What are the Key Differences between Custom LLM vs Generic LLM
Top 7 Business Use Cases for Custom LLM Development
How to Build a Custom LLM for Business Step by Step
What are the Most Common Custom LLM Development Mistakes?
Building a Custom LLM Is Only Half the Battle
Frequently Asked Questions (FAQS)
Share
Link copied
TL;DR
Custom LLM development means training a model on your own data so it outperforms generic AI on your specific tasks
The right approach for most SMBs is fine-tuning an open-source model like Llama 3 or Mistral using LoRA, not training from scratch
Data quality and use case clarity determine 80% of your outcome, not model size or architecture
Budget 7 to 18 weeks and $5K to $100K depending on your approach, with data preparation being the most common cause of delays
Once your model is trained, BotPenguin deploys it across WhatsApp, your website, Instagram, and every other customer channel without separate integrations
Most businesses are running on borrowed intelligence. They plug into ChatGPT, feed it generic prompts, and wonder why the outputs feel off-brand or just plain wrong. The fix isn't a better prompt. It's a model built for your business.
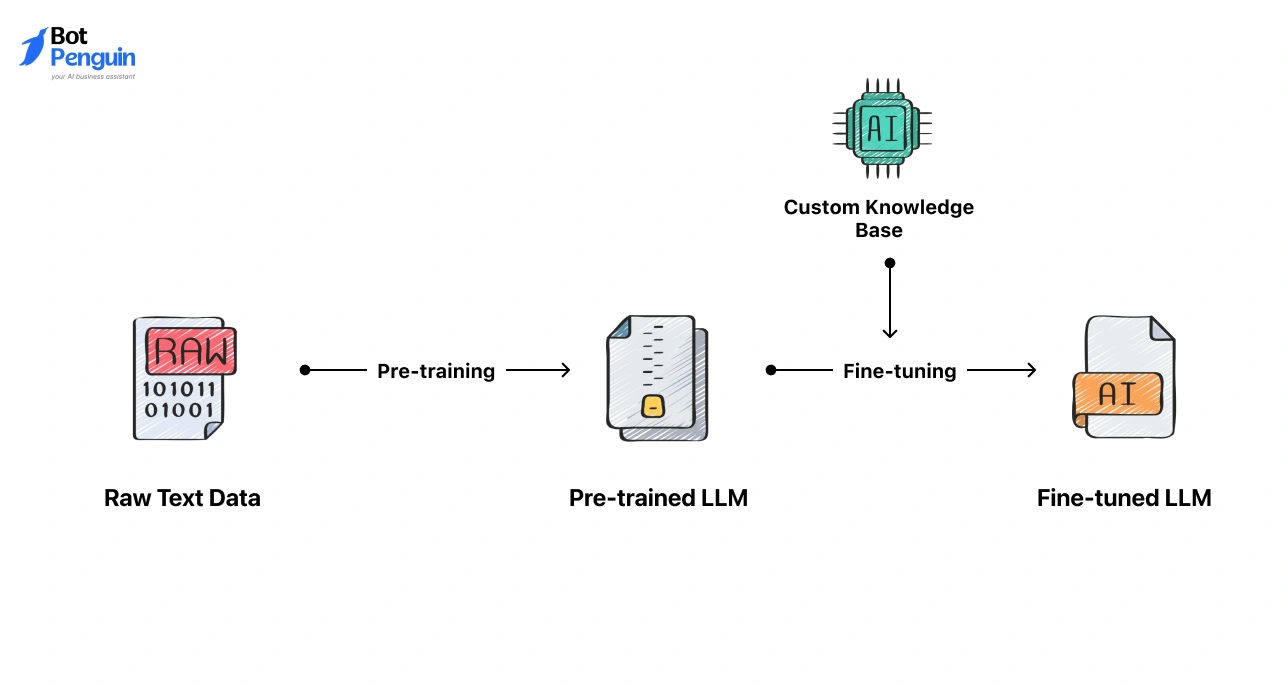
Custom LLM development is the process of training or adapting a large language model on your own data, so it speaks your industry's language, follows your rules, and delivers results you can trust.
This guide covers the complete 8-step process: from defining objectives and selecting a base model, to fine-tuning, deployment, and monitoring.
Let's build.
What is Custom LLM Development?
Custom LLM development is the process of taking a large language model, either an existing open-source model or one you build from scratch, and training it on your business-specific data. Hence, it performs your specific tasks better than any general-purpose AI can.
A generic LLM like GPT-4 has read the entire internet. A custom LLM has read the entire internet and spent weeks absorbing your internal documentation, customer interaction history, product knowledge base, and compliance guidelines. The result is a model that's sharper, more accurate, and fully aligned with how your business actually operates.
