

RAG vs Fine-Tuning: Which Strategy is Right for Your LLM?
Updated at May 8, 2026
13 min to read

Large Language Models (LLMs) have already gained prominence across various industries, transforming the way businesses use AI.
However, developers are constantly seeking innovative methods to enhance the performance of these LLMs. One strategy that assists them in this process is Retrieval-Augmented Generation (RAG), which improves accuracy by incorporating relevant external data.
This ensures that LLMs generate more precise and contextually aligned responses tailored to specific business needs.
However, not all large language models (LLMs) are created equal. Some models underperform while others excel in unexpected ways.
This isn’t about picking the most popular model or the one with the biggest budget behind it. It is about choosing the right tool for the job, specifically, for Retrieval-Augmented Generation (RAG).
In this guide, you will learn about the best LLM for RAG implementations and why they matter. Let us get started.
RAG is a method that combines retrieval-based systems with generative AI. The retrieval system searches and fetches relevant information, while the generative model uses this data to produce coherent, contextual outputs.
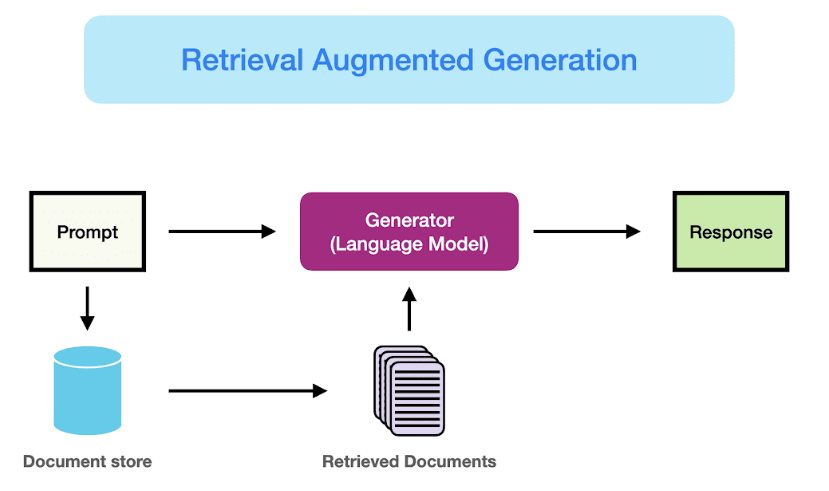
Retrieval sources can include databases, embeddings (vector stores), or live web search results. These sources ensure that responses are accurate and up to date, making RAG especially useful for real-world applications that require precise and dynamic information retrieval.
The retrieval system acts as a knowledge base, providing facts or context. The generative model takes it further by crafting human-like responses based on the retrieved data.
For instance, when asked a specific question, the retrieval component finds relevant documents, and the AI generates a clear, nuanced reply.
Not all models can handle RAG workflows equally. The best open source LLM for RAG ensures seamless integration, factual accuracy, and high-quality outputs.
Poor model performance can lead to irrelevant or incorrect responses, which defeats the purpose of RAG entirely. Picking the best LLM models for RAG is crucial for delivering reliable results.
Hence, choosing the best LLM for RAG ensures that retrieval-augmented systems generate precise, contextually aware, and high-quality responses, making them invaluable for businesses relying on AI-driven insights.
