Introduction
Deep learning is simple. Just throw data at a neural net and watch the magic happen, right?
Neglect critical steps like data preparation or hyperparameter tuning, and your model may never mature into a reliable assistant.
This guide outlines 13 best practices for nurturing deep learning models using TensorFlow. While powerful out of the box, TensorFlow offers advanced customization tailored to your model’s needs.
Follow these tips not as commandments etched in stone, but as helpful suggestions from a fellow traveler. The path to deep learning is paved with insight rather than instructions.
Gain an intuitive grasp of vital concepts like regularization, optimization, and architectures. Learn when to guide your model and when to let it wander. While missteps are inevitable, use errors as lessons rather than punishments.
Embrace the creativity and experimentation at the heart of model-building. With thoughtful tuning guided by experience, your model will blossom.
Soon, thanks to the care you provided in its developmental years, you’ll have a mature model ready to take on new challenges.
Data Preparation
Preparing the data before training a deep learning model is essential to ensuring optimal performance and accurate results.
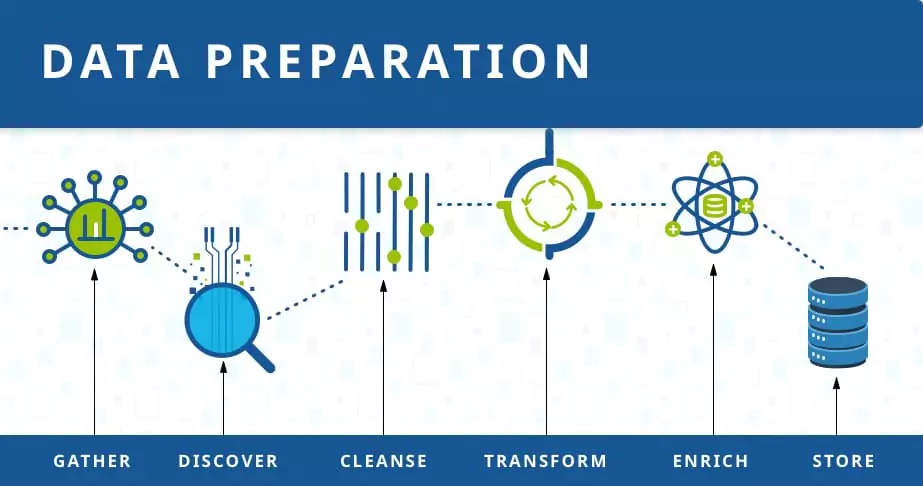
TensorFlow provides various tools and techniques for cleaning, preprocessing, and augmenting data.
Cleaning and Preprocessing Data
Data preprocessing is a crucial step to remove noise, outliers, and inconsistencies in the data.
TensorFlow's data preprocessing capabilities allow users to standardize, normalize, and transform data, ensuring that it aligns with the requirements of the deep learning model.
Feature Engineering with TensorFlow
Feature engineering involves creating new features or transforming existing ones to enhance the predictive power of the model.
TensorFlow provides a range of operations, such as feature scaling, one-hot encoding, and text embedding, to help users extract meaningful features from raw data.
Choosing the Right Model Architecture
The choice of model architecture significantly impacts the performance of a deep learning model. TensorFlow offers various pre-built architectures and flexible options for designing customized models.
Pre-built Model Architectures in TensorFlow
TensorFlow includes pre-built model architectures such as convolutional neural networks (CNNs) for image classification, recurrent neural networks (RNNs) for sequential data, and transformers for natural language processing.
These ready-to-use models can be quickly implemented and fine-tuned for specific tasks.
Customizing Model Architecture with TensorFlow
TensorFlow allows users to design and customize their model architecture using its flexible framework.
By defining and connecting layers, users can create deep learning model that suit their specific needs.
This flexibility enables the incorporation of domain-specific knowledge and experimentation with different architectures.
Regularization Techniques
Overfitting is a common challenge in deep learning models, leading to poor generalization. TensorFlow deep learning offers various regularization techniques to mitigate overfitting and improve model performance.
Dropout Regularization
Dropout is a regularization technique that randomly drops out a fraction of neurons during training, preventing the model from relying too heavily on any single neuron.