What are the Key Differences between Custom LLM vs Generic LLM
Basis
Generic LLM
Custom LLM
Training data
Public internet
Your proprietary business data
Domain accuracy
Broad but shallow
Narrow and deep
Brand voice
Generic
Matches your tone and terminology
Compliance
Not guaranteed
Configurable to your regulations
Cost over time
Ongoing API fees
Higher upfront, lower long-term
Data privacy
Data sent to third party
Can be fully self-hosted
Custom LLM vs Fine-Tuning vs RAG
This is the decision most CTOs get wrong because they treat "custom LLM" as one single thing. It isn't. There are three distinct approaches, each with different costs, timelines, and use cases.
Approach
What It Does
Best For
Cost
Timeline
Fine-Tuning
Retrains a base model on your data
Domain-specific language, tone, tasks
$5K–$50K
4–8 weeks
RAG
Connects LLM to your live knowledge base at query time
Frequently updated content
$2K–$20K
1–4 weeks
Training from Scratch
Builds a new model on custom architecture
Highly specialized enterprise domains
$500K+
6–18 months
Hybrid (Fine-tune + RAG)
Fine-tunes for style, RAG for real-time data
Best overall for most businesses
$20K–$80K
6–12 weeks
When to fine-tune
Your domain has unique terminology, tone, or workflows that a generic model consistently gets wrong. Examples: legal, healthcare, finance, or any business with a large proprietary knowledge corpus.
When to use RAG
Your information changes frequently, product catalogs, pricing, internal policies, and you need the model to always pull the latest version without retraining.
