What Is Speech Processing?
Speech processing is the branch of computer science that deals with analyzing, interpreting, and generating spoken language. It covers three main areas: recognizing speech (audio to text), synthesizing speech (text to audio), and analyzing speech signals. This is the full pipeline behind voice assistants, transcription, and AI voice agents.
What Is Speech Processing?
Every time a smart speaker answers a question, a phone transcribes a voice note, or an AI agent talks to a customer on a call, speech processing is doing the work.
It is the umbrella field that covers everything machines do with the human voice: listening, understanding, speaking, and analyzing.
That breadth can make the term feel abstract. It is not a single tool. It is a whole pipeline. This guide breaks it down clearly.
Speech Processing: A Clear Definition
Speech processing is the field of computer science and engineering that analyzes, interprets, and generates spoken language.
It spans three broad activities: converting speech to text (recognition), converting text to speech (synthesis), and analyzing the speech signal itself for qualities like speaker identity or emotion.
Reference Definition (Neutral)
Speech processing is a discipline within computer science and electrical engineering concerned with computational analysis and generation of spoken language. It is vendor-neutral and language-neutral. The term describes a field, not any single product.
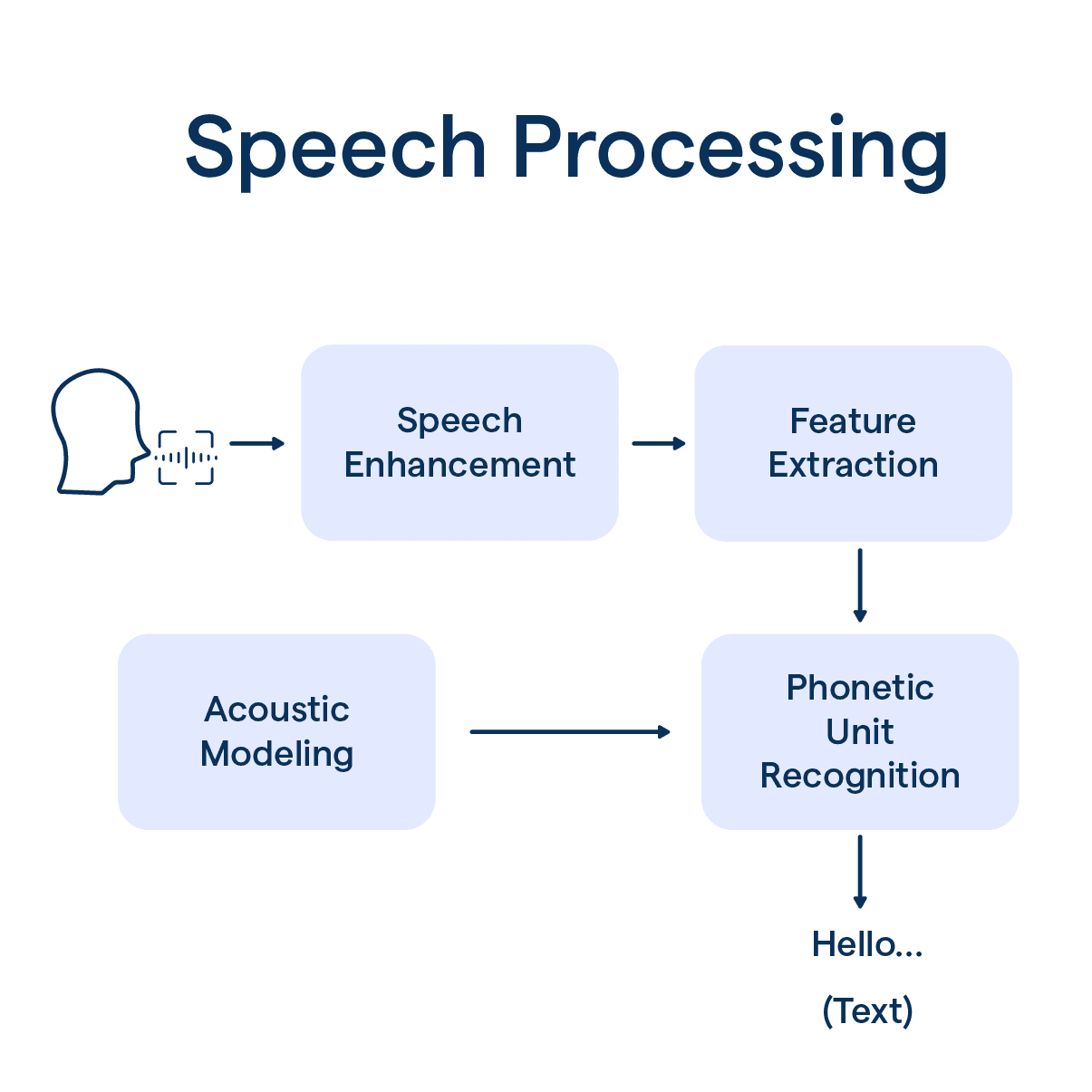
How Does Speech Processing Work?
Speech processing follows a pipeline. Each stage passes structured data to the next, which is why the quality of the whole chain matters, not just one step.
Stage 1 (Capture): A microphone records an audio signal and produces a raw waveform.
Stage 2 (Clean): Noise is filtered and the signal is normalized into clean audio frames.
Stage 3 (Feature Extraction): The signal is broken into measurable patterns such as acoustic features.
Stage 4 (Recognition / ASR): Features are matched to words and transcribed into text.
Stage 5 (Language Understanding): Intent and meaning are identified from the transcribed text.
