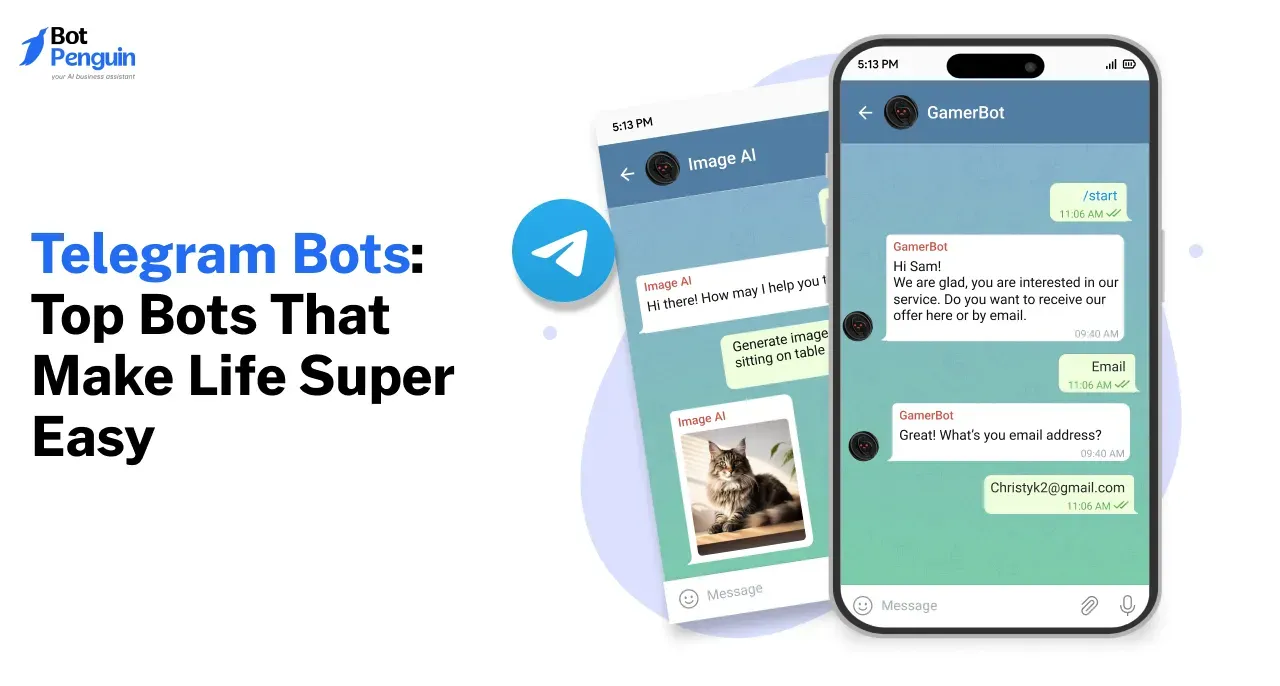
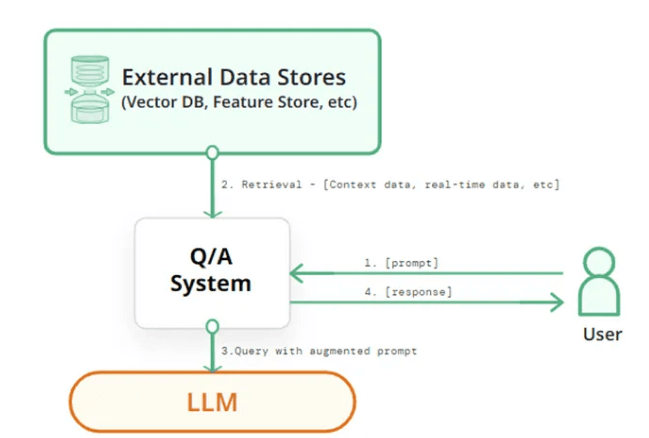
Telegram Bots: Top 8 Bots That Make Life Super Easy
Updated at Jul 16, 2026
9 min to read
LLMs are impressive, but they are stuck in the past. Once trained, they can’t learn anything new. This means they can’t provide up-to-date information, which is a big problem when data is constantly changing.
Retrieval-Augmented Generation (RAG) solves this. Rag In Llm combines the power of LLMs with the ability to retrieve current information from external sources. Instead of relying only on what they were trained on, RAG based LLMs can access real-time data to generate more accurate answers.
There are two types of Rag In Llm: Primary RAG in LLM, which integrates retrieval and generation in one process, and Secondary RAG LLM, where retrieval happens separately.
