The staggering spread of ChatGPT since launching in November 2022, reaching over 100 million users in under two months, underscores surging mainstream intrigue in conversational AI (Larson, 2023). However, broad information-based exchanges have limitations in meeting specialized business needs. This is where customizing your own tailored version of ChatGPT comes in.
Leveraging equally accessible self-supervised learning foundations, custom models excel at solving niche, complex issues when strategically trained on relevant data. Recent projections estimate up to 80% of queries enterprises receive relate to specialized knowledge only accessible internally across vast document reservoirs (Holmes, 2023). Constructing a custom ChatGPT clone as an intelligent searchable interface to proprietary assets delivers immense utility.
Studies also reveal that 72% of IT leaders are interested in developing custom AI assistants, viewing such projects as strategic for strengthening customer experiences and insights (Blue Prism, 2022). Pre-built model frameworks like
By ingesting company product documentation, recorded support calls, industry reports, and other robust domain content, cloned chatbots easily outpace out-of-the-box inconsistencies plaguing generic offerings. The margin for rapid, affordable innovation abounds.
Let's learn about the custom ChatGPT clone in detail!
Training Data for Custom ChatGPT Clone
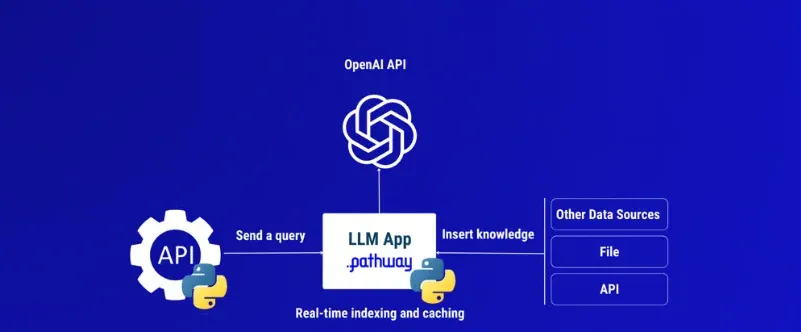
By understanding the significance of high-quality training data, selecting suitable conversational datasets, and applying appropriate data preprocessing techniques, you can effectively train your custom ChatGPT clone and enhance its conversational abilities.
Significance of High-Quality Training Data
High-quality training data is crucial for building a successful custom ChatGPT clone. It directly influences the chatbot's conversational ability, accuracy, and overall performance. Here's why high-quality training data is significant:
Language Fluency: High-quality training data helps the chatbot understand and generate language more fluently. It provides the model with diverse sentence structures, grammar rules, and vocabulary, enabling it to generate coherent and natural responses.
Contextual Understanding: Training data that includes diverse conversational contexts allows the chatbot to understand user inputs more accurately. It helps the model capture nuances, implicit meaning, and context dependencies in the conversation, leading to more relevant responses.
Domain Expertise: Incorporating domain-specific training data enhances the chatbot's ability to answer domain-specific queries accurately. Depending on the use case, including relevant datasets related to specific industries, products, or services can significantly improve the chatbot's performance in that domain.
Types of Conversational Datasets Suitable for Training a Chatbot
There are various types of conversational datasets suitable for training a chatbot. Some common examples include:
Chit-Chat Datasets: These datasets consist of casual, open-ended conversations covering a wide range of topics. They help the chatbot generate engaging responses and handle small talk effectively.
FAQ Datasets: FAQ datasets contain frequently asked questions and their corresponding answers. They allow the chatbot to quickly and accurately respond to commonly asked queries.
Customer Support Datasets: These datasets include conversations between customer support agents and customers. They help the chatbot handle customer inquiries, troubleshoot common issues, and provide support.
Dialogue System Datasets: These datasets focus on specific dialogue tasks, such as booking a restaurant reservation or ordering a product. They enable the chatbot to handle task-oriented conversations effectively.
Data Preprocessing Techniques and Considerations
Before using the conversational datasets for training, it's essential to preprocess the data. Some important preprocessing techniques and considerations include:
Cleaning: Remove irrelevant or noisy data, such as duplicate conversations, incomplete sentences, or conversations with excessive typos or grammatical errors.
Tokenization: Split the conversations into individual tokens, such as words or subwords, to facilitate model training.