When to build from scratch
Rarely. Only justified for organizations with genuinely novel domains, classified data environments, or research-grade requirements. For 95% of SMBs and mid-market companies, fine-tuning an open-source model delivers better ROI than building from scratch.
The smartest starting point for most businesses: Fine-tune a Llama 3 or Mistral 7B model using LoRA on your domain data, then layer RAG on top for real-time knowledge retrieval. You get deep domain accuracy plus always-current outputs — at a fraction of what training from scratch costs.
Connect LLM to WhatsApp, Web & More
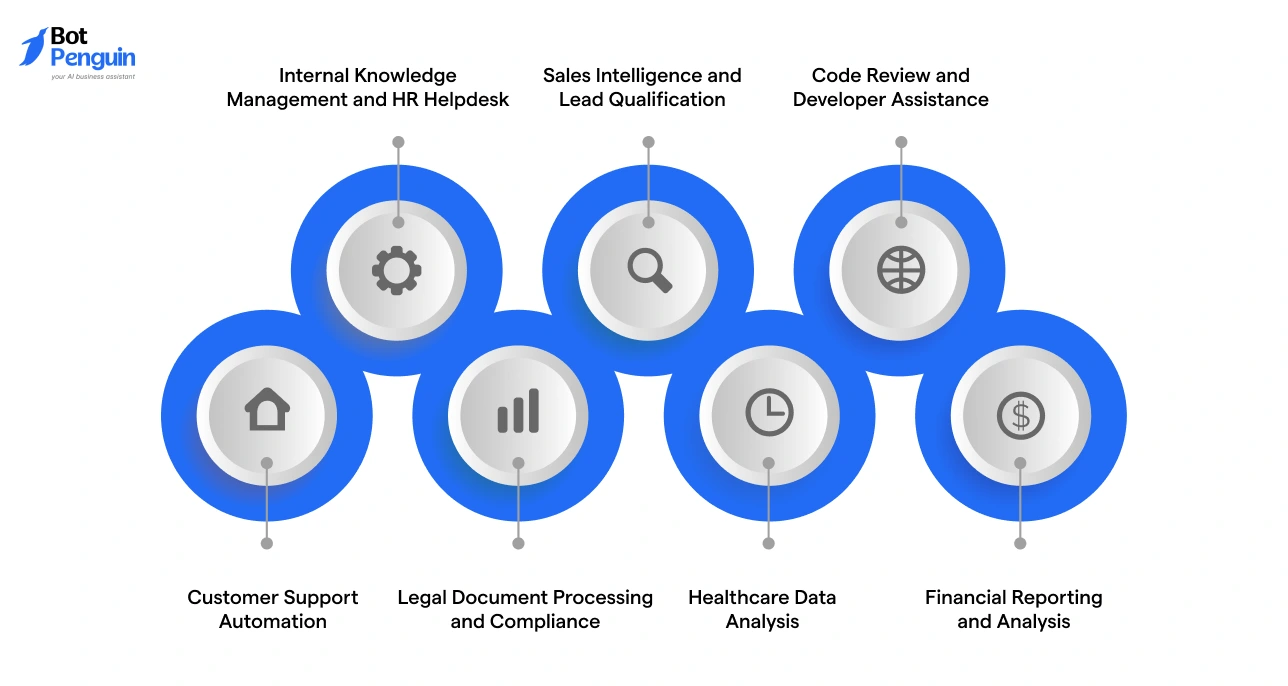
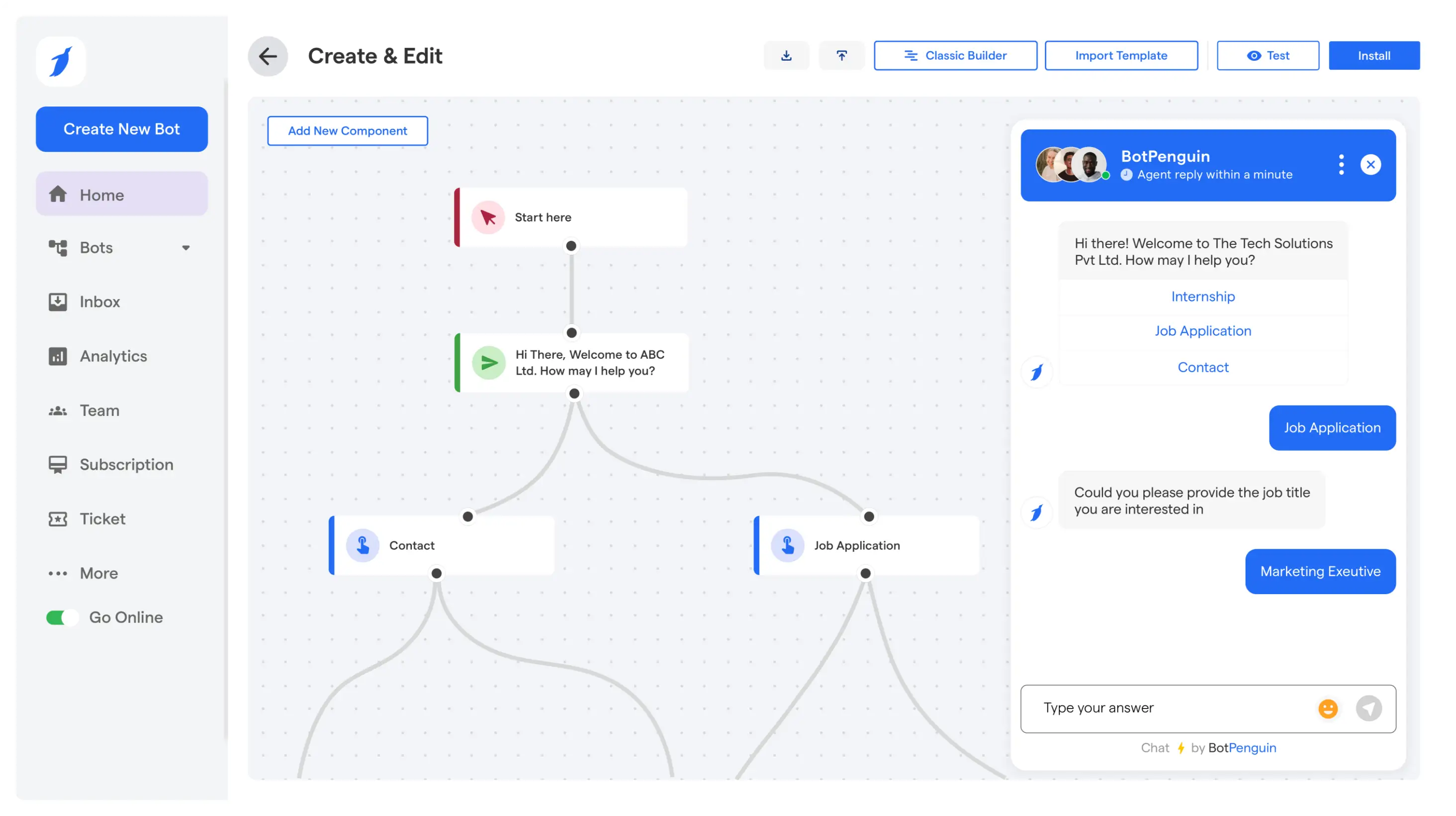
Top 7 Business Use Cases for Custom LLM Development
Custom LLMs deliver the highest ROI when deployed on tasks that are high-volume, language-heavy, and require domain-specific accuracy.
Here are the seven use cases where businesses are seeing the most measurable impact.
Customer Support Automation
Generic chatbots fail because they don't know your product.
A custom LLM trained on your actual support tickets, resolution history, and product documentation handles tier-1 queries with accuracy that off-the-shelf bots simply cannot match.
The result is faster resolution times, fewer escalations to human agents, and consistent answers across every channel without sounding like a bot reading from a script.
Example: An e-commerce company fine-tuned a Llama 3 model on 18 months of support tickets. Tier-1 resolution rate went from 42% to 79% in 60 days, cutting support headcount cost by 35%.
