Natural language understanding powers the latest breakthroughs in conversational AI.
This guide unravels the fundamentals of NLU—from language processing techniques like tokenization and named entity recognition to leveraging machine learning for intent classification and sentiment analysis.
We'll walk through building an NLU model step-by-step, from gathering training data to evaluating performance metrics.
You'll also learn how pre-trained models like BERT and GPT-3 can give you a head start.
Additionally, the guide explores specialized NLU tools, such as Google Cloud NLU and Microsoft LUIS, that simplify the development process.
While NLU has challenges like sensitivity to context and ethical considerations, its real-world applications are far-reaching—from chatbots to customer support and social media monitoring.
Follow this guide to gain practical insights into natural language understanding and how it transforms interactions between humans and machines.
NLU Basics: Understanding Language Processing
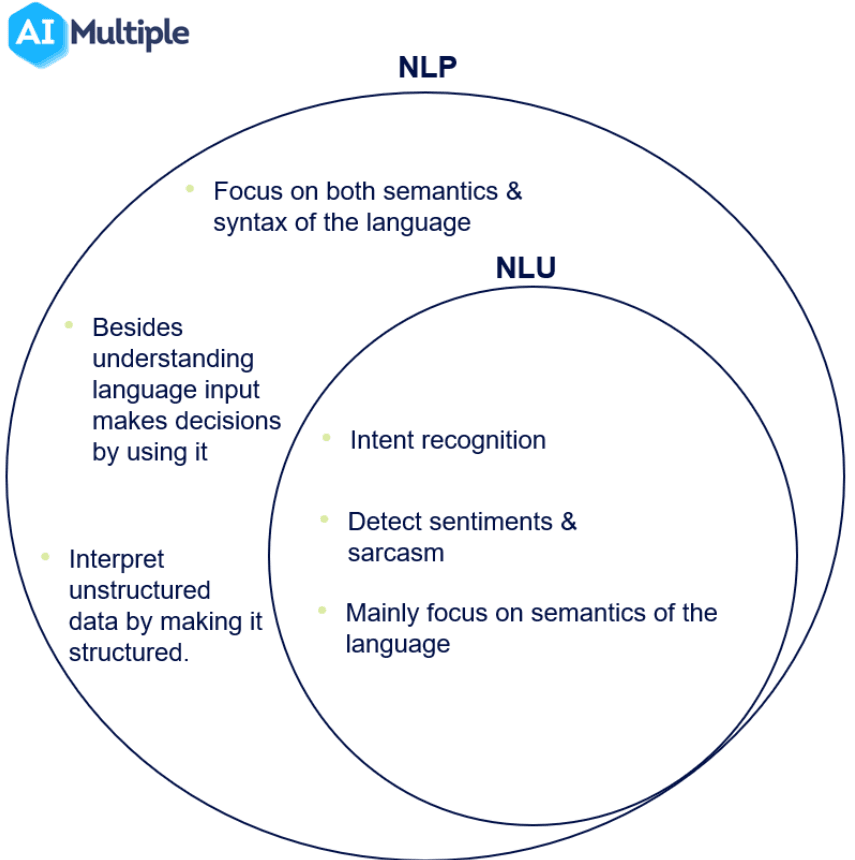
NLU model is all about language processing. To extract meaning and context from human language, NLU relies on several key components:
Below are some of the some key components for NLU basics.
Tokenization and Word Segmentation
Tokenization is the process of breaking down text into individual words or tokens.
This is a crucial step in NLU as it helps identify the key words in a sentence and their relationships with other words.
Part-of-Speech (POS) Tagging
POS tagging assigns a part-of-speech label to each word in a sentence, like noun, verb, adjective, etc.
This helps in identifying the role of each word in a sentence and understanding the grammatical structure.
Suggested Reading:
Named Entity Recognition (NER)
NER involves identifying and extracting specific entities mentioned in the text, such as names, places, dates, and organizations.
This can be useful in categorizing and organizing data, as well as understanding the context of a sentence.
Suggested Reading:
Syntax and Semantic Analysis
Syntax analysis involves analyzing the grammatical structure of a sentence, while semantic analysis deals with the meaning and context of a sentence.
NLU utilizes both these approaches to understand language and draw insights.
Now let us see how NLU model works.
How NLU Works: Machine Learning and NLP Techniques
The real power of NLU comes from its integration with machine learning and NLP techniques.
Here's a quick overview of some popular techniques used in NLU:
Supervised Learning for Intent Classification
Intent classification involves identifying the intent behind a user query. Supervised learning algorithms can be trained on a corpus of labeled data to classify new queries accurately.
For example, a chatbot can use this technique to determine if a user wants to book a flight, make a reservation, or get information about a product.