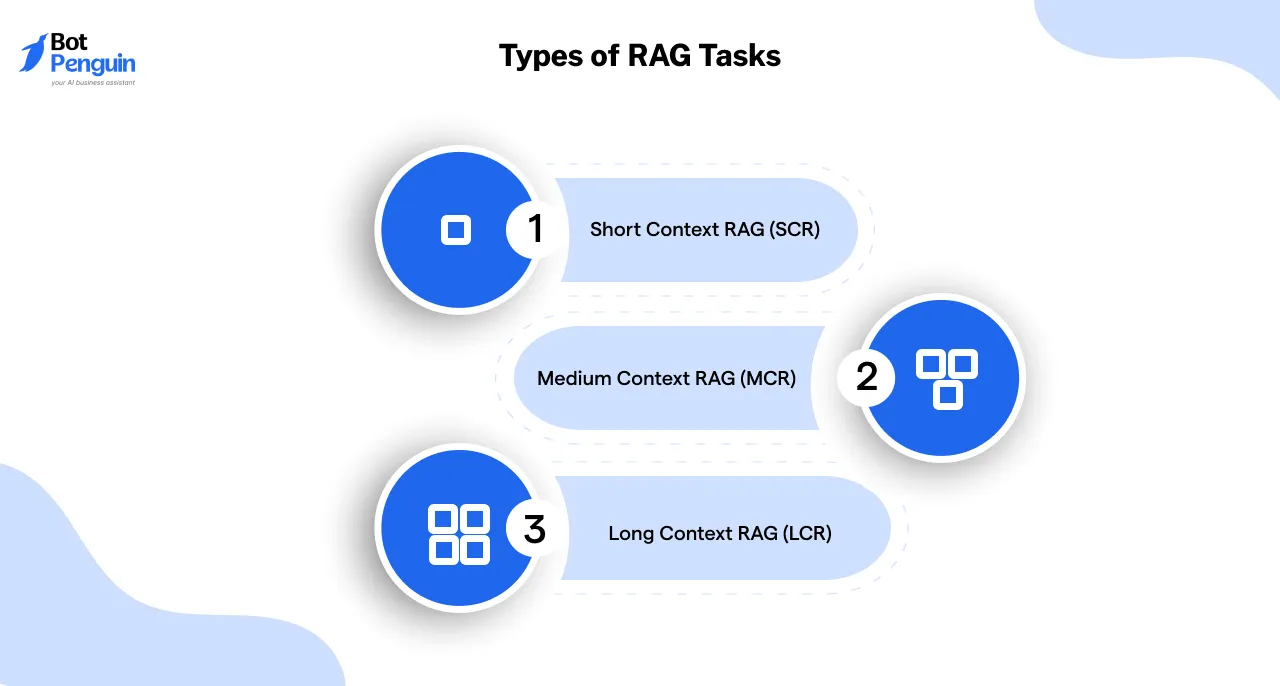
Choosing the best LLM for RAG depends heavily on the type of RAG task you are tackling. These tasks are classified based on the context length they manage.
Let us break down the main categories of RAG tasks and how they align with specific use cases.
SCR can handle contexts of less than 5000 tokens. This is equivalent to processing a short article or a brief report. It is most appropriate for tasks that involve brief, direct queries.
Think FAQ systems, customer support bots, or any application that requires quick, concise answers. The primary focus here is speed and precision. An LLM optimized for SCR should excel in delivering fast responses without compromising accuracy.
Choosing the best LLM for RAG ensures high performance, while opting for the best open source LLM for RAG can offer cost-effective and customizable solutions for specific needs.
MCR can handle contexts between 5000 to 25000 tokens, comparable to analyzing a detailed research paper or an extensive report. It is suited for tasks like multi-turn dialogues in chatbots or dynamic conversation systems.
These scenarios require balancing retrieval precision with high-quality text generation. Maintaining conversational coherence across multiple exchanges is key.
Selecting the best LLM for RAG enhances accuracy and contextual understanding, while choosing the best LLM model for RAG ensures seamless transitions between questions and answers, ultimately improving the user experience.
LCR can handle extensive contexts ranging from 40,000 to 128,000 tokens, making it suitable for tasks like document summarization, research assistance, and complex data retrieval.
With the ability to process an entire comprehensive report, thesis, or large knowledge base, it ensures that information remains coherent and contextually accurate throughout retrieval and generation.
For long-form retrieval tasks, GPT-4 Turbo (128K tokens) and Gemini 1.5 (128K tokens) are the best LLM models for RAG, offering unmatched efficiency in handling vast datasets.
These models excel at maintaining contextual consistency, reducing loss of key details, and ensuring accurate and relevant responses across extended text inputs.
Using the best LLM models for RAG helps maintain contextual flow, while selecting the best LLM for RAG ensures optimized retrieval performance, scalability, and efficiency when working with high-volume, long-context data.
Hence, understanding these different RAG task types allows you to select the best LLM for RAG based on your specific needs. Whether handling short, medium, or long contexts, the right model ensures accuracy, efficiency, and scalability in your applications.