Internal Knowledge Management and HR Helpdesk
Most companies have thousands of pages of internal documentation that nobody reads because nobody can find the right answer fast enough. A custom LLM turns your SOPs, HR policies, and onboarding manuals into a conversational interface.
Employees ask questions in plain language and get precise, policy-compliant answers instantly.
No more digging through shared drives or waiting two days for HR to respond to a PTO query.
Example: A 400-person SaaS company deployed an internal LLM on their Confluence and Notion docs. Average time-to-answer for HR queries dropped from 48 hours to under 30 seconds.
Legal Document Processing and Compliance
Reviewing contracts, extracting clauses, and flagging risk are tasks that eat hundreds of billable hours every month. A custom LLM trained on your legal corpus and jurisdiction-specific language dramatically outperforms general models on document analysis accuracy.
Common applications include NDA review, compliance clause extraction, regulatory filing summarization, and vendor contract risk scoring.
Example: A mid-market fintech used a fine-tuned legal LLM to review vendor contracts. What previously took a paralegal 4 hours per contract was reduced to a 12-minute AI review with human sign-off.
Sales Intelligence and Lead Qualification
A custom LLM trained on your CRM data, call transcripts, and closed-won patterns can analyze inbound leads, score them against your ideal customer profile, and suggest next-best actions without any manual input from your sales team.
The output is not just a faster qualification. It is a qualification that gets smarter over time as more data feeds back into the model.
Example: A B2B software company trained a custom LLM on 3 years of CRM notes and call recordings. Lead-to-meeting conversion rate improved by 28% within the first quarter of deployment.
Healthcare Data Analysis
Clinical documentation, patient intake forms, and discharge summaries generate enormous volumes of language data that staff spend hours processing manually.
Custom LLMs built for healthcare can summarize records, cross-reference symptoms, and surface relevant treatment history in seconds.
These models can be deployed on-premise or in a HIPAA-compliant private cloud, keeping patient data entirely within your environment.
Example: A regional hospital network deployed a custom LLM to summarize inpatient discharge notes. Physicians saved an average of 45 minutes per shift on documentation, with a reported accuracy rate of 94% on clinical detail extraction.
Code Review and Developer Assistance
A coding model fine-tuned on your actual codebase, your architecture patterns, style guide, and naming conventions is meaningfully more useful than a generic coding assistant for your specific engineering context.
It reduces review cycle time, flags violations of your internal standards, and cuts onboarding time for new engineers who need to understand an unfamiliar codebase quickly.
Example: A Series B startup fine-tuned Code Llama on their proprietary backend codebase. New engineer onboarding time dropped from 3 weeks to 9 days, and PR review cycles shortened by 40%.
Financial Reporting and Analysis
Earnings call summarization, regulatory filing analysis, portfolio commentary, and risk narrative generation are tasks that follow predictable patterns yet consume disproportionate time from senior finance staff.
A custom LLM trained on your firm's writing style and financial data corpus automates the first draft of these outputs with the accuracy and tone your compliance team will approve.
Example: An asset management firm trained a custom LLM on 5 years of internal investment memos. The model now generates first-draft quarterly commentary in under 3 minutes, a task that previously took an analyst half a day.
Now that you know where custom LLMs deliver the most value, here is exactly how to build one.
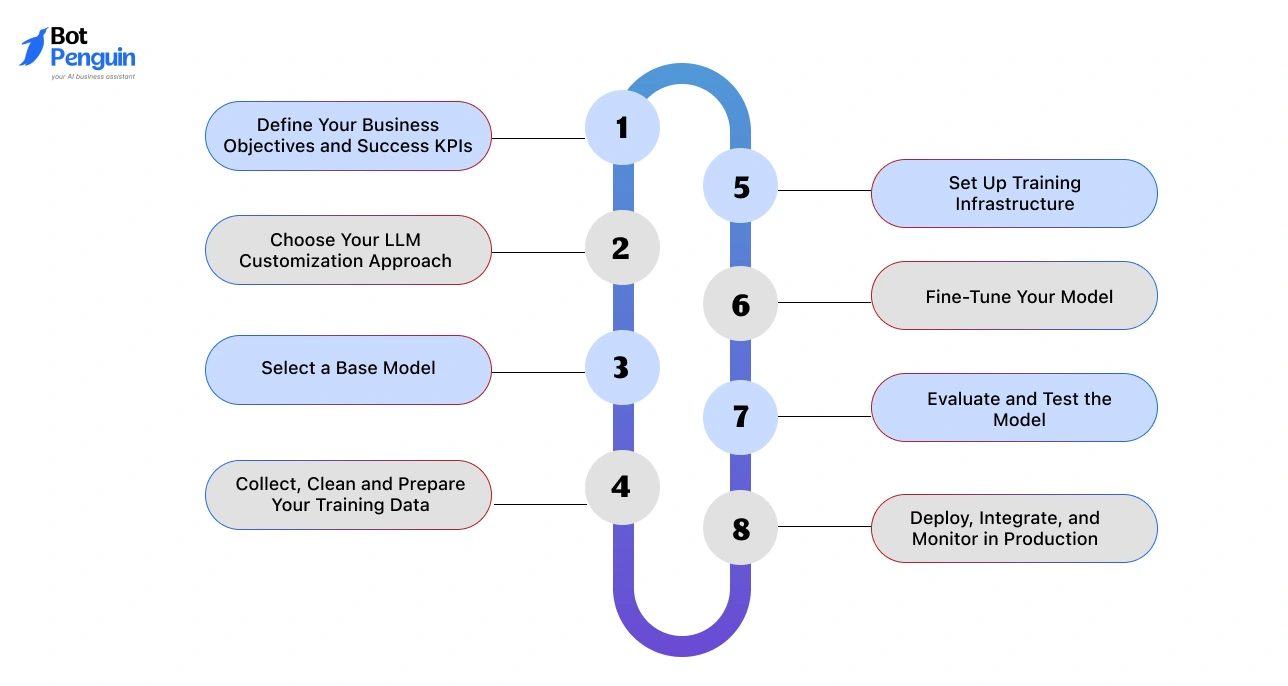
How to Build a Custom LLM for Business Step by Step