Context Window Selection: Determine the appropriate context window size (previous conversation history) to provide sufficient context for generating relevant responses.
Data Augmentation: Augment the training data by adding variations or paraphrases to the existing conversations. This helps to make the model more robust and improves its ability to handle diverse user inputs.
Balancing: Ensure the training data reflects a balanced distribution of topics, conversation lengths, and user intents to avoid biases and improve the chatbot's generalization capability.
Selecting a Pre-Trained GPT Model
By carefully considering the factors relevant to your chatbot's requirements and leveraging resources like OpenAI's API, Hugging Face Transformers, and cloud service providers, you can select the most appropriate pre-trained GPT model and efficiently integrate it into your ChatGPT clone.
Overview of Popular Pre-trained GPT Models Like GPT-3 and GPT-2
Pre-trained GPT (Generative Pre-trained Transformer) models offer an effective way to build chatbots like ChatGPT clones. These models can generate human-like text by predicting the next word in a sequence of input text based on the patterns learned during pre-training. Some popular pre-trained GPT models include GPT-3 and GPT-2. GPT-3, developed by OpenAI, is one of the most advanced pre-trained models with 175 billion parameters, making it incredibly powerful in generating human-like text across a wide range of domains and tasks.
Factors to Consider When Choosing a Model for Your Custom ChatGPT Clone
When choosing a pre-trained GPT model for your ChatGPT clone, there are several factors to consider. Firstly, you need to consider the task complexity and scale you want your chatbot to handle. If you want your chatbot to handle complex and diverse conversational tasks, GPT-3 with its larger model and extensive training could be the better choice. Secondly, you need to assess your budget and technical infrastructure to ensure you can accommodate the requirements of the chosen model, both in terms of time and cost.
Resources for Accessing and Utilizing Pre-trained Models
There are several resources for accessing and using pre-trained GPT models, including OpenAI API, Hugging Face Transformers, and cloud service providers. OpenAI offers an API that allows developers to access and utilize GPT models.
Hugging Face provides an extensive library of pre-trained models, including GPT-2 and GPT-3, with easy-to-use interfaces for text generation. Moreover, cloud platforms like AWS, Azure, and Google Cloud provide infrastructure and services that can be leveraged to host and deploy pre-trained models, making the deployment process more manageable.
Now training your chatbot for personalized responses isn't that tough. Meet BotPenguin- the home of chatbot solutions.
With the help of native ChatGPT integration, you can easily train your chatbot on your own database by simply uploading a CSV file or letting ChatGPT crawl your website. As a result, your chatbot will provide relevant answers to customer queries in a more conversational and human-like tone.
And the tech for BotPenguin just doesn't stop there! With all the heavy work of chatbot development already done for you, BotPenguin makes sure that you reach your customers where they are by offering ChatGPT-integrated chatbots for multiple platforms, thus making omnichannel support look easy:
- WhatsApp Chatbot
- Facebook Chatbot
- WordPress Chatbot
- Telegram Chatbot
- Website Chatbot
- Squarespace Chatbot
- woocommerce Chatbot
- Instagram Chatbot
Fine-Tuning the GPT Model
Fine-tuning is a process of customizing a pre-trained GPT (Generative Pre-trained Transformer) model to better suit a specific use case, such as developing a chatbot. The pre-trained model has already been trained on a large corpus of text data and has learned general language patterns. However, fine-tuning allows us to adapt the model to specific tasks or domains, thereby customizing the chatbot's behavior.
The steps involved in fine-tuning a GPT model are as follows:
Dataset Preparation: Curate or create a dataset that aligns with the intended behavior of the chatbot. It should consist of input-output pairs or prompts-responses relevant to the desired use case.
Tokenization: Convert the text data into numerical tokens that the GPT model can process. This involves breaking the text into smaller units, such as words or subwords, and encoding them into a numerical format.
Model Configuration: Set up the GPT model for the fine-tuning process. This includes selecting appropriate hyperparameters, such as the learning rate, batch size, and the number of training steps, which can significantly affect the model's performance.
Fine-tuning Setup: Initialize the pre-trained GPT model with its pre-trained weights and adjust it to have the same token vocabulary as the fine-tuning dataset. By freezing the initial layers, the model retains the knowledge learned during pre-training and avoids overwriting them.