Both improve accuracy, but Primary RAG in LLM is more seamless. This approach is revolutionizing AI, allowing models to answer specialized, real-time questions more effectively.
AI models are limited by what they already know. Once trained, they can’t learn anything new. This means they can’t provide accurate or up-to-date information, especially in specialized tasks.
Retrieval-Augmented Generation (RAG) combines traditional language models with real-time information retrieval. The result? Models that can answer questions using fresh data from external sources, making them much more accurate and useful.
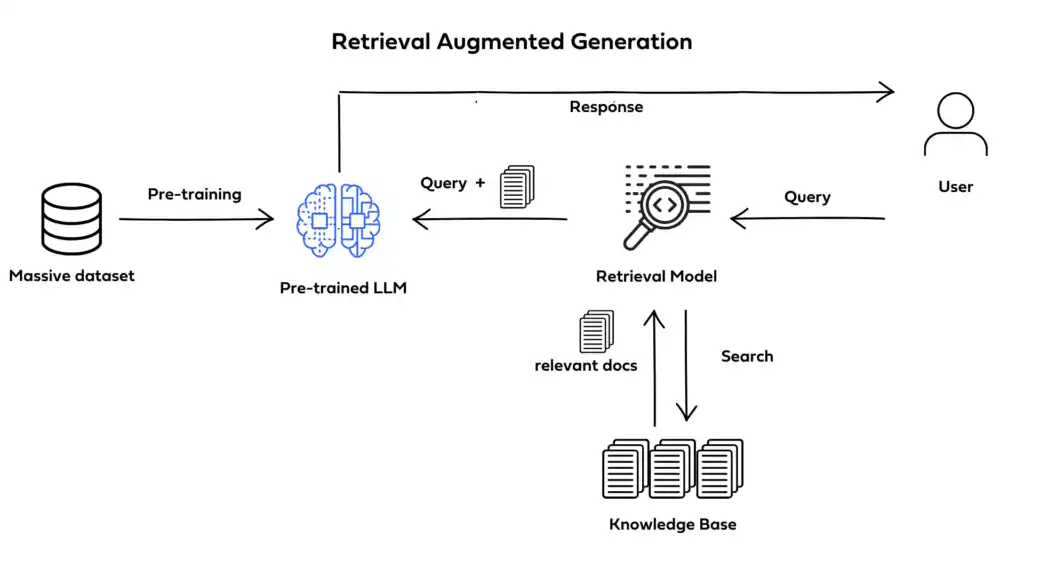
Retrieval-Augmented Generation (RAG) is a hybrid approach that enhances the performance of traditional LLMs.
While classic LLMs generate text based on their training data alone, RAG systems can pull in external information from knowledge bases or the web before generating a response.
This makes RAG based LLMs capable of answering more complex and specialized questions by referencing current, external data.
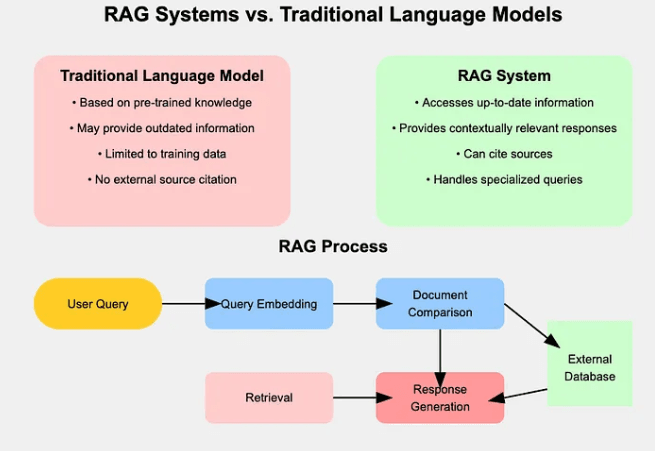
Classic Large Language Models (LLMs) only generate text from their pre-existing knowledge, which is fixed at the time of training.
This limits their ability to provide accurate answers on dynamic or specialized topics. In contrast, RAG based LLMs can access real-time information, making them more flexible and up-to-date.
For example, a classic LLM might provide outdated information, while a Primary RAG in LLM can pull the latest data from external sources, ensuring more accurate and relevant responses.
The key concept of Rag In Llm is retrieval. Instead of relying entirely on the knowledge learned during training, RAG based LLMs retrieve external information—like documents, databases, or websites.
This retrieval step augments the generative process, allowing the model to generate responses based on fresh, relevant data.