Selecting the best LLM for RAG isn’t just about performance, it is about finding a model that fits your specific needs.
From technical capabilities to practical integration, several factors play a critical role in determining the right choice for your Retrieval-Augmented Generation workflows.
Choosing the best LLM for RAG enhances reliability, ensuring the model consistently delivers precise and context-aware responses across different use cases.
Accuracy is the backbone of a successful RAG implementation. The model must retrieve and generate contextually relevant, precise information.
A highly accurate LLM reduces errors and improves user satisfaction. When evaluating the best LLM models for RAG, focus on their track record in handling complex queries with consistency.
Deploying the best LLM for RAG strengthens reliability, enabling the model to generate accurate, context-aware responses tailored to diverse applications.
A scalable LLM is essential for handling large datasets and high user demands. Whether you are deploying a chatbot for thousands of users or summarizing extensive documents, scalability ensures the system can keep up without compromising performance.
The best LLM model for RAG should handle these demands seamlessly, ensuring the best LLM for RAG performs without lag or loss of accuracy.
Integration challenges can slow down implementation. Look for models that easily fit into your existing RAG pipeline, whether through APIs, plugins, or customizable workflows.
The best open source LLM for RAG often excels here, providing adaptable tools with minimal friction. Ensuring seamless compatibility allows the best LLM for RAG to function efficiently without unnecessary technical hurdles.
Balancing quality with budget constraints is critical. High-performing LLMs can be expensive, but there are cost-effective options that don’t sacrifice too much on performance.
Choosing the best LLM for RAG often involves finding this balance while keeping long-term scalability in mind.
Flexibility allows you to fine-tune the model for your specific needs.
Whether it is adapting to a niche industry or enhancing multilingual support, a flexible model ensures the best outcomes. The best open source LLM for RAG often provides this adaptability.
An active developer community and robust documentation make a significant difference. They ensure smoother troubleshooting, faster updates, and access to shared best practices.
Many of the best LLM models for RAG benefit from vibrant communities that actively contribute to their development.
By weighing these factors, you can confidently select the best LLM for RAG that aligns with your goals, budget, and technical requirements.
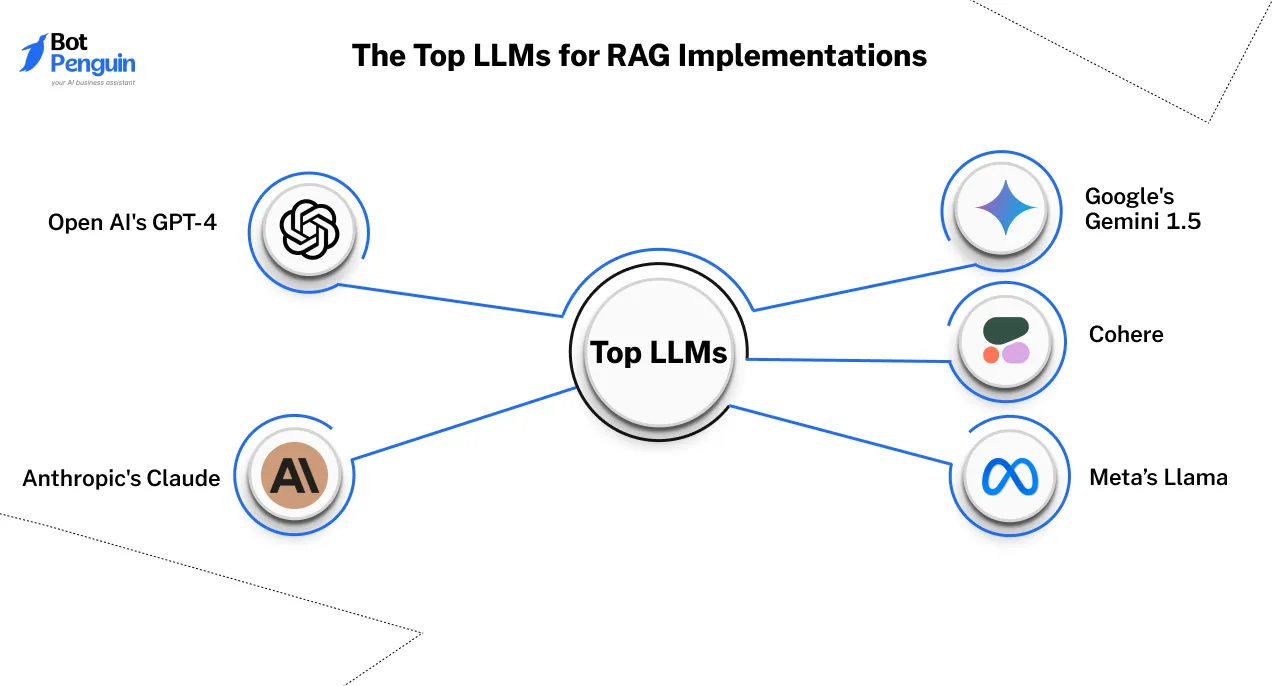
Choosing the best LLM for RAG involves understanding the unique strengths and limitations of each model.
