Introduction
Picture this: you’re scrolling through your favorite social media platform, and suddenly, an AI-powered chatbot pops up, offering you tailored recommendations just when you need them.
This isn't magic; it's the power of LLM platforms. A report by McKinsey reveals that organizations utilizing AI technologies, including LLMs, are likely to achieve a productivity boost of 40% or more!
As demand for these intelligent solutions skyrockets, the ability of LLM platforms to scale becomes crucial. It’s like running a popular food truck—when the crowd comes pouring in, you must expand your kitchen to keep the orders flowing smoothly.
In this blog, we’ll explore essential strategies for scaling LLM platforms effectively, ensuring they can handle the pressure while delivering exceptional performance. Get ready to uncover the new scalability tips that will take your LLM platform to the next level!
Why is Scalability Important for LLM Platforms?
Scalability is a cornerstone of any successful LLM platform, as it ensures that systems can grow and handle increased demands without compromising performance.
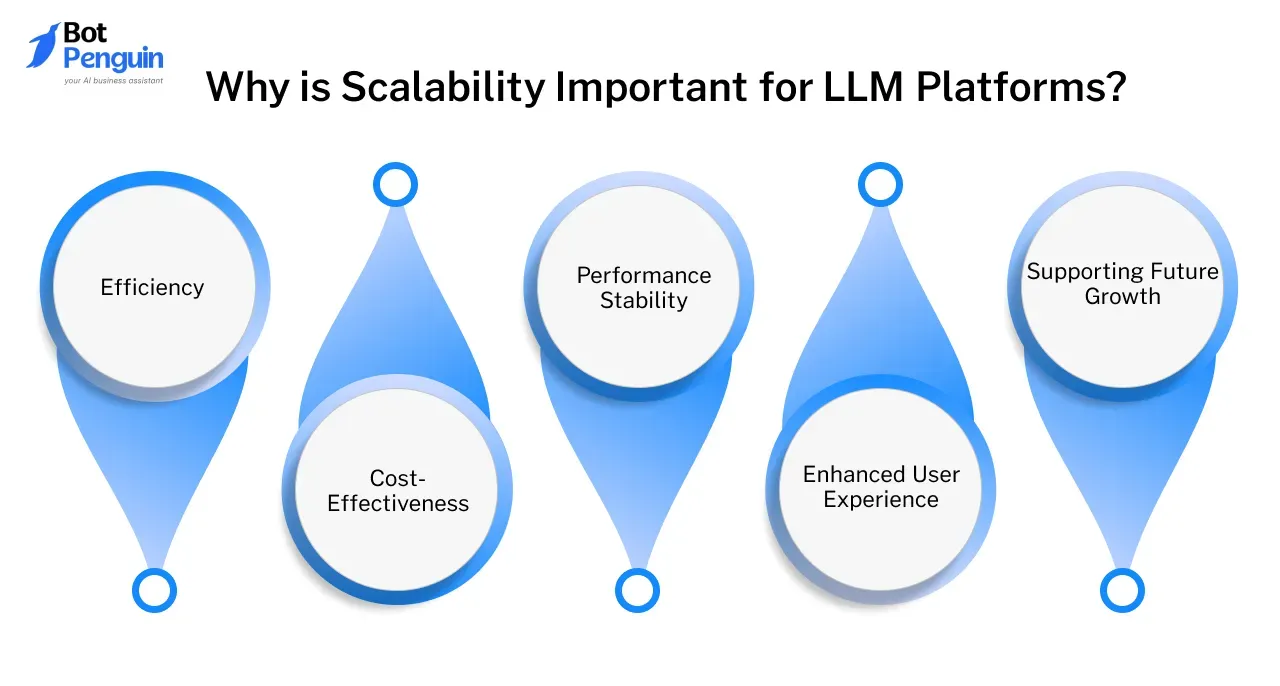
Let’s look into why scalability is so crucial for LLM development services and companies striving to offer top-notch LLM development tools:
- Efficiency: With more users relying on LLM platforms every day, scalability ensures that data processing remains fast, even with increased traffic.
For example, a major LLM development company like OpenAI optimizes infrastructure to provide seamless AI solutions to millions without lag.
- Cost-Effectiveness: Proper scalability can dramatically reduce operating costs. By optimizing server and resource usage, LLM development services companies can avoid skyrocketing expenses while growing.