For instance, a Rag In Llm system might be asked about the latest developments in AI. Instead of providing a generic or outdated response, the system can search Wikipedia for recent updates, then use that data to generate an accurate, up-to-date answer.
This ability to integrate current information makes RAG based LLMs especially valuable in fields where knowledge evolves rapidly.
You don’t need to reinvent the wheel to make AI smarter. The key is combining the right tools.
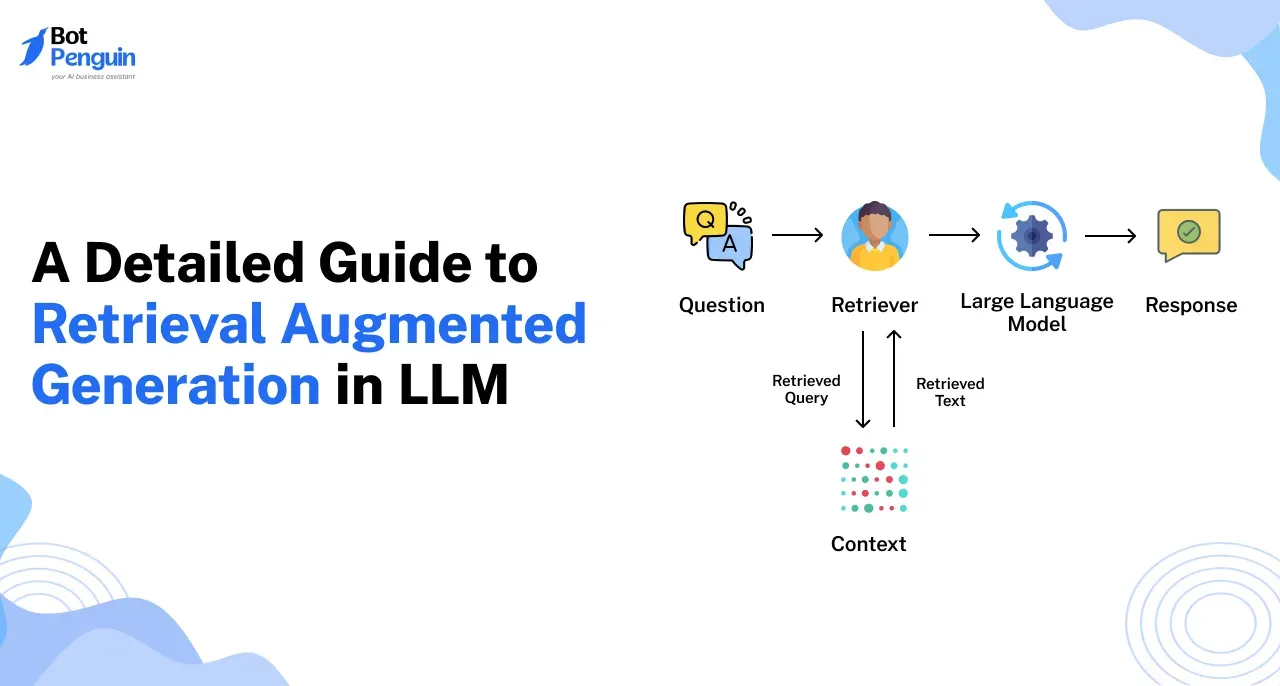
Retrieval-Augmented Generation Rag In LLM uses a mix of retrieval and generation to deliver smarter, real-time responses. Here's how it works.