This is the full custom LLM development process used by engineering teams across SMBs and enterprise companies. Follow the steps in order. Skipping ahead is the most common reason projects fail.
Step 1: Define Your Business Objectives and Success KPIs
Before touching data or infrastructure, answer three questions with specificity. What exact task will the LLM own? Who are the end users? How will you measure success?
"Improve customer experience" is not an objective. "Automatically resolve tier-1 support tickets across 12 defined query categories without human escalation" is. The more specific your objective, the more precisely you can scope your training data and the faster you hit your KPI.
Pick one primary KPI before you start. Reduction in support ticket volume, hours saved per employee per week, or improvement in lead qualification rate are all measurable. "The model seems better" is not.
Example: A property management company defined its objective down to 12 specific query categories. That specificity let their team scope training data precisely and hit their resolution rate KPI within the first deployment.
Step 2: Choose Your LLM Customization Approach
If your data changes frequently, use RAG. If your domain has unique language that generic models get wrong, fine-tune. If you need both, use a hybrid approach.
If you are in a classified or genuinely novel domain with no comparable existing models, train from scratch. That last option applies to fewer than 5% of business use cases. Getting this decision right before you start saves weeks of rework. Most teams that end up rebuilding mid-project made the wrong approach choice at this stage.
Example: A cybersecurity firm planned to fine-tune on their threat intelligence database until they realized the data was updated hourly. Switching to RAG saved four weeks of unnecessary training work.
Step 3: Select a Base Model
Your base model determines your performance ceiling, deployment flexibility, and licensing obligations. For most SMBs in 2025, Llama 3 8B or Mistral 7B are the right starting points. Both are commercially licensed, self-hostable, and cost-efficient to fine-tune.
Choose Llama 3 70B if you need stronger reasoning and have the compute budget. Choose Mistral 7B if inference speed and cost are your primary constraints.
Avoid proprietary models like GPT-4 if data privacy is a requirement, since your data will pass through a third-party API.
Base Model
Parameters
License
Best For
Self-Hostable
Llama 3 (Meta)
8B / 70B / 405B
Custom (commercial OK)
General business applications
Yes
Mistral 7B
7B
Apache 2.0
Fast inference, cost-efficient deployments
Yes
Falcon 40B
40B
Apache 2.0
Complex reasoning tasks
Yes
GPT-4 (OpenAI)
Undisclosed
Proprietary
Highest accuracy, no self-hosting
No
Gemini Pro
Undisclosed
Proprietary
Multimodal, Google ecosystem
No
Example: A legal tech startup scoped their project around GPT-4 until compliance flagged that client contract data could not leave their private environment.
They switched to Llama 3 70B self-hosted on AWS and landed within 6% of GPT-4 performance at roughly one quarter of the ongoing cost.
Step 4: Collect, Clean,n and Prepare Your Training Data
Data quality is the single biggest predictor of custom LLM performance. A smaller, well-curated dataset consistently outperforms a large, noisy one.
Budget 20 to 30% of your total project timeline for this step alone because it almost always takes longer than expected.
Collect internal documentation, customer interaction data, domain-specific external text, and labeled question and answer pairs. Then run it through a four-step pipeline:
Filter: Exclude PII, toxic content, and off-topic data
Deduplicate: Use MinHash LSH to catch near-duplicates that cause overfitting
Tokenize: Format data into the instruction-input-output structure your base model expects
Example: A financial services company started with 200,000 internal documents. After cleaning and deduplication, 31,000 high-quality documents remained. The model trained on the cleaned set outperformed the full 200,000-document set on every benchmark.