This cost-saving approach makes these platforms more sustainable long-term, helping companies focus funds on further LLM development tools and features.
- Performance Stability: Handling large datasets and intricate computations is core to LLM platforms. With good scalability, platforms can manage this complexity without lag or failure, keeping quality standards high.
Think of Amazon's Alexa, which scales to accommodate millions of real-time user interactions daily, keeping it stable and reliable.
- Enhanced User Experience: A scalable LLM platform ensures that users always have fast, accurate responses, regardless of demand.
This ability is particularly crucial for customer service applications, where users expect instant replies.
- Supporting Future Growth: Scalability allows LLM development service providers to future-proof their platforms.
What are the Challenges of Scaling LLM Platforms?
LLM development companies often encounter the following obstacles:
Computational Power
As the scale of data and model complexity increases, LLM platforms demand extensive computational resources to maintain performance.
Expanding datasets require powerful GPUs or TPUs, which can become a limiting factor for even the most advanced LLM development services.
Cost Management

Scaling LLM development services is costly, as it involves increased hardware, cloud storage, and software licenses.
Without careful budgeting and optimization, costs can quickly spiral, impacting the profitability of LLM development companies.
Data Handling
Managing large-scale datasets effectively is crucial. As data grows, organizing, storing, and retrieving it without creating bottlenecks becomes challenging.
Latency
Increased traffic leads to latency issues that affect the platform's responsiveness. Minimizing latency is crucial for real-time applications like chatbots or live assistance.
Solutions like edge computing, which processes data closer to the user, are often adopted by LLM development tools to reduce delays and maintain seamless interaction, especially during peak usage times.
Integration Issues
Scaling often requires integrating various LLM development tools and adding new LLM development services. Compatibility between old and new systems can become challenging, creating potential interruptions or inefficiencies.
Many LLM development services companies rely on a modular architecture, allowing them to plug in new tools seamlessly without disrupting existing workflows, which makes scaling more manageable.
Key Metrics for Measuring Scalability
Here are some of the most crucial metrics for evaluating the scalability of LLM development services and LLM development tools:
Throughput
Throughput indicates the volume of data or requests your LLM platform can process within a specific timeframe. It’s a clear measure of how well the system manages increased workloads.
LLM development companies often use this metric to determine if their resources and infrastructure can keep up with expansion.
Latency