Below, we delve into five leading contenders who excel in various RAG workflows, highlighting what makes them stand out and where they excel in practical applications.
OpenAI’s GPT-4 is a leading model in the generative AI space, delivering exceptional performance in both language understanding and creation, making it the best LLM for RAG.
Known for its versatility and contextual accuracy, GPT-4 is often seen as the gold standard for RAG workflows. Whether you need to summarize research papers, generate creative content, or assist customers in real-time, GPT-4 delivers top-tier results.
OpenAI’s GPT-4 is renowned for its unmatched generative quality. Its ability to understand nuanced queries and deliver contextually rich responses makes it ideal for RAG workflows.
For example, in healthcare, GPT-4 can retrieve patient data and generate precise treatment recommendations based on the latest research. In customer service, it powers intelligent bots that resolve complex issues effectively.

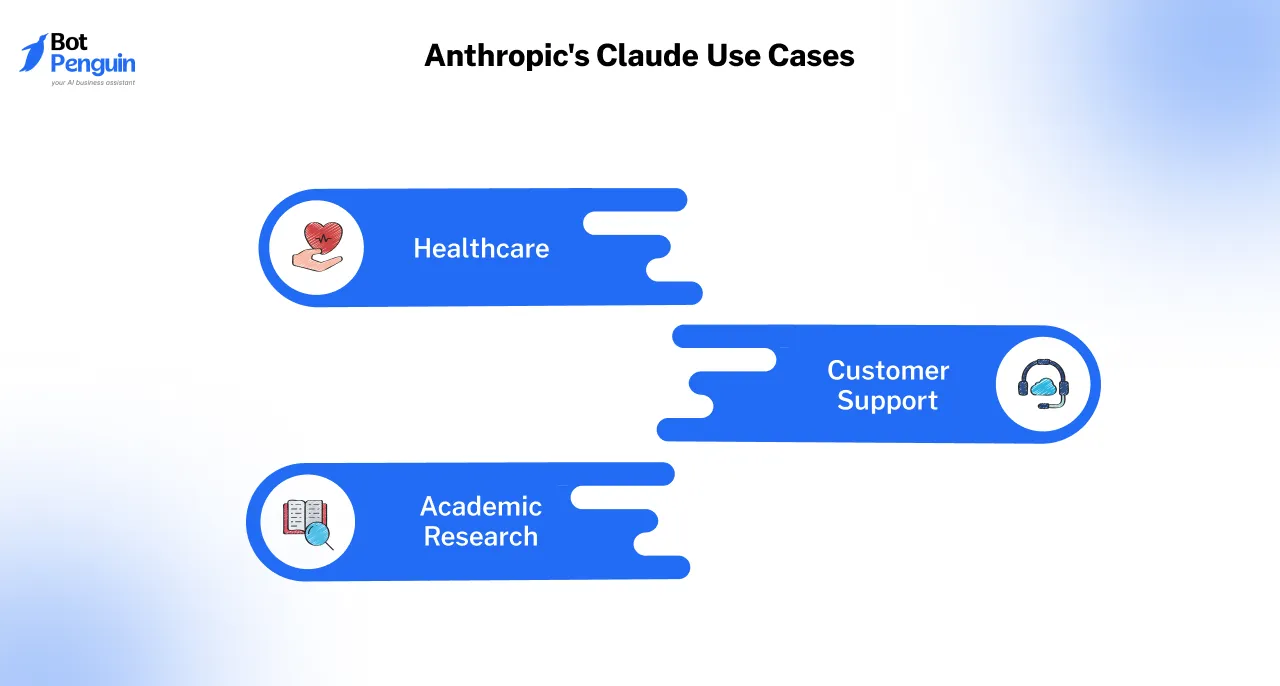
Anthropic’s Claude is designed with a strong emphasis on ethical AI and safe usage. It is particularly well-suited for industries like healthcare, finance, and law, where trustworthiness and transparency are paramount.