Step 5: Set Up Training Infrastructure
Your infrastructure choice affects both cost and data privacy, so align it with your compliance requirements before provisioning anything.
Cloud GPU instances on AWS, GCP, or Azure work well for one-time fine-tuning jobs. For a 7B model with LoRA, expect $50 to $300 in compute for a full run. On-premise GPU clusters make sense for organizations that fine-tune regularly or handle data that cannot leave their environment.
Managed services like Together AI or Replicate handle all infrastructure for you at a higher per-token cost but with zero DevOps overhead.
Example: A healthcare startup used a managed service for their first project to avoid setup delays. Once they validated performance and decided to scale, they moved to self-hosted on AWS and cut ongoing inference costs by 60%.
Step 6: Fine-Tune Your Model
Three methods cover the majority of business use cases.
LoRA is the recommended starting point. It injects small trainable matrices into the model without updating all weights, cutting memory and training time dramatically while delivering performance close to full fine-tuning. Most successful business LLM deployments in 2025 use LoRA.
QLoRA is a quantized version of LoRA that reduces GPU memory requirements further. It makes fine-tuning a 65B model possible on a single consumer GPU and is the practical choice when hardware is your primary constraint.
Full fine-tuning updates all weights and delivers the strongest results for highly specialized domains. It requires significantly more compute and is typically reserved for enterprise teams with large, high-quality proprietary datasets.
Example: A B2B SaaS company used QLoRA to fine-tune Llama 3 13B on a single A100 over a weekend. The total compute cost was under $200. Two iterations with human evaluation between runs resulted in a model ready for production.
Step 7: Evaluate and Test the Model
Never deploy without structured testing. Run automated benchmarks on a held-out test set using metrics relevant to your task: F1 for classification, ROUGE for summarization, and BLEU for generation. But do not stop there.
Build a domain-specific evaluation set of 100 to 500 curated questions and answer pairs that represent your actual production use case. Then red-team it. Probe for hallucinations, confidently wrong answers on edge cases, and prompt injection vulnerabilities.
Finally, you have three to five domain experts rate 50 or more responses on accuracy, tone, and compliance. Human evaluation catches what automated metrics miss.
Example: A customer service LLM passed all automated benchmarks. Human evaluation by senior support agents revealed that it was giving tonally wrong responses to distressed customers. One additional fine-tuning iteration fixed it before launch.
Step 8: Deploy, Integrate, and Monitor in Production
Choose your hosting based on privacy requirements and traffic volume. Self-hosting using vLLM or Ollama gives full control and the lowest long-term cost. Managed inference platforms offer faster time-to-production. Proprietary APIs are fastest but least private.
Always put a proper API layer in front of the model with authentication, rate limiting, and input validation. Implement output filters and guardrails to catch edge cases before they reach users.
Then monitor continuously: track response latency, token usage, user satisfaction signals, and run your evaluation set on a regular cadence to catch model drift early.
Example: A retail company deployed without output monitoring. Three weeks in, a prompt injection attack caused the model to recommend competitor products. A monitoring layer would have flagged it within hours instead of the three days it took to catch manually.
The most important thing to remember: Steps 1 and 4 determine 80% of your outcome. A precisely defined use case and clean training data will outperform a technically sophisticated model built on a vague objective and dirty data every single time.