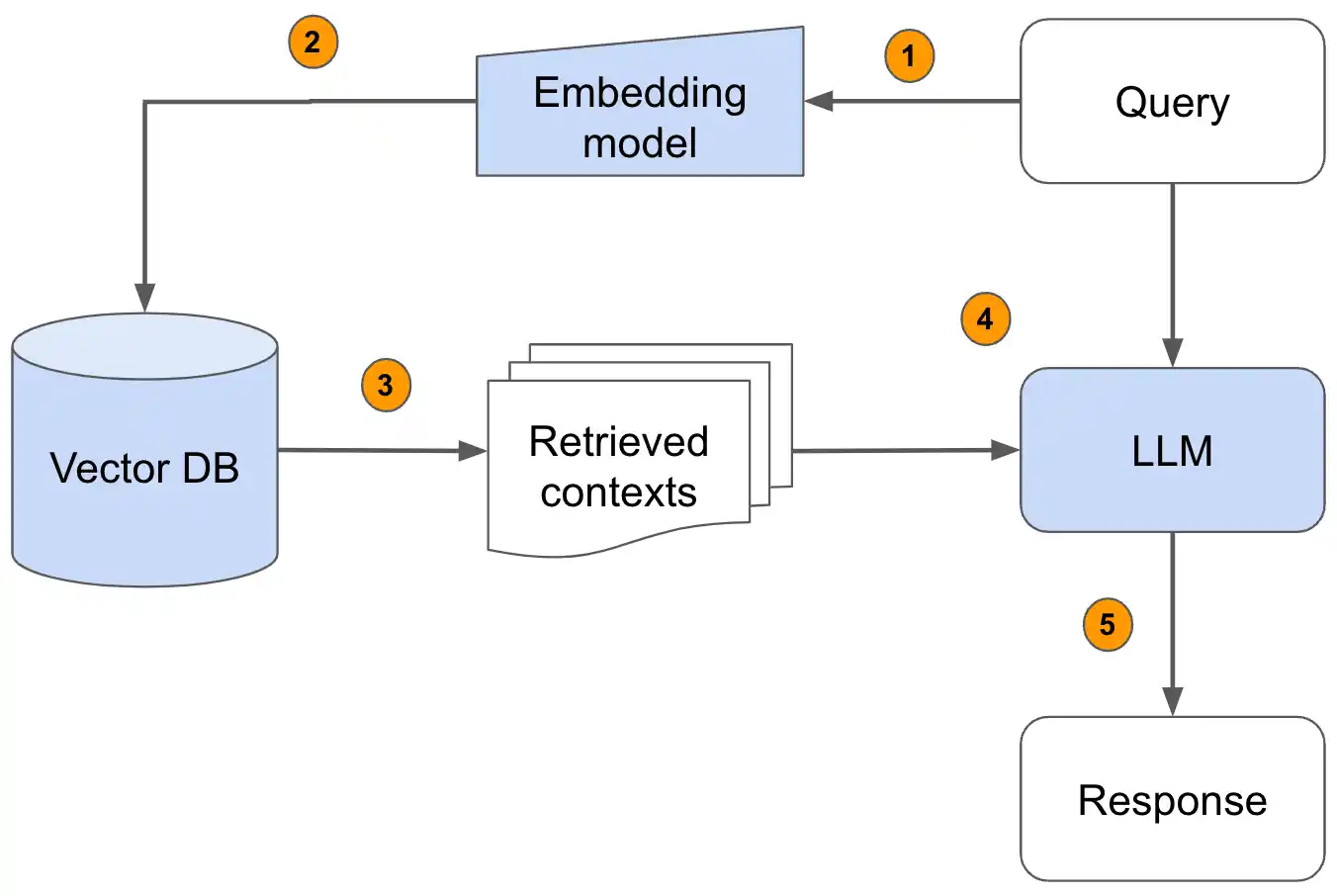
The first step in RAG based LLM systems is retrieval. This process pulls in relevant data from external sources to guide the model's response. But how do systems find the right data?
Embedding-based models like FAISS (Facebook AI Similarity Search) and Elasticsearch are used to quickly search large datasets.
These models create vector representations of text, which makes it easier to search for semantically similar information, not just exact matches.
This means the system doesn’t have to search word-for-word; it can understand the context of the request and find related information faster and more accurately.
For example, when querying a system for current stock prices or recent news, it doesn’t just look for keywords. Instead, it searches for the most relevant information that matches the intent behind the query. This makes the system more accurate and adaptable.
Once the right data is retrieved, the generative phase begins. Models like T5, GPT, and BERT are used to generate responses based on both training data and the retrieved information.
Primary RAG in LLM integrates the retrieval and generation processes into a single workflow. The model first pulls external data and immediately uses it to generate a response. This results in faster, more contextually accurate answers.
In contrast, Secondary RAG LLM separates retrieval and generation into two distinct steps. While this may be slower, it still enhances accuracy, especially for specialized tasks that require a detailed review of external data.
By combining both retrieval and generation, RAG based LLMs make use of both their internal knowledge and real-time data. For example, imagine an e-commerce site using T5 or GPT to recommend products.
It could pull real-time information about product availability from a FAISS-backed database, then generate personalized recommendations based on that data.
This combination of fast retrieval and accurate generation ensures the system stays relevant and useful, even as conditions change.
Rag In Llm works by combining two powerful technologies: retrieval and generation. Together, they help create models that can respond accurately to specialized, real-time questions—something that traditional models simply can't do.
You don’t need a massive model to get smarter AI. Retrieval-Augmented Generation (Rag In Llm) proves that smaller, efficient systems can outperform traditional models, especially when it comes to accuracy, real-time knowledge, and handling specialized tasks.