Claude is less flashy than some competitors but excels in delivering accurate and reliable outputs for sensitive tasks. Its affordability and focus on precision make it a popular choice for cost-conscious organizations looking for the best LLM for RAG to ensure accurate and context-aware responses.
Anthropic's Claude is a powerful choice when it comes to retrieval-augmented tasks, particularly due to its emphasis on safety, ethical AI, and transparent decision-making.
This makes it an excellent choice for industries where misinformation or bias can have severe consequences. For instance, in financial advisory, Claude ensures that recommendations are accurate, transparent, and unbiased.

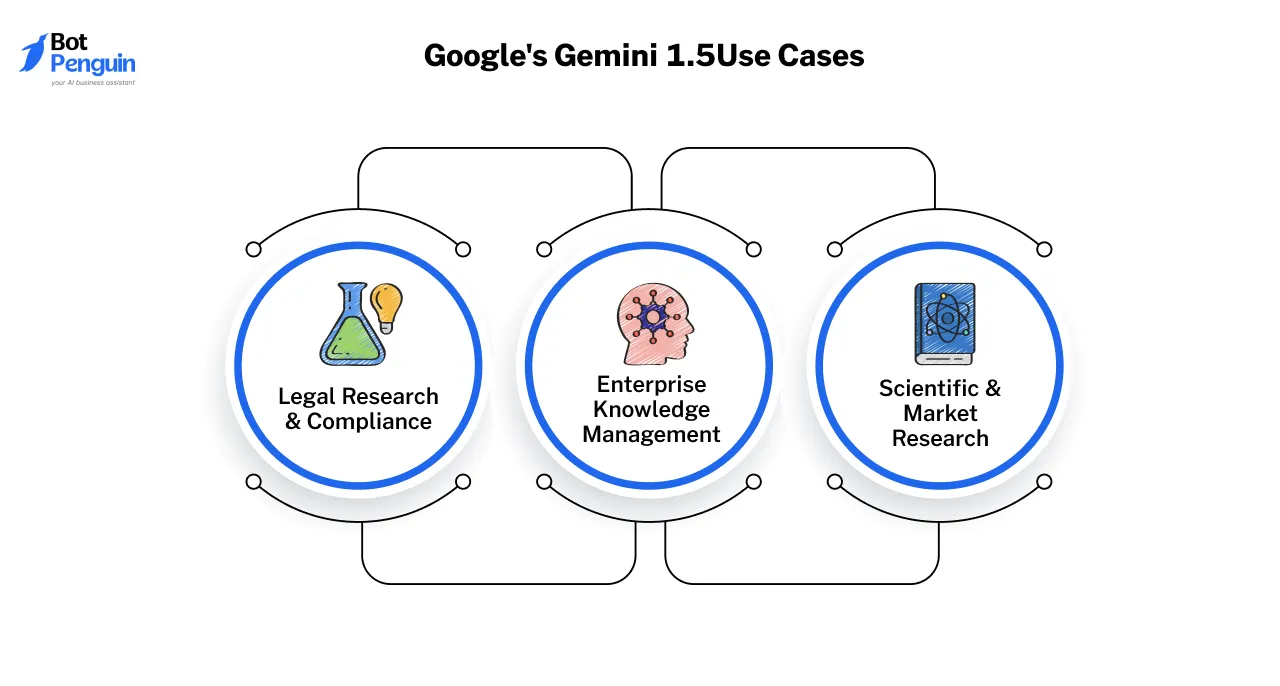
Google’s Gemini 1.5 is a powerful long-context language model designed for retrieval-augmented tasks.