Unsupervised Learning for Entity Extraction
Entity extraction involves identifying and extracting specific entities mentioned in the text.
Unsupervised techniques such as clustering and topic modeling can group similar entities and automatically identify patterns.
For example, an NLU-powered chatbot can extract information about products, services, or locations from unstructured text.
Deep Learning for Sentiment Analysis
Sentiment analysis involves identifying the sentiment or emotion behind a user query or response.
Deep learning algorithms, like neural networks, can learn to classify text based on the user's tone, emotions, and sarcasm.
For example, a chatbot can use sentiment analysis to detect if a user is happy, upset, or frustrated and tailor the response accordingly.
Now after looking into how it works let’s see the steps to build an NLU model
Building an NLU Model: Step-by-Step Guide
Building an NLU model from scratch may seem daunting, but fret not!
This section will break down the process into simple steps and guide you through creating your own NLU model.
Step 1
Data Collection and Preprocessing
The first step in building an effective NLU model is collecting and preprocessing the data.
You'll need a diverse dataset that includes examples of user queries or statements and their corresponding intents and entities. Ensure your dataset covers a range of scenarios to ensure the Model's versatility.
Once you have your dataset, it's crucial to preprocess the text to ensure consistency and improve the accuracy of the Model.
This includes removing unnecessary punctuation, converting text to lowercase, and handling special characters or symbols that might affect the understanding of the language.
Step 2
Training the Model using Machine Learning Algorithms
After preprocessing the data, it's time to train your NLU model using machine learning algorithms.
One popular approach is to utilize a supervised learning algorithm, like Support Vector Machines (SVM) or Naive Bayes, for intent classification.
These algorithms learn from the labeled examples in your dataset and can accurately classify new queries based on their intents.
You can use techniques like Conditional Random Fields (CRF) or Hidden Markov Models (HMM) for entity extraction. These algorithms take into account the context and dependencies between words to identify and extract specific entities mentioned in the text.
Step 3
Evaluating and Fine-tuning the Model
Once the NLU Model is trained, it's essential to evaluate its performance.
Split your dataset into a training set and a test set, and measure metrics like accuracy, precision, and recall to assess how well the Model performs on unseen data.
This evaluation helps identify any areas of improvement and guides further fine-tuning efforts.
Fine-tuning the Model involves iteratively adjusting the Model's parameters based on the evaluation results.
This process helps optimize the Model's performance and ensures it keeps improving over time.
Consider experimenting with different algorithms, feature engineering techniques, or hyperparameter settings to fine-tune your NLU model.
After building NLU model, its time for leveraging Pre-trained NLU Model.
Leveraging Pre-trained NLU Models
Building an NLU model from scratch is one of many approaches. Pre-trained NLU models can significantly speed up the development process and provide better performance.
Let's see the pre-trained models and explore their advantages.
Introduction to Pre-trained NLU Models
Pre-trained NLU models are models already trained on vast amounts of data and capable of general language understanding.
These models have been learned from various contexts and can be fine-tuned for specific tasks.
They provide a head start in building NLU models and can save time and effort.
Exploring Popular Pre-trained Models
Several popular pre-trained NLU models are available today, such as BERT (Bidirectional Encoder Representations from Transformers) and GPT-3 (Generative Pre-trained Transformer 3).
These models have achieved groundbreaking results in natural language understanding and are widely used across various domains.
Incorporating Pre-trained Models into your NLU Pipeline
To incorporate pre-trained models into your NLU pipeline, you can fine-tune them with your domain-specific data. This process allows the Model to adapt to your specific use case and enhances performance.
Fine-tuning involves training the pre-trained Model on your dataset while keeping the initial knowledge intact. This way, you get the best of both worlds - the power of the pre-trained Model and the ability to handle your specific task.
Now let us uncover the NLU tools and its framework.
Suggested Reading:
Unleashing the Power of Natural Language Understanding
NLU Tools and Frameworks
To make your NLU journey even more accessible, some specialized tools and frameworks provide abstractions and simplify the building process.
Here's a glimpse of some popular NLU tools and frameworks that can help you get started:
Google Cloud NLU
Google Cloud NLU is a powerful tool that offers a range of NLU capabilities, including entity recognition, sentiment analysis, and content classification.
It's built on Google's highly advanced NLU models and provides an easy-to-use interface for integrating NLU into your applications.
Microsoft LUIS
Microsoft Language Understanding Intelligent Service (LUIS) is a cloud-based NLU service that allows you to build language understanding models using a simple, intuitive interface.
LUIS supports multiple languages and provides pre-built models for common intents and entities, making it easier to get started.
Rasa NLU
Rasa NLU is an open-source NLU framework with a Python library for building natural language understanding models.
It offers support for intent classification, entity recognition, and dialogue management.