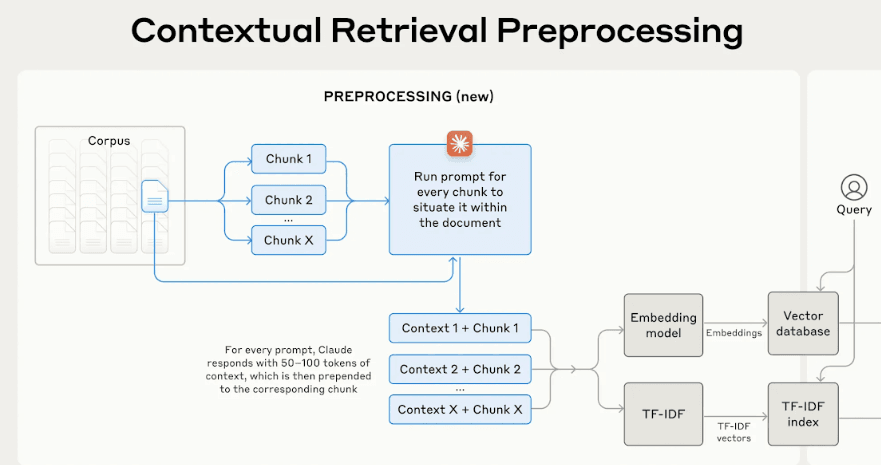
Traditional LLMs are trained on a fixed set of data. This means they often miss the mark when answering specific or complex queries.
RAG based LLMs, however, can retrieve the most relevant, real-time information, which ensures responses are more accurate and contextually relevant.
By pulling from external databases and live sources, Primary RAG in LLM systems produce answers that better reflect the nuances of a question.
Unlike static models, Rag In Llm has the ability to access live data. Whether it's the latest news, research papers, or changing data, Secondary RAG LLM systems can pull in real-time information.
This is particularly valuable in industries like medicine or technology, where fresh data is crucial for accurate answers. Traditional models can’t adapt as quickly, but Rag In Llm brings the latest insights into the conversation.
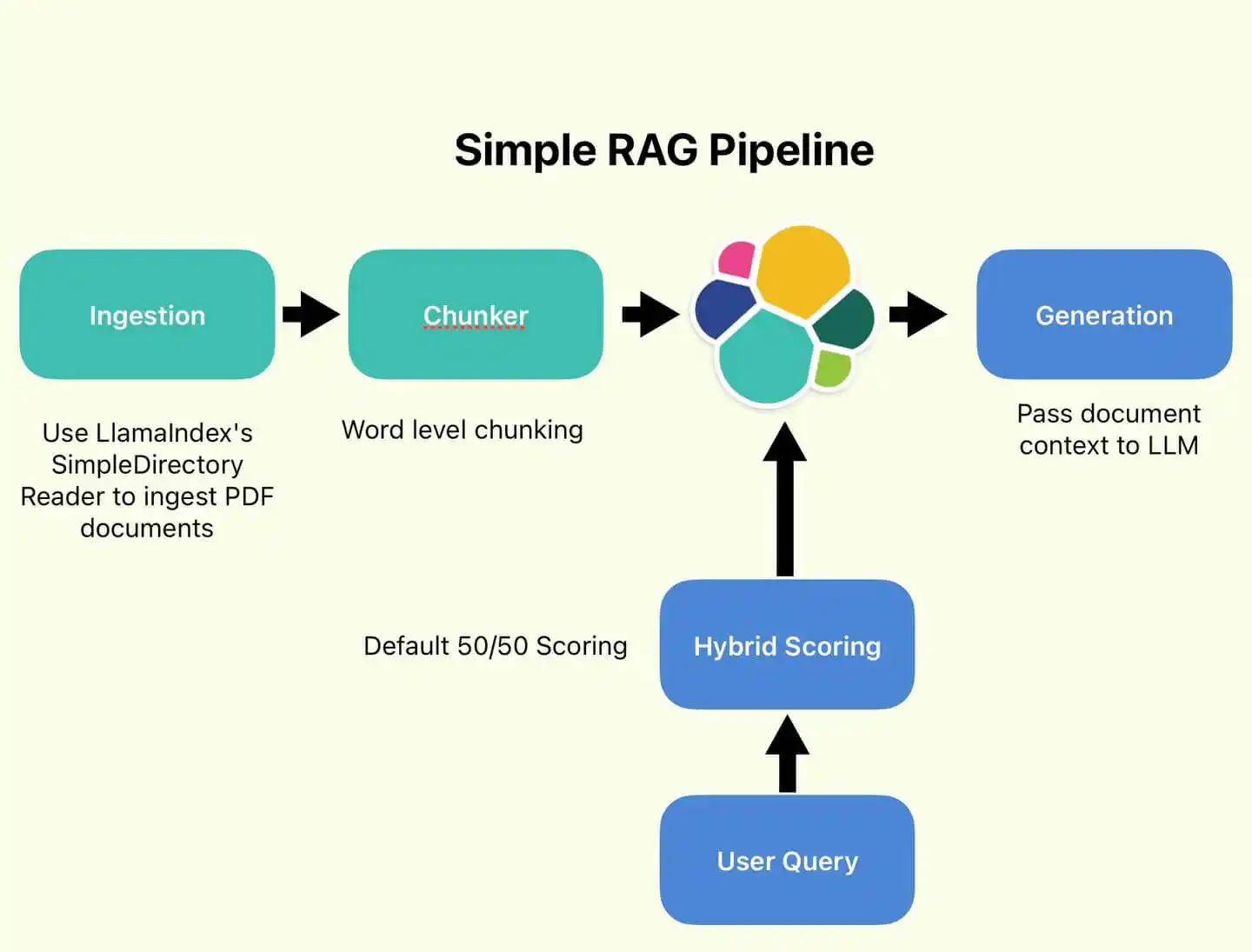
Rag in Llm excels in answering specialized, niche queries. Traditional models are limited by their training datasets, which may not cover every possible subject in detail.