With one of the longest context windows in LLMs, it can process vast amounts of information in a single prompt, making it a top choice for RAG implementations.
Gemini 1.5 Pro & Ultra outperform older models by handling long-context retrieval seamlessly, reducing response fragmentation, and improving knowledge synthesis.
This makes Gemini 1.5 particularly effective for industries that rely on processing large datasets, such as legal research, enterprise knowledge management, and scientific research.
However, its premium computational requirements make it more suitable for enterprises with the infrastructure to fully use its capabilities.
Google’s Gemini 1.5 is widely considered the best LLM for RAG due to its ability to retrieve, process, and generate highly contextual responses from large datasets in a single pass.
Unlike older models, it excels at long-context retrieval, making it ideal for applications that require accurate information synthesis across extensive documents.
Cohere offers a unique approach with a focus on fine-tuning and domain-specific optimization. This model is a great fit for businesses with specialized needs, such as personalized marketing, customer support, or niche knowledge bases.
Its flexible pricing structure and ease of integration make it an attractive choice for small to medium-sized enterprises.
While it may not rival GPT-4 in generative depth, Cohere excels in delivering tailored solutions and can be considered the best LLM for RAG when it comes to domain-specific applications.
Cohere’s specialization in domain-specific optimization makes it highly effective for Retrieval-Augmented Generation (RAG) tasks, particularly where personalized responses and precise knowledge retrieval are critical.
For example, in the marketing industry, Cohere can generate ad copy based on real-time customer behavior data. Its emphasis on fine-tuning makes it particularly effective for businesses with niche requirements.
Meta’s Llama remains a strong contender in the open-source AI space, offering flexibility and customization for Retrieval-Augmented Generation (RAG) tasks.
However, Llama 2 (4K tokens) does not support Long-Context RAG (LCR), making it less suitable for applications requiring extensive retrieval.
For businesses looking for the best LLM for RAG in the open-source category, Mistral 7B and Mixtral 8x7B have emerged as superior alternatives. These models outperform Llama 2 in retrieval efficiency, making them ideal for complex data-heavy applications.
If long-context retrieval is required, integrating Llama 2 or Mistral 7B with an external memory store like FAISS, ChromaDB, or Weaviate is necessary, while Mixtral 8x7B (32K tokens) supports longer retrieval natively.
Meta’s Llama, along with Mistral 7B and Mixtral 8x7B, is among the most effective open-source solutions for retrieval-based AI applications.
Their fine-tuning flexibility and efficient retrieval mechanisms allow businesses to tailor them for domain-specific RAG implementations.
Unlike proprietary models, these open-source LLMs can be deployed without licensing restrictions, giving startups, academic institutions, and enterprises full control over data processing and retrieval workflows.
When integrated with vector databases, they significantly improve retrieval speed and accuracy, making them ideal for handling vast amounts of structured and unstructured data.
Each of these models brings unique strengths to Retrieval-Augmented Generation (RAG), catering to different needs based on scalability, cost, and specialization. Also, businesses looking for more specialized AI solutions for customer interactions can consider platforms like BotPenguin.
While BotPenguin is not specifically built as the best LLM for RAG, it is an advanced conversational AI platform that can be enhanced with Retrieval-Augmented Generation (RAG) by integrating a vector database LLM like GPT-4. This allows businesses to use contextual retrieval for more accurate and dynamic responses.
By selecting the best LLM for RAG, businesses can enhance automation, improve knowledge retrieval, and drive smarter decision-making across various industries.
The actual applications of RAG demonstrate how combining retrieval systems and generative AI can transform workflows.