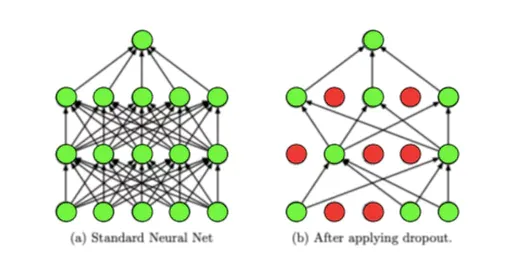
TensorFlow provides easy-to-use dropout layers that can be added to a model to enhance its generalization capabilities.
L1 and L2 Regularization
L1 and L2 regularization methods add penalties to the loss function to limit the magnitude of the model's weights.
By discouraging large weights, these techniques reduce the risk of overfitting. TensorFlow offers built-in regularization functions that can be added to the model's layers.
Hyperparameter Tuning
Hyperparameters are parameters set before training and affect the learning process of a model. They significantly impact the model's performance but cannot be learned from the data.
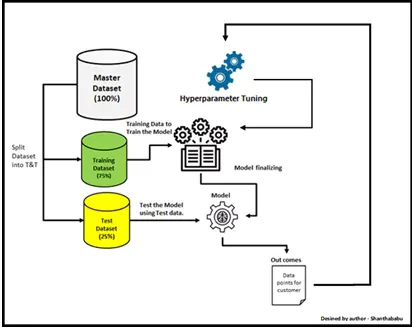
TensorFlow provides tools and techniques for tuning hyperparameters to optimize model performance.
Importance of Hyperparameter Tuning
Hyperparameter tuning is crucial to maximizing a deep learning model's performance. Users can fine-tune their models for optimal results by systematic and intelligent exploration of different hyperparameter values.
Grid Search and Random Search
Grid search and random search are popular techniques in hyperparameter tuning. TensorFlow provides tools to implement these search methods efficiently.
Grid search exhaustively evaluates all possible combinations of hyperparameter values, while random search randomly selects combinations to explore.
Optimizers in TensorFlow
Optimizers play a vital role in deep learning models by determining how the model's weights are updated during training. TensorFlow offers a variety of optimizers to efficiently minimize the loss function and improve model convergence.
Gradient Descent Optimizer
In deep learning, gradient descent is a popular optimization technique. Stochastic gradient descent (SGD), mini-batch SGD, and batch SGD are three types of gradient descent optimizers that TensorFlow deep learning offers.
These optimizers modify the model's weights based on the gradients of the reduction function for the weights.
Adaptive Learning Rate Optimizers
Adaptive learning rate optimizers, such as Adam and Adagrad, adjust the learning rate dynamically during training.
These optimizers adaptively update the learning rate based on the gradient's magnitude, enhancing the optimization process and improving model convergence.
Dropout and Batch Normalization
Dropout and batch normalization are techniques for improving the performance and generalization ability of deep learning models. TensorFlow provides built-in functions for seamlessly implementing these techniques.
Dropout for Regularization
Dropout, introduced earlier as a regularization technique, can also reduce overfitting by randomly dropping neurons during training.
By preventing reliance on specific neurons, dropout ensures that the model learns more robust and generalizable features.
Batch Normalization for Faster Training
Batch normalization is a technique that normalizes the outputs of neurons in a layer by adjusting and scaling them. It speeds up training by reducing internal covariate shifts and makes the optimization process more stable.
TensorFlow's batch normalization layers make it effortless to implement this technique in a deep learning model.
Transfer Learning
Transfer learning leverages knowledge learned from pre-trained models on similar tasks and applies it to new problems.