With RAG based LLMs, you can access information beyond the model's initial training, including specific research papers, industry reports, or expert databases.
This makes Rag In Llm perfect for complex questions in fields like law, healthcare, or science.
Rag In Llm reduces the need for massive pre-trained models, which can be resource-intensive and slow. By retrieving relevant information on demand, RAG based LLMs operate more efficiently, with smaller model sizes.
This not only saves on storage but also reduces computational costs. Without needing to store all the knowledge internally, the system can focus on retrieving what’s necessary in real-time.
For example, a RAG based LLM answering a question about recent medical research might pull in the latest studies from medical journals.
By accessing real-time information and combining it with its internal knowledge, it delivers a more informed, accurate response than a traditional static model could.
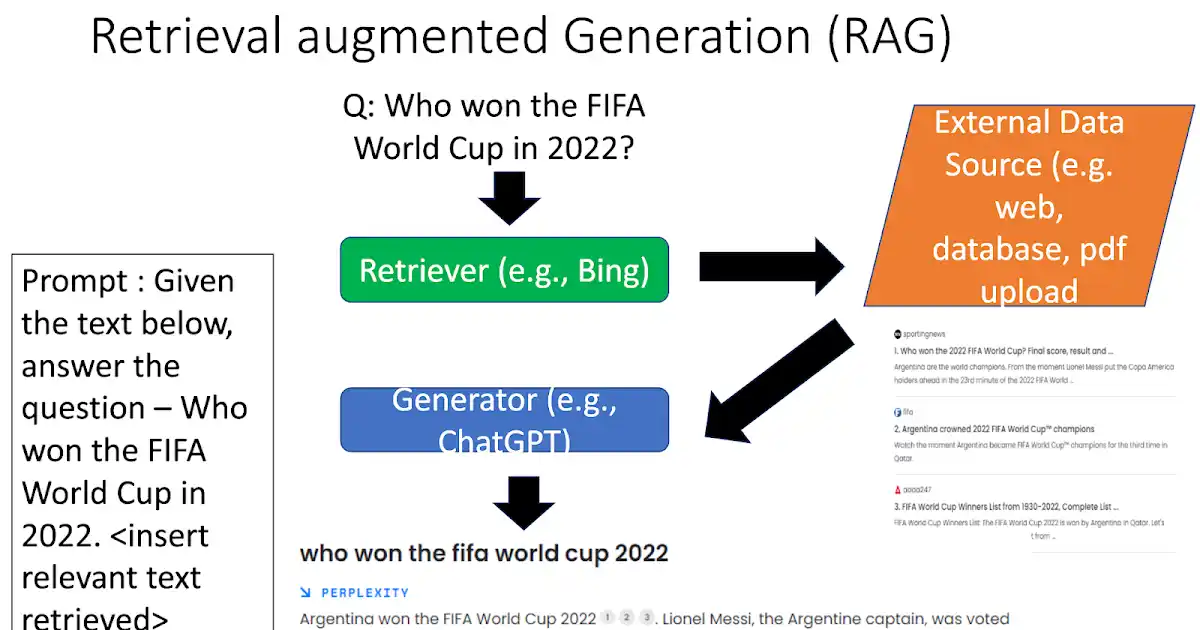
What if AI could pull the latest data while answering questions, making responses more accurate and relevant? Retrieval-Augmented Generation (RAG) does just that.