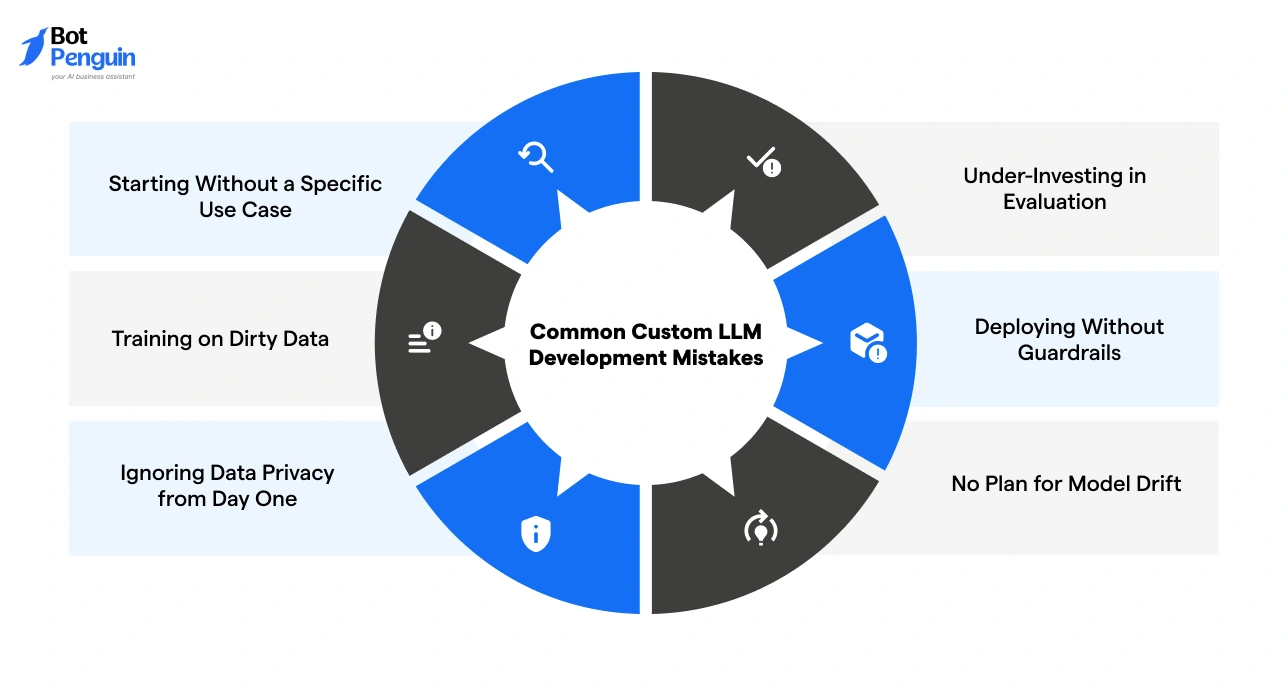
What are the Most Common Custom LLM Development Mistakes?
Most custom LLM projects that fail do not fail because of the technology. They fail because of decisions made in the first two weeks. Here are the six mistakes that consistently derail projects across companies of every size.
Mistake 1: Starting Without a Specific Use Case
Teams jump straight to data collection and model selection without defining what the model needs to do, for whom, and how success will be measured.
The result is a technically functional model that solves no measurable business problem.
Key signs you are making this mistake:
Your objective contains words like "improve," "enhance," or "optimize" with no measurable metric attached
Different stakeholders describe the project differently when asked
You have not written a single success KPI before starting data collection
Example: A retail company spent 14 weeks building a custom LLM described internally as an "AI assistant for operations." At launch, nobody could agree on what it was supposed to do. The project was shelved.
Mistake 2: Training on Dirty Data
Garbage in, garbage out is never truer than in LLM fine-tuning. A model trained on duplicate, inconsistent, or off-topic data will perform worse than the base model you started with, and you will have no clear idea why until you are already weeks behind schedule.
Watch out for:
Using raw database exports without cleaning or deduplication
Including off-topic documents because "more data seems better."
Skipping PII removal and discovering it mid-evaluation
Mixing data from different time periods with conflicting information
Example: An insurance company trained its first model on unfiltered customer emails, including complaints, spam, and internal test messages. The model learned to respond with confused, contradictory outputs. A full data restart cost them four weeks.
Mistake 3: Ignoring Data Privacy from Day One
If you are handling customer PII in your training data and have not mapped your GDPR, HIPAA, or SOC 2 obligations before training begins, you are one audit away from a serious compliance problem.
Privacy cannot be retrofitted into a model that has already been trained on non-compliant data.
Common oversights include:
Training on customer chat logs without anonymization
Using third-party datasets without verifying their licensing terms
Deploying a self-hosted model on infrastructure that has not passed your security review
Not documenting what data was used for training and why
Example: A healthtech startup trained its LLM on patient intake forms without a proper data processing agreement in place. A routine compliance audit six months after launch required them to retrain the model entirely on properly anonymized data.
Mistake 4: Under-Investing in Evaluation
"It seems to work" is not a QA process. Teams that skip structured evaluation before deployment consistently discover failure modes in production that cost significantly more to fix than a proper pre-launch testing cycle would have.
Signs your evaluation is not thorough enough:
You have only tested with examples you wrote yourself
No domain expert has reviewed model outputs before launch
You have not red-teamed for hallucinations or prompt injection
Your evaluation set overlaps with your training data
Example: A legal tech company launched its contract review LLM after internal testing by its engineering team.
Within two weeks, a client flagged that the model was confidently misidentifying governing law clauses in non-US contracts. A proper domain expert evaluation would have caught it before launch.
Mistake 5: Deploying Without Guardrails
An unguarded LLM in production will eventually produce a bad output. It is not a question of if, it is a question of when and how bad.
Output filtering, input validation, and circuit breakers are not optional extras. They are the difference between a recoverable incident and a reputational one.