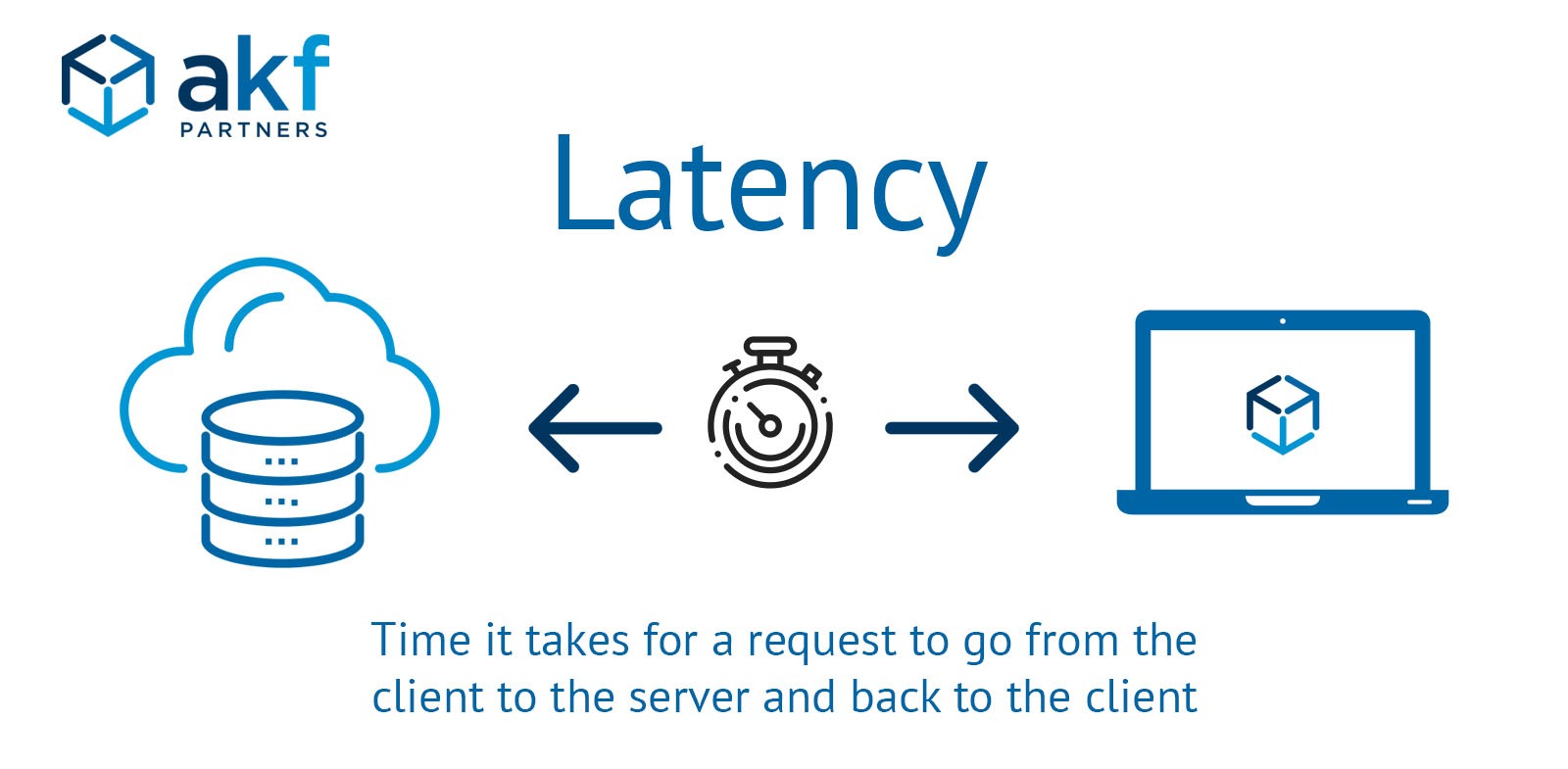
Latency measures the time it takes for a platform to respond to a request. For LLM development services focused on real-time applications, low latency is crucial for delivering fast, reliable responses.
When latency rises, it’s often a sign that the platform’s current setup needs optimization to support heavier loads.
Resource Utilization
Efficient scalability requires optimal use of CPU, memory, and storage without overloading systems. Resource utilization tracks how well these resources are used, providing insights into cost efficiency.
LLM development services companies aim to maximize resource use without overuse, as balanced resource utilization prevents excessive costs while maintaining performance.
Error Rates

Error rates represent the frequency of failed requests or operations within the LLM platform. As systems scale, it’s crucial to keep error rates low to avoid reliability issues.
A spike in errors might indicate challenges such as excessive traffic or integration issues with new LLM development tools.
Minimizing errors is vital for maintaining stability, especially as platforms manage larger datasets and a growing user base.
Cost per Request
The cost per request is critical for determining the cost-effectiveness of a scaling LLM platform.
This metric helps LLM development services companies gauge how efficiently they’re processing each request financially.
Uptime and Availability

Uptime measures the percentage of time your LLM platforms remain accessible and functional. High uptime is essential for a positive user experience and reliability.
As systems scale, ensuring consistent uptime becomes challenging but essential; frequent downtimes can diminish user trust and undermine scalability efforts.
Scalability Testing Results
Scalability testing simulates higher traffic or larger datasets to evaluate how well the platform performs under stress.
These tests reveal areas where LLM platforms may face bottlenecks, giving LLM development services companies valuable insights for improvement.
How to Assess the Scalability of an LLM Platform
Here’s a step-by-step guide to assessing scalability, which is especially useful for LLM development companies looking to build robust solutions.
Load Testing
Load testing simulates high-demand scenarios by introducing large numbers of requests or users, and assessing how well the platform maintains performance under stress.
A scalable LLM platforms should continue to function smoothly without performance dips as the load increases. This testing helps LLM development services companies understand the platform’s limits and make necessary improvements to ensure the system can handle real-world demand.
Performance Monitoring
Continuous monitoring of metrics like CPU usage, memory consumption, and response times provides insights into how efficiently the LLM platform manages resources.
A well-designed, scalable platform should show stable and balanced resource utilization, even as user demand grows.