By combining real-time data retrieval with text generation, Rag In Llm is pushing AI capabilities further. Here’s how RAG based LLMs are transforming different tasks.
Rag In Llm improves question-answering by accessing relevant, real-time data. Traditional models that rely solely on pre-existing training data, Secondary RAG LLMs pull in current information from external sources like product manuals, FAQs, or user reviews.
A customer support chatbot using Rag In Llm can retrieve real-time information from a company’s database and generate tailored responses. This means the answers are more accurate and specific to each query.
Summarizing long documents can be a challenge. RAG based LLMs excel here by pulling key excerpts from large volumes of text and generating concise summaries.
Instead of reading entire reports or articles, users get quick, relevant summaries that capture the most important details. This is especially useful for research, legal, or corporate environments where information overload is common.
In academic settings, Rag In Llm helps with research by automatically fetching and synthesizing relevant papers, articles, and data.
For example, Primary RAG in LLM can pull up the latest studies in a particular field and combine them to create an up-to-date, well-rounded answer.
This saves researchers significant time while ensuring that they have access to the most current information.
For developers, Rag In Llm is a game-changer. When faced with a coding problem, a RAG based LLM can retrieve relevant code snippets, documentation, or solutions from sources like Stack Overflow and GitHub.
It then generates code based on this data, allowing developers to quickly solve issues without starting from scratch. This is incredibly useful for debugging, learning new programming languages, or generating code for specific tasks.
By combining retrieval with generation, Rag In Llm ensures that AI answers are more relevant, up-to-date, and precise. Whether it's for customer support, research, or development, RAG brings a new level of intelligence to AI systems.
At first, it sounds like a dream—AI pulling the most relevant data and generating perfect answers. But Rag In Llm isn't as flawless as it seems. There are real hurdles when trying to make it work.
The first problem is ensuring that the data retrieved is relevant and accurate. Primary RAG in LLM systems need to pull in information from large databases or external sources.
This increases the risk of pulling outdated, irrelevant, or even incorrect data. To ensure good output, the retrieval system needs to be precise. If the data is off, the final answer will be too.
Another challenge is speed. Secondary RAG LLMs tend to be slower than traditional models. This happens because they first need to fetch data before generating an answer.
For real-time applications like chatbots or customer support, this extra delay can be a problem, especially when pulling information from huge knowledge bases.
Integrating the retrieval process with the generation model is another pain point. The system has to smoothly connect the two phases—retrieving data and then generating the response.
If they don’t work well together, the whole system might break down or produce inaccurate results. This setup can be technically demanding, slowing down deployment.
Dealing with vague or unclear queries is tough for RAG based LLMs. When a query is too broad, like "Tell me about health," the system struggles to retrieve the right data.
Ambiguity in user queries leads to pulling irrelevant data, which results in weak answers. This makes RAG much more challenging in real-world applications where precision is crucial.
Despite these challenges, Rag In Llm remains a powerful tool when implemented carefully, balancing retrieval and generation to deliver the most accurate results.
Building a RAG based LLM system is not as complicated as it sounds. The tools are available, and with the right steps, you can set up a system that pulls relevant data and generates accurate answers.
There are a few frameworks that make the process easier. Haystack is a popular one. It combines retrieval systems with generative models, making it a great option for building a Primary RAG in LLM system.
Another useful tool is DeepPavlov, which specializes in conversational AI, leveraging Secondary RAG LLM techniques.