Rasa NLU also provides tools for data labeling, training, and evaluation, making it a comprehensive solution for NLU development.
spaCy
A well-liked open-source natural language processing package, spaCy has solid entity recognition, tokenization, and part-of-speech tagging capabilities.
It offers pre-trained models for many languages and a simple API to include NLU into your apps.
Implementing NLU comes with its fair share of challenges and limitations. Let's explore some of the main hurdles faced in the world of NLU:
Challenges & Limitations of NLU
Understanding human language can seem like a simple task, but for machines it remains a complex challenge.
While Natural Language Understanding systems have come a long way, several limitations remain.
Keep reading to learn more about the ongoing struggles with ambiguity, data needs, and ensuring responsible AI.
Ambiguity and Context-Sensitivity
Language is inherently ambiguous and context-sensitive, posing challenges to NLU models. Understanding the meaning of a sentence often requires considering the surrounding context and interpreting subtle cues.
Ambiguity arises when a single sentence can have multiple interpretations, leading to potential misunderstandings for NLU models.
The Need for Large Datasets and Computing Resources
Training NLU models requires large amounts of data for effective learning. Gathering diverse datasets covering various domains and use cases can be time-consuming and resource-intensive.
Additionally, training NLU models often requires substantial computing resources, which can be a limitation for individuals or organizations with limited computational power.
Bias and Ethical Considerations
NLU models can unintentionally inherit biases in the training data, leading to biased outputs and discriminatory behavior. Ethical considerations regarding privacy, fairness, and transparency in NLU models are crucial to ensure responsible and unbiased AI systems.
Now that we've covered the evaluation metrics and challenges let's explore some exciting real-world applications where NLU shines:
Applications of NLU
New technologies are taking the power of natural language to deliver amazing customer experiences.
Keep reading to discover three innovative ways that Natural Language Understanding is streamlining support, enhancing experiences and empowering connections.
Chatbots and Virtual Assistants
NLU has made chatbots and virtual assistants commonplace in our daily lives.
These conversational AI bots are made possible by NLU to comprehend and react to customer inquiries, offer individualized support, address inquiries, and do various other duties.
Customer Support Automation
NLU empowers customer support automation by automating the routing of customer queries to the right department, understanding customer sentiments, and providing relevant solutions.
This streamlines the support process and improves the overall customer experience.
Sentiment Analysis and Social Media Monitoring
NLU models excel in sentiment analysis, enabling businesses to gauge customer opinions, monitor social media discussions, and extract valuable insights.
This information can be used for brand monitoring, reputation management, and understanding customer satisfaction.
Conclusion
Natural language understanding is a powerful AI technique that opens up many exciting possibilities across various domains.
This guide provided an overview of popular NLU frameworks and tools like Google Cloud NLU, Microsoft LUIS, and Rasa NLU to help get started with development.
Fine-tuning pre-trained models enhances performance for specific use cases. Real-world NLU applications such as chatbots, customer support automation, sentiment analysis, and social media monitoring were also explored.
While challenges regarding data, computing resources, and biases must be addressed, NLU has far-reaching potential to revolutionize how businesses engage with customers, monitor brand reputation, and gain valuable customer insights.
Following best practices in model evaluation, development, and application can help organizations leverage this rapidly advancing field.
Get your own deep trained Chatbot with BotPenguin, Sign Up Today!
BotPenguin provides Chatbot creation for different social Platforms-
Frequently Asked Questions (FAQs)
What is NLU and why is it important for beginners in AI?
NLU stands for Natural Language Understanding, which enables machines to comprehend and interpret human language. It is essential for beginners in AI as it forms the foundation for building chatbots, virtual assistants, and other language-based AI applications.
How do you evaluate the performance of an NLU model?
NLU models are evaluated using metrics such as intent classification accuracy, precision, recall, and the F1 score. These metrics provide insights into the model's accuracy, completeness, and overall performance.
What are the challenges faced in implementing NLU?
Implementing NLU comes with challenges, including handling language ambiguity, requiring large datasets and computing resources for training, and addressing bias and ethical considerations inherent in language processing.
What are the real-world applications of NLU?
NLU has various real-world applications, such as chatbots and virtual assistants for customer support, sentiment analysis for social media monitoring, and automating tasks in different domains where language understanding is crucial.
What steps are involved in getting started with NLU as a beginner?
To get started with NLU, beginners can follow steps such as understanding NLU concepts, familiarizing themselves with relevant tools and frameworks, experimenting with small projects, and continuously learning and refining their skills.
How can NLU empower businesses and industries?
NLU empowers businesses and industries by improving customer support automation, enhancing sentiment analysis for brand monitoring, optimizing customer experience, and enabling personalized assistance through chatbots and virtual assistants. It enhances efficiency and unlocks valuable insights from language data.