Benchmarking
Benchmarking your platform against industry standards or similar LLM platforms provides a reference for expected performance. This allows LLM development services companies to see if their platform’s scalability aligns with others in the field.
By identifying gaps, they can make informed decisions on whether to implement new LLM development tools or make upgrades to keep up with competitors.
Scalability Testing
Unlike load testing, scalability testing gradually increases the platform’s workload to see how it handles steady growth over time.
This type of testing can reveal potential bottlenecks in resource management or integration, indicating where LLM development services might need to step in with optimizations.
Cost Analysis
Effective scaling should be both performance-driven and cost-efficient. Cost analysis helps you track changes in infrastructure and processing costs as the platform scales.
Monitoring cost per request as user load grows is essential for LLM development companies aiming to balance profitability with performance.
Error Rate Tracking

Scalability means not only handling more users but also ensuring consistent reliability. Tracking errors closely allows companies to address issues before they impact users.
Using advanced LLM development services can help bring error rates down, ensuring a dependable experience for users.
Uptime Tracking
High uptime reflects a scalable, resilient infrastructure. As demand grows, tracking downtime provides insights into how well the platform’s infrastructure holds up under strain.
Frequent downtime suggests that scalability limits are being tested and that additional resources or LLM development services might be necessary to reinforce stability.
The Role of Data in LLM Scalability
Data plays a central role in determining the scalability of LLM platforms. As these platforms grow, handling data efficiently while maintaining performance and reliability becomes increasingly challenging.
Here’s how data influences scalability in LLM development services.
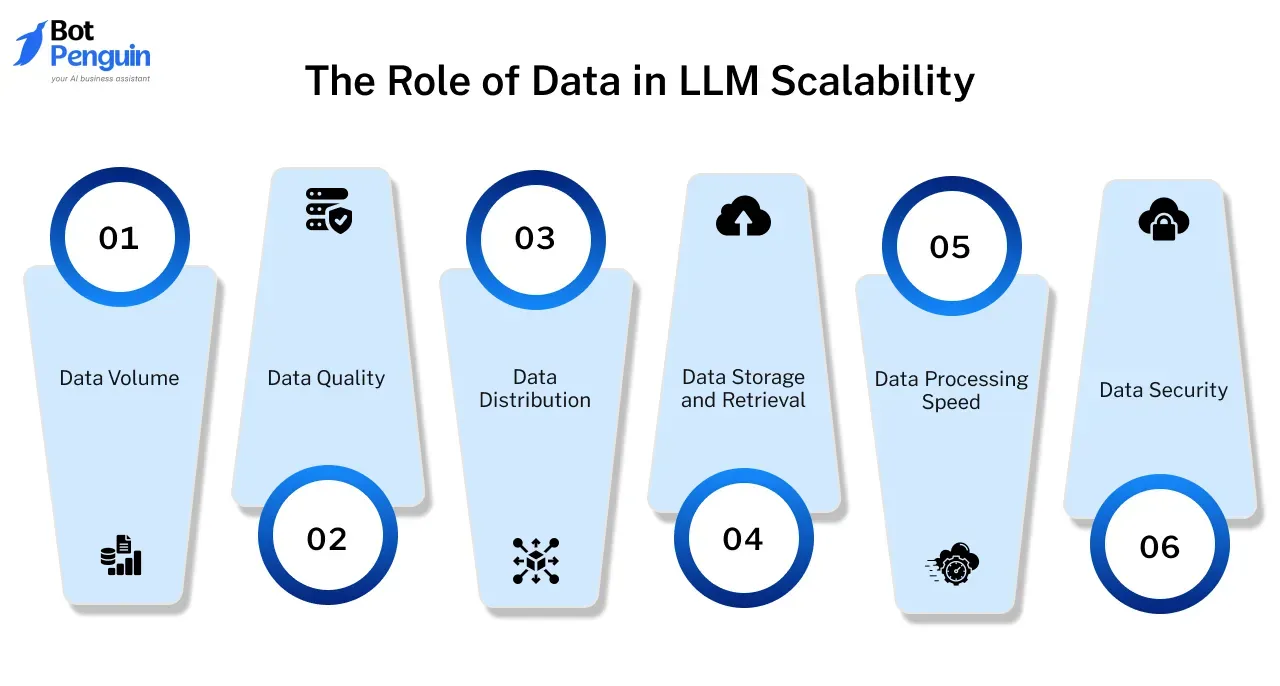
Data Volume
As an LLM platform scales, it needs to process larger datasets, which drives up computational demands.