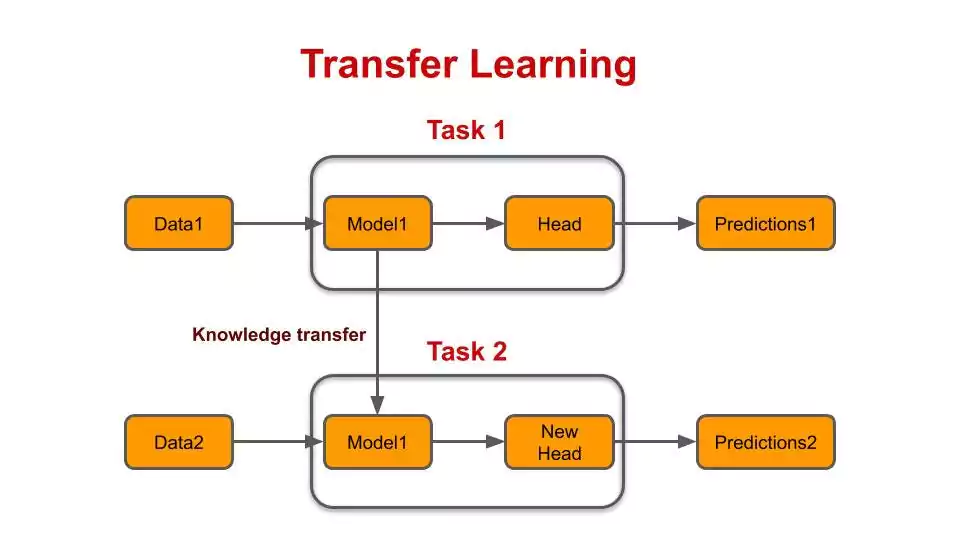
TensorFlow supports transfer learning, allowing users to benefit from pre-existing models in their deep learning projects.
Leveraging Pre-trained Models in TensorFlow
TensorFlow deep learning provides access to various pre-trained models such as VGG16, ResNet, and BERT.
These models are trained on large-scale datasets and have already learned meaningful representations of visual or textual features.
Users can fine-tune these pre-trained models by adding their task-specific layers.
Benefits of Transfer Learning
Transfer learning offers several benefits in deep learning. It can save significant training time and computational resources by starting from an already initialized network.
It also improves model performance, especially when the dataset for the target task is limited.
Data Augmentation
A training dataset's size and variety can be artificially increased using data augmentation techniques.
TensorFlow lets users create fresh samples that enhance the resilience and performance of their deep-learning models by applying different transformations to the available data.
Augmenting Image Data in TensorFlow
TensorFlow provides a rich set of image transformation functions, including rotations, translations, flips, and zooms.
By applying these transformations to the training images, users can augment the dataset and expose the model to a wider range of data variations.
Text Data Augmentation Techniques
Besides image data augmentation, TensorFlow deep learning offers techniques for augmenting text data. These techniques include word swapping, insertion, and deletion, as well as sentence-level transformations. By applying these transformations, users can generate additional training examples and enhance text-based deep learning models.
Early Stopping
Early stopping is a technique for preventing overfitting in deep learning models.
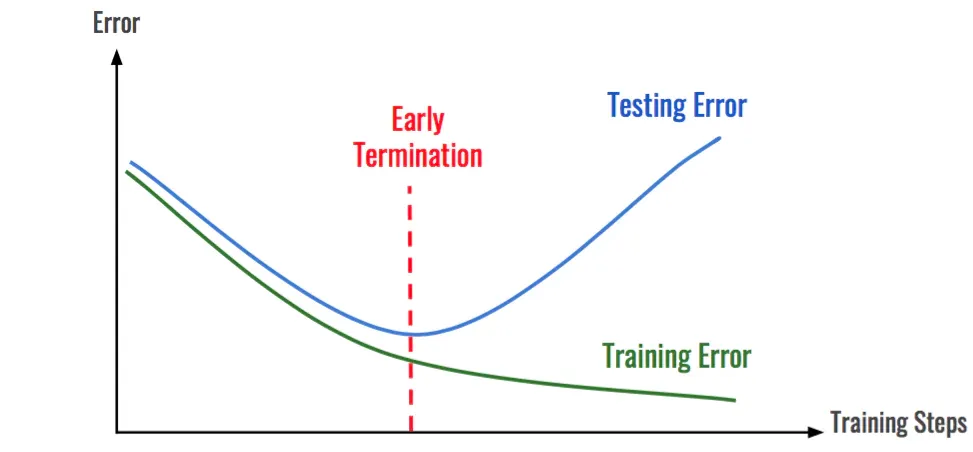
TensorFlow simplifies the implementation of early stopping, allowing users to monitor the model's performance during training and stop the training process when overfitting occurs.
Monitoring Validation Loss
To implement early stopping, TensorFlow deep learning provides callbacks that allow users to monitor the validation loss during training.
When the validation loss increases consistently, the training process can be stopped to prevent further overfitting.
Benefits of Early Stopping
Early stopping prevents deep-learning models from memorizing the training data and helps them achieve better generalization on unseen data.
By stopping the training process at the optimal point, users can save time and resources while still achieving good model performance.