Training: Train the fine-tuning model using the prepared dataset. The model learns to generate responses by predicting the most likely next word given the input. The training process typically involves minimizing a loss function, such as cross-entropy, to optimize the model's performance.
Customizing the ChatGPT Clone
Customizing the ChatGPT Clone involves defining the objective and personality of the chatbot, incorporating prompts, instructions, and examples for desired responses, and iteratively training and refining the model based on user feedback. These steps help create a chatbot that delivers more accurate and contextually appropriate responses, improving the overall user experience.
Defining the Objective and Personality of Your Chatbot
Customizing the ChatGPT Clone involves defining the objective and personality of the chatbot to create a more tailored user experience. The objective determines the chatbot's purpose and the type of interactions it will engage in.
For example, an objective could be to provide customer support or offer recommendations. The chatbot's personality refers to the tone, style, and characteristics it exhibits during conversations. It can be friendly, formal, or even reflect a specific persona.
Techniques for Incorporating Prompts, Instructions, and Examples to Influence Responses
Prompts, instructions, and examples are important tools to influence the responses of the ChatGPT Clone. Prompts are specific starting phrases or statements the chatbot gives to guide its response.
They can provide context and ensure the chatbot stays on topic. Instructions can be included within the prompt to explicitly guide the chatbot's behavior or provide specific requirements for the response. Examples, both positive and negative, can be provided to demonstrate the desired and undesired responses.
Iterative Training and Refining the Model Based on User Feedback
An iterative training process is crucial for refining the model. User feedback plays a key role in identifying areas for improvement and addressing limitations. Feedback can be collected through user testing, surveys, or other communication channels.
Based on this feedback, the model can be fine-tuned further by retraining it with additional data or adjusting the prompts, instructions, or examples. This iterative approach allows the chatbot to continuously improve its responses and better align with user expectations.
Conclusion
In conclusion, the potential for applications of ChatGPT clones and at-scale GPT models is just getting started, with more democratized access enabling growing use cases.
As companies look to leverage these technologies to their advantage, the key will be proper training of underlying models with substantial data tailored to your problem scope, reinforced by continuous fine-tuning based on user feedback for enhanced personalization and accuracy.
Trusted partners like BotPenguin, with deep expertise in AI-based natural language models, can facilitate your journey into scalable bot assistants with services spanning the development of customized GPT clones aligned to your domain or intent, flexible access options including out-of-the-box models or fully managed solutions per business needs, model retraining capabilities using your proprietary data, delivery with tight security controls and integrations with existing tech stacks.
With the right GPT architecture and ongoing model improvement centered around your unique requirements, you can deploy 24/7 smart assistants that drive self-service, automation, and process enhancement while staying at the frontier of AI-led innovation.
Get in touch with BotPenguin today to explore the deployment of at-scale ChatGPT-like capabilities augmenting human capabilities in your organization!
Frequently Asked Questions (FAQs)
What is the process of training a ChatGPT Clone?
Training a ChatGPT Clone involves several steps, including dataset preparation, tokenization, model configuration, fine-tuning setup, training, hyperparameter optimization, evaluation, and iteration. It is a comprehensive process that aims to adapt the pre-trained model to better suit a specific use case.
How can I define the objective and personality of my ChatGPT Clone?
To define the objective and personality of your ChatGPT Clone, you need to determine the purpose and desired style of interactions. This can be achieved by specifying the chatbot's goals, such as providing customer support or offering recommendations, and selecting the desired tone, style, and characteristics it exhibits during conversations.
What role do prompts, instructions, and examples play in influencing the responses of my ChatGPT Clone?
Prompts are specific starting phrases or statements that guide the chatbot's response, while instructions provide explicit guidance or requirements for the desired response. Examples, both positive and negative, demonstrate the expected and undesired responses. By incorporating prompts, instructions, and examples, you can shape the behavior and improve the relevance of your ChatGPT Clone's responses.
How can I refine my ChatGPT Clone based on user feedback?
User feedback is essential for refining your ChatGPT Clone. This feedback can be collected through user testing, surveys, or other communication channels. By analyzing user feedback, you can identify areas for improvement and make necessary adjustments, such as fine-tuning the model, updating prompts or instructions, or addressing specific limitations raised by users.