The right LLM development tools optimize data processing and help platforms manage growth smoothly.
Data Quality
It’s not just about handling more data—scalability also requires high-quality data to maintain model accuracy. Poor-quality data can lead to inaccurate outputs and slower processing.
Scalable LLM development services often include data cleaning and preprocessing, ensuring that as the platform grows, data quality remains high and accuracy improves.
Data Distribution
Distributing data across multiple servers or locations helps balance system loads and prevents performance lags.
Effective data distribution is essential for handling more users and tasks, reducing latency, and maintaining scalability.
Data Storage and Retrieval
Efficient storage and quick retrieval are essential for scaling. As data volume increases, the need for scalable storage solutions grows.
LLM platforms using distributed databases or cloud storage can avoid bottlenecks and keep retrieval times low, ensuring a smoother scaling process.
Data Processing Speed
Scalable LLM platforms must process data swiftly to maintain performance under heavy workloads.
Optimizing data processing speed through advanced algorithms and hardware solutions ensures that platforms can handle increased demand without sacrificing quality or efficiency.
Data Security

As LLM platforms scale, data security becomes crucial to protect growing datasets and comply with privacy standards.
By implementing strong encryption and data protection measures, LLM development services help platforms safeguard data even as they scale.
Advanced Techniques for LLM Platforms
Scaling LLM platforms effectively is essential to meet the growing demand for larger models and rapid processing speeds.
Let’s dive into these strategies to ensure that your LLM platform can handle growth sustainably.
Distributed Training Frameworks
Distributed training frameworks are invaluable for LLM platforms looking to manage large datasets and complex models.
By distributing the training load across multiple machines, these frameworks can significantly reduce the time required to train large models. This approach helps LLM development services scale their models more effectively by leveraging parallel computing.
Popular frameworks like TensorFlow's Distributed Strategy and PyTorch’s Distributed Data-Parallel enable LLM platforms to parallelize training tasks, making it possible to handle heavier computational demands.
By integrating distributed training, LLM development tools optimize scalability, allowing platforms to expand without sacrificing performance.
Model Compression Techniques

Model compression techniques are key to maintaining efficiency as LLM platforms grow. Larger models consume more memory and processing power, potentially limiting scalability.
- Quantization reduces memory usage by lowering the precision of model weights.
- Pruning removes redundant parameters.
- Knowledge distillation enables smaller models to mimic larger ones.
These techniques allow LLM development services to deploy complex models at a lower computational cost, making it easier for LLM platforms to scale efficiently.
Hybrid Cloud Solutions
A hybrid cloud approach can offer LLM platforms both flexibility and cost savings.
Combining private and public cloud environments, hybrid solutions allow LLM development services companies to keep sensitive data secure while leveraging the scalability of public cloud resources.
With hybrid cloud solutions, LLM platforms can optimize cost by scaling on-demand without the need for significant upfront hardware investments.
Suggested Reading:
Custom LLM Models vs Pretrained Models: A Complete Analysis
Edge Computing for LLMs
Edge computing addresses latency issues, a common challenge as LLM platforms scale globally. By processing data closer to the source, edge computing minimizes the delay in data transmission between servers and users.
Deploying LLM platforms on edge devices, like local servers or smartphones, enables LLM development companies to deliver low-latency experiences, supporting scalability by expanding the user base without a drop in performance.