Whether it is customer support, knowledge management, or search engines, the best LLM for RAG plays a pivotal role in achieving accuracy and efficiency. Here are a few case studies below:
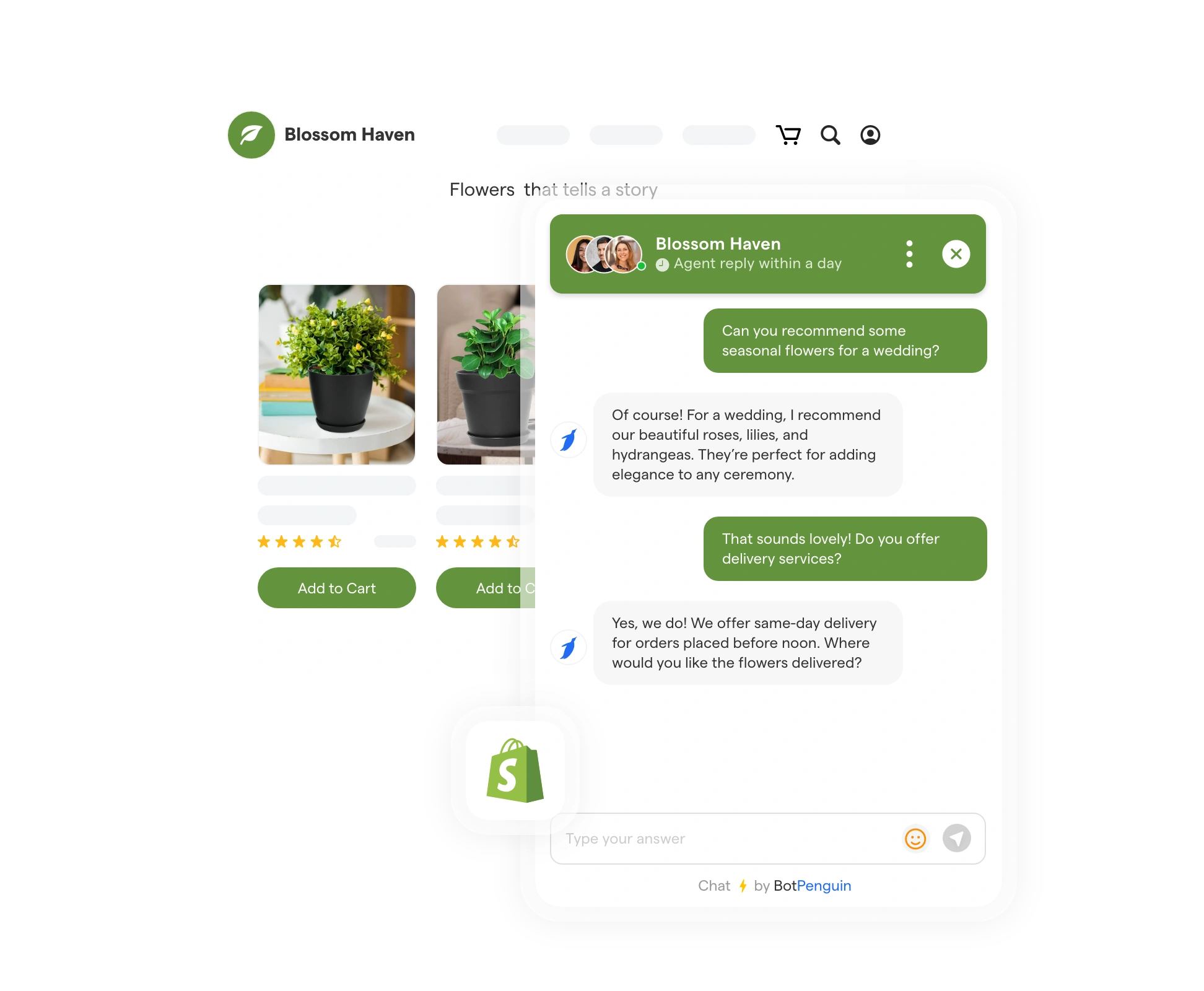
In the e-commerce industry, handling high volumes of customer queries efficiently is a constant challenge, especially during peak seasons.
Let us explore how Shopify used GPT-4 to streamline their customer support to improve overall service quality.
Managing and accessing huge amounts of data is crucial for large organizations like Siemens. This case study explores how Siemens used Google PaLM to enhance their knowledge management tools.