Model Ensembling
Model ensembling combines predictions from multiple deep-learning models to improve overall performance. TensorFlow offers tools and techniques for implementing model ensembling easily.
Combining Deep Learning Models
TensorFlow allows users to train multiple deep learning models with different architectures, hyperparameters, or training data and then combine their predictions.
This ensemble approach often leads to better performance by leveraging the diversity and complementary strengths of multiple models.
Techniques for Model Ensembling
Various techniques, such as majority voting, weighted averaging, and stacking, can be used for model ensembling.
TensorFlow deep-learning provides functions and libraries to implement these techniques and generate ensemble predictions.
Advanced Activation Functions
Activation functions are crucial in the non-linear mapping of inputs to outputs in deep learning models. TensorFlow offers a range of advanced activation functions that can enhance the model's ability to learn complex patterns and improve performance.
ReLU and its Variants
ReLU (Rectified Linear Unit) is the most commonly used activation function in deep learning. TensorFlow provides various variants of ReLU, such as Leaky ReLU and Parametric ReLU, which address some limitations of the original ReLU function.
Other Advanced Activation Functions
TensorFlow also offers advanced activation functions, such as sigmoid, tanh, and exponential linear units (ELUs). These functions can be used in specific scenarios to improve the model's performance and ensure better convergence.
Visualization Techniques
Visualization is essential to understanding and interpreting deep learning models. TensorFlow provides various tools and techniques for visualizing the model architecture, intermediate outputs, and performance metrics.
Visualizing Model Architecture
TensorFlow deep learning allows users to visualize the model architecture using tools like TensorBoard. This visualization provides a clear understanding of the model's structure, including the number of layers, their connections, and the data flow.
Visualizing Intermediate Outputs
Users can also visualize the intermediate outputs of deep learning models using TensorFlow. By observing these intermediate representations, it becomes easier to understand how the model processes and learns from the input data.
Debugging and Error Analysis
Debugging and error analysis are essential for improving deep learning models' performance and troubleshooting issues.
TensorFlow offers several debugging tools and techniques to diagnose and fix common errors.
Debugging Deep Learning Models
TensorFlow's debugging tools, such as tf. debugging.assert*, tf.debugging.check_numerics, and tf.debugging.enable_check_numerics, help identify and address issues such as NaN values, shape mismatches, and tensor computations.
Error Analysis and Metrics
TensorFlow provides functions for computing various performance metrics, such as accuracy, precision, recall, and F1 score.
These metrics enable users to analyze the model's performance, identify areas of improvement, and make informed decisions.
Conclusion
So there you have it - 13 proven ways to squeeze every last drop of performance out of your deep learning models using TensorFlow.
From data preparation to debugging, we've covered all the bases. Don't keep these tips to yourself! Share this guide with your team to get everyone onboard.
Together, let's build better AI and solve real-world problems.
The future is now in our hands. Will you lead the charge towards real progress? Or lag behind while others pave the way? I hope you'll join me on this journey.
Let's get out there and show the world what AI can really achieve in the right hands! The time for talk is over. Now we build.
Frequently Asked Questions (FAQS)
How can TensorFlow help improve deep learning models?
TensorFlow deep learning provides tools and techniques for data preprocessing, model architecture customization, regularization, hyperparameter tuning, and more, enabling users to enhance their deep learning models' performance.
What are some data preparation techniques in TensorFlow?
TensorFlow offers data cleaning, preprocessing, and feature engineering capabilities that allow users to standardize, normalize, transform, and extract meaningful features from raw data, optimizing it for deep learning models.
How can I choose the right model architecture with TensorFlow?
TensorFlow provides pre-built model architectures like CNNs and RNNs that can be fine-tuned for specific tasks. Additionally, users can customize their architectures using TensorFlow's flexible framework to meet their specific needs.
What regularization techniques are available in TensorFlow?
TensorFlow offers regularization techniques like dropout and L1/L2 regularization to mitigate overfitting in deep learning models. These techniques promote generalization and improve model performance by preventing over-reliance on specific neurons or limiting the magnitude of weights.
How can I leverage transfer learning in TensorFlow?
With TensorFlow, users can benefit from pre-trained models like VGG16, ResNet, and BERT. By fine-tuning these models and incorporating task-specific layers, users can leverage the learned representations and achieve better performance, especially when data is limited.