Stage 6 (Response Generation): A reply is formed and synthesized into audio output for the user.
In a voice agent, all six stages run in near real time, fast enough that the exchange feels like talking to a person.
What Are the Main Types of Speech Processing?
Speech processing is usually divided into three core areas. Together they cover the full journey of spoken language into and out of a machine.
Speech Recognition (ASR): The Listening Side
Automatic speech recognition (ASR) converts spoken audio into written text. It is how a device captures what you said and turns it into something it can act on.
ASR powers dictation, transcription tools, and the first step of any voice assistant or AI voice agent.
Speech Synthesis (TTS): The Speaking Side
Speech synthesis, also called text-to-speech (TTS), turns written text into spoken audio. It is what gives a system a voice to respond with.
For a deep dive into how synthetic speech is generated, see the dedicated Speech Synthesis page.
Speech and Signal Analysis: Beyond Just Words
Beyond recognizing words, speech processing can also analyze the signal itself: identifying who is speaking, detecting emotion or stress, or filtering background noise.
Speaker identification is closely related to voice recognition. See the Voice Recognition page for how identity is pulled from a voiceprint.
How Is Speech Processing Used in AI Voice Agents?
In modern AI, speech processing is what lets software hold a real spoken conversation. Voice agents use the whole pipeline together, all in near real time.
How a Voice Agent Processes Speech End to End
A caller speaks. Speech recognition transcribes their words. A language model interprets what they meant. Speech synthesis speaks a natural reply back.
Because each stage feeds the next, low latency and accuracy throughout the speech processing pipeline are what make an automated voice agent actually useful for tasks like bookings, FAQs, and order status.
See also: AI Voice Agents for Customer Service, which covers how the pipeline works in a live product.
Speech Processing vs Speech Synthesis vs Speech Recognition: What Is the Difference?
Speech Processing covers the entire field: recognition, synthesis, and signal analysis together. It is the umbrella discipline.
Speech Recognition (ASR) covers converting spoken audio into text, which is the listening step only. It is one component inside speech processing.
Speech Synthesis (TTS) covers converting text into spoken audio, which is the speaking step only. It is also one component inside speech processing.
In short: recognition is listening, synthesis is speaking, and processing is the whole discipline that contains both, plus signal analysis.
Frequently Asked Questions (FAQs)
What is speech processing?
Speech processing is the field of computer science that deals with analyzing, interpreting, and generating spoken language. It covers speech recognition (audio to text), speech synthesis (text to audio), and signal analysis, powering voice assistants, transcription tools, and AI voice agents.
What is the process of speech in a speech processing system?
The process moves through a pipeline: capture an audio signal, clean it, extract measurable features, recognize the words, interpret the meaning, and in conversational systems generate a spoken reply. Each stage hands structured information to the next, so accuracy at every step matters.
What is the difference between speech processing and speech recognition?
Speech processing is the broad field covering recognition, synthesis, and signal analysis. Speech recognition is just one part of it, specifically converting spoken audio into written text. Every speech recognition system is part of speech processing, but speech processing involves much more than recognition alone.
How is speech processing used in AI?
AI uses speech processing so machines can understand and produce spoken language. It underpins voice assistants, real-time transcription, call-center analytics, and AI voice agents. Modern systems use machine-learning models at each stage, making them far more accurate and natural than older rule-based approaches.
What is the difference between speech processing and speech synthesis?
Speech synthesis is one specific part of speech processing, the output side that turns text into spoken audio. Speech processing is the wider field that includes synthesis, recognition, and signal analysis. Synthesis handles speaking, recognition handles listening, and processing is the umbrella that contains both.
How do AI voice agents use speech processing?
Voice agents rely on the entire speech processing pipeline. Recognition transcribes the caller's words. A language model interprets the intent. Synthesis generates a spoken reply. All of this runs in near real time so the conversation feels natural, handling bookings, FAQs, and order queries without a human in the loop.
How long does it take to set up an AI voice agent powered by speech processing?
A basic voice agent on a no-code platform can be live in under an hour. Connect your channel, define the use case, and test. Custom integrations with CRMs or multi-language configurations typically take a few days to a few weeks, including quality testing across edge cases.
Does speech processing support multiple languages?
Yes. Most modern ASR and TTS systems support a wide range of languages, including major global languages and regional variants. Coverage varies by platform and model. If you need multilingual support, check the specific languages listed by your provider before deployment, especially for less common dialects.
Is speech processing secure? Where does the audio go?
Audio handling depends on the platform. In most enterprise systems, audio is processed in transit, often encrypted, and either discarded or stored for a defined retention period. Before deploying a voice AI system, confirm the provider's data retention policy, encryption standards, and whether audio is used for model training.
How much does speech processing technology cost to use?
Costs vary widely depending on the approach. Cloud ASR and TTS APIs typically charge per second of audio or per character processed, with free tiers for low volumes. Full voice agent platforms often use per-conversation or monthly subscription pricing. Open-source models can be self-hosted at infrastructure cost.
What is the difference between speech processing and natural language processing (NLP)?
Speech processing handles the audio side, converting sound to text and text to sound. Natural language processing handles the language side, understanding meaning, intent, and context from text. In a voice agent, speech processing captures and produces the spoken form, while NLP works on what the words actually mean.
Can speech processing work in noisy environments?
Modern ASR systems use noise-cancellation and signal-cleaning stages specifically to handle background noise. Performance still degrades in very loud environments, and most systems need at least a moderate signal-to-noise ratio. High-quality microphones and noise-filtering hardware improve results significantly.