Researchers may find it time-consuming to find and summarize relevant studies from the vast amount of academic research available. Let us find out how ArXiv implemented Llama to boost their search engine capabilities.
These case studies highlight how businesses and organizations use retrieval-augmented generation (RAG) with advanced language models to improve efficiency, streamline workflows, and enhance user experiences. By integrating the best LLM for RAG, companies can ensure higher accuracy, better automation, and smarter decision-making across various domains.
Successfully implementing RAG requires more than just picking the best LLM for RAG. You need to focus on seamless integration, data quality, and ongoing optimization.
These best practices will help ensure your RAG workflows perform effectively.
It is vital to constantly update the data sources used by the RAG model to ensure data quality. You can maintain a schedule and refresh data regularly so that the model can consistently access the latest information.
High-quality data ensures the best LLM models for RAG produce accurate, contextually relevant outputs.
You have to retrain the RAG model with fresh datasets to help it adapt to changes in language usage and information.
Implement metrics to check if the responses of the model are accurate and relevant. Regular monitoring ensures the best LLM model for RAG continues delivering optimal results.
You should design your RAG system architecture to efficiently handle growing data volume and user load over time.
Ensure that your computational infrastructure, such as cloud-based solutions, has the necessary resources to support intensive data processing, especially when integrating the best LLM for RAG to maximize performance and scalability.
Choose an LLM that aligns with your infrastructure. Use APIs or plugins to simplify integration. For open-source projects, models like Llama are great options.
The best open source LLM for RAG offers flexibility, especially in niche applications.
For troubleshooting, use active communities and detailed documentation. Open-source models like Llama thrive on community support, making them ideal for experimentation and troubleshooting.
Access to a strong developer community can be a key advantage when working with the best LLM for RAG, ensuring smoother implementation and faster problem-solving.
By following these best practices, you can optimize your RAG implementation for accuracy, efficiency, and scalability, ensuring that you get the most out of the best LLM for RAG in your specific use case.
The best LLM for RAG implementations can transform workflows, improve efficiency, and deliver outstanding results across industries.
By choosing the right model, ensuring data quality, and following best practices, businesses can unlock the full potential of the Retrieval-Augmented Generation.
For a seamless RAG solution, consider BotPenguin, an AI agent and a no-code AI chatbot maker platform. BotPenguin enables businesses to build intelligent chatbots that use advanced LLMs for accurate, contextual responses.
From enhancing customer support to streamlining internal operations, BotPenguin makes AI accessible and effective for businesses of all sizes. It is a simple yet powerful way to harness the benefits of RAG without technical complexity.
The best LLM for RAG depends on your specific needs. If you require top-tier performance and scalability, GPT-4 is a great option.
For cost-effective, open-source flexibility, Meta’s Llama is a solid choice. Consider factors like accuracy, integration ease, and budget when selecting a model.
The best LLM for RAG ensures accurate context understanding, seamless integration, and high-quality outputs.
Poor model choice can result in irrelevant responses, compromising the effectiveness of your RAG workflow.
RAG allows your model to fetch real-time information, making it ideal for dynamic fields like news, research, and customer support.
Fine-tuning, on the other hand, works best for stable domains where deep contextual understanding is needed. The best LLM for RAG will balance both approaches based on your requirements.
Yes. Open-source models like Meta’s Llama are excellent choices for RAG implementations. They offer flexibility, customization, and strong community support. If you're looking for the best LLM for RAG while keeping costs low, open-source models are worth considering.
Yes, BotPenguin enables businesses to build intelligent chatbots using RAG, simplifying integration without coding.
It is a cost-effective way to use AI for improved customer service and operational efficiency. By integrating the best LLM for RAG, businesses can ensure their chatbots deliver accurate, context-aware responses while maintaining seamless automation.
Subscribe to Our Newsletter
Get the latest business insights straight into your inbox.
Checkout our related blogs you will love.
Updated at May 8, 2026
13 min to read
.webp)
Updated at May 5, 2026
7 min to read

Updated at Jul 3, 2026
15 min to read

Updated at Jul 3, 2026
10 min to read

Updated at Jul 1, 2026
16 min to read
Updated at Jun 30, 2026
3 min to read
Table of Contents