Guardrails to put in place before go-live:
Input validation to catch prompt injection attempts
Output filters to flag responses outside acceptable parameters
Confidence thresholds that route low-confidence outputs to human review
Rate limiting to prevent abuse and runaway API costs
Example: A financial services firm deployed its customer-facing LLM without output filtering. A user discovered they could prompt the model into speculating about specific stock prices. The firm had to take the product offline for two weeks to add proper guardrails.
Mistake 6: No Plan for Model Drift
Your model was trained on yesterday's data. Your business, your customers, and your industry keep evolving.
A model with no maintenance plan will quietly degrade over time, giving increasingly stale or inaccurate outputs while your team assumes everything is fine because nobody set up monitoring.
Build these into your roadmap from day one:
A held-out evaluation set you re-run on a monthly cadence
User satisfaction tracking with a simple feedback mechanism
A quarterly review cycle to assess whether retraining is needed
Clear ownership of who is responsible for model performance post-launch
Example: A SaaS company deployed a custom LLM for product documentation queries. Eight months later, user satisfaction scores had quietly dropped by 40% because two major product updates had made large portions of the training data outdated. No monitoring was in place to catch it.
The pattern across all six mistakes is the same. The teams that avoid them treat custom LLM development as a product launch, not a one-time engineering project. They define success upfront, protect their data, test rigorously, and build for the long term from day one.
Let me fetch the BotPenguin website first to make sure the pitch is accurate . Here's the conclusion:
Building a Custom LLM Is Only Half the Battle
Custom LLM development is not a one-time project. It is an ongoing capability. The companies getting the most value from it are not the ones that built the most technically sophisticated model.
They are the ones who defined the right use case, prepared clean data, tested rigorously, and built a system that improves over time.
The 8-step process in this guide gives you the full roadmap. What it cannot give you is the deployment layer that turns a well-trained model into a business outcome your customers and team actually experience every day.
That is where the real work begins.
Where Does BotPenguin Fit In?
Once your custom LLM is trained, it needs to reach your customers. Across WhatsApp, your website, Instagram, Facebook, Telegram, and every other channel they use.
BotPenguin is an AI chatbot and agent platform that connects your custom LLM to all of these channels without you having to build separate integrations for each one.
Instead of spending months wiring your model into WhatsApp's API, then your website, then your CRM, BotPenguin handles the entire deployment layer so your model is live across every channel your customers are on in a fraction of the time.
Here is what that looks like in practice:
You build and fine-tune your custom LLM on your domain data
BotPenguin connects it to your website chatbot, WhatsApp bot, Instagram DMs, Facebook Messenger, and more
Your AI agents handle lead generation, appointment booking, customer support, and sales conversations across all channels simultaneously.y
Your team manages everything from a single unified inbox
For businesses that want to go further, BotPenguin also offers white-label AI agents, custom chatbot development, and ChatGPT-powered solutions that can be built on top of your custom LLM or deployed as a standalone solution while your LLM project is in progress.
The result is not just a trained model sitting on a server. It is a fully deployed AI system that works across every touchpoint your business has with its customers.
Ready to Deploy Your Custom LLM Across Every Channel?
BotPenguin makes it simple to connect your custom language model to WhatsApp, your website, Instagram, Facebook, Telegram, and more, with AI agents that handle support, lead generation, bookings, and sales on autopilot.
No separate integrations. No months of deployment work. Just your model, live across every channel, working for your business around the clock.
Connect Custom LLM to WhatsApp, Website & More
Deploy LLM-Powered Chatbots Instantly
Frequently Asked Questions (FAQS)
How is custom LLM development different from just using the ChatGPT API?
Unlike the ChatGPT API, customized large language models are trained on your proprietary data, hosted in your own environment, with no third-party data exposure, no ongoing API dependency, and significantly lower inference costs at scale.
Can LLM customization work for small businesses or is it only for enterprises?
Yes. LLM customization via LoRA fine-tuning can cost under $500 in compute alone. Customer support automation and internal knowledge management deliver the fastest ROI for small businesses without requiring large or complex models.
What data do I need to customize LLM models for my specific business use case?
You do not need millions of documents. A dataset of 1,000 to 10,000 curated examples is enough. Labeled question and answer pairs reflecting real interactions are the most valuable data type. Quality matters more than volume.
How do I keep custom large language models secure and prevent data leaks in production?
Host in your private cloud, put a hardened API layer in front, implement output filters, and conduct regular red-teaming. For regulated industries, align your custom large language model architecture with GDPR, HIPAA, or SOC 2 from day one.
Do customized large language models require retraining every time business data changes?
No. A RAG architecture lets customized large language models pull from an updated knowledge base without retraining. For stable domains, quarterly fine-tuning is sufficient. Full retraining from scratch is rarely needed once a model is in production.
What is the difference between an AI chatbot and a custom large language model, and do I need both?
A custom large language model is the intelligence layer. An AI chatbot connects it to your users across channels. You need both for a complete solution. BotPenguin connects