AutoML for LLM Optimization
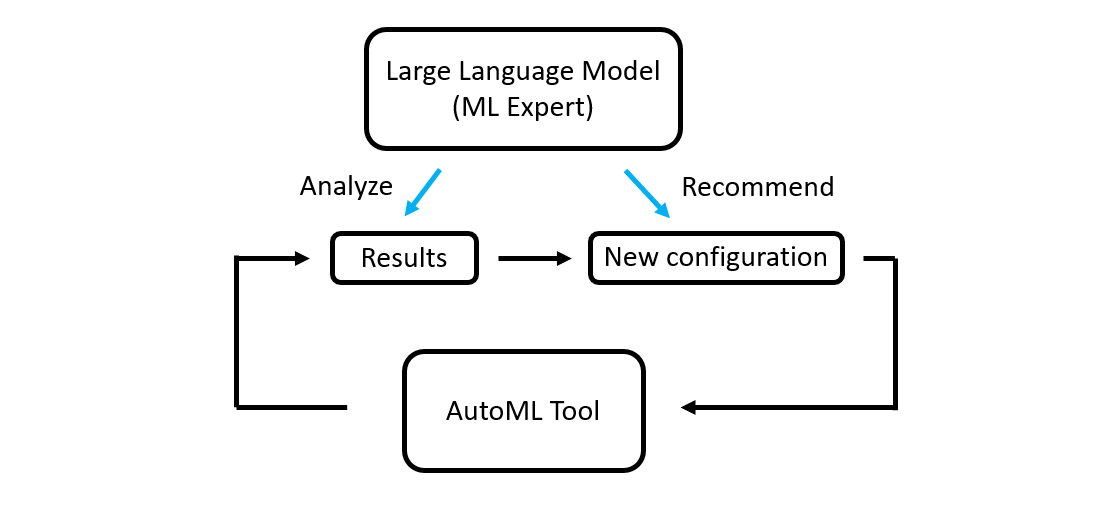
AutoML (Automated Machine Learning) tools streamline the optimization process as LLM platforms scale.
By using AutoML, LLM development services can efficiently scale models without requiring large teams of data scientists, saving time and resources.
This allows LLM platforms to focus on scaling and improving functionalities rather than constant fine-tuning, creating a more sustainable growth process.
Responsible AI and Scalability
As LLM platforms scale, implementing Responsible AI practices is critical. Ensuring fairness, transparency, and safety in models is essential for ethical scalability.
LLM platforms should incorporate responsible AI by addressing data biases, protecting user privacy, and maintaining decision transparency.
By adopting these strategies, LLM platforms can manage the demands of growth more effectively, fostering an environment where both scalability and reliability coexist.
Conclusion
In conclusion, the scalability of LLM platforms is crucial for meeting the increasing demands of modern applications.
By implementing best practices such as distributed training frameworks, model compression techniques, and hybrid cloud solutions, businesses can ensure their LLM platforms grow efficiently while maintaining high performance.
Leveraging edge computing and AutoML further enhances scalability, allowing for real-time responses and optimized model performance. Additionally, incorporating responsible AI practices is essential to build trust and ensure ethical use as LLM platforms expand.
As the landscape of AI continues to evolve, prioritizing these strategies will empower organizations to harness the full potential of LLM platforms, driving innovation and delivering exceptional user experiences.
Embracing these scalability techniques not only prepares LLM platforms for future growth but also positions businesses at the forefront of the AI revolution, ready to tackle new challenges and seize opportunities in an ever-changing digital world.
Frequently Asked Questions (FAQs)
How can distributed training improve the scalability of LLM platforms?
Distributed training significantly enhances the scalability of LLM platforms by distributing workloads across multiple machines.
This approach allows LLM platforms to efficiently manage larger datasets and complex models through task parallelization, which reduces training time and optimizes resource usage.
What role does model compression play in the scalability of LLM platforms?
Model compression is crucial for the scalability of LLM platforms as it reduces the size of large models.
Techniques such as quantization, pruning, and knowledge distillation enable LLM platforms to achieve faster processing speeds and lower memory usage, facilitating efficient scalability without compromising performance.
Why are hybrid cloud solutions beneficial for LLM platforms' scalability?
Hybrid cloud solutions provide significant benefits for the scalability of LLM platforms by merging public and private cloud environments.
This enables companies to securely manage sensitive data while leveraging the flexibility and scalability of public cloud resources for intensive computational tasks, optimizing both cost and performance.
How does edge computing enhance the scalability of LLM platforms?
Edge computing enhances the scalability of LLM platforms by minimizing latency through data processing closer to the user.
This allows real-time applications, such as conversational AI, to provide faster responses, even as the LLM platform expands globally.
What is AutoML, and how does it support the scalability of LLM platforms?
AutoML (Automated Machine Learning) supports the scalability of LLM platforms by automating the optimization of models.
It adjusts hyperparameters and suggests better configurations, leading to faster and more efficient scalability. This allows LLM platforms to improve performance without requiring extensive manual intervention from data scientists.