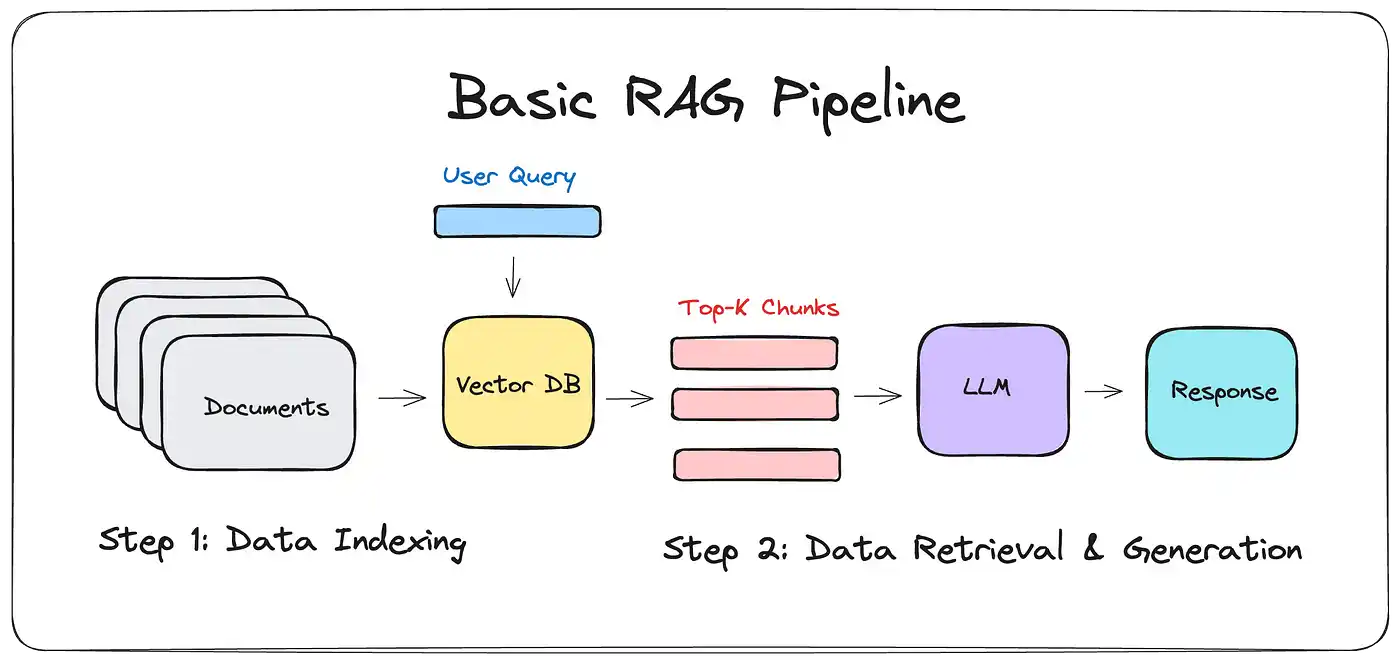
Imagine a system that pulls articles on “climate change” and uses GPT to summarize recent findings. By combining accurate, real-time data with the power of a language model, the system provides a clear, context-aware response.
This setup ensures a smoother interaction between retrieval and generation, unlocking the potential of RAG based LLMs for complex tasks.
The future of RAG based LLMs is moving faster than you think. We’re on the brink of a leap that will change how we use AI forever.
The future of RAG is multi-faceted and exciting. Expect quicker, smarter, and more interactive systems soon.
RAG is changing everything. It combines retrieval and generation, fixing the weaknesses of traditional models.
Unlike older LLMs, RAG based LLMs pull in real-time data to create more accurate and relevant answers. This ability gives it an edge in dynamic fields like customer service and research.
Industries are already tapping into its potential. From improving customer support with real-time answers to speeding up research by pulling the latest data, the opportunities are huge.
This technology is still evolving, but its promise is clear. The future of Primary RAG in LLM systems could transform the way we interact with AI in our daily lives. Now is the time to explore this breakthrough.
RAG combines retrieval of real-time data with generative models, allowing AI to access up-to-date, external knowledge. This overcomes the static nature of traditional models.
RAG enhances AI by pulling in real-time, external data. Unlike traditional LLMs, which rely solely on training data, RAG provides answers based on both prior knowledge and current context.
Yes, RAG-based systems excel at answering specific or complex queries by retrieving relevant external information. This helps in providing more accurate, context-specific answers.
Vector search enables RAG systems to retrieve semantically relevant information quickly. It represents data as vectors, improving the accuracy and speed of finding relevant content.
Yes, RAG can power autonomous systems that pull in live data, like news feeds or social media, to make informed decisions in real time. BotPenguin can help integrate such systems effectively.
Subscribe to Our Newsletter
Get the latest business insights straight into your inbox.
Checkout our related blogs you will love.
Updated at Jul 16, 2026
9 min to read
Updated at Jul 14, 2026
8 min to read

Updated at Jul 13, 2026
10 min to read

Updated at Jul 13, 2026
10 min to read
Updated at Jul 11, 2026
10 min to read
Updated at Jul 10, 2026
11 min to read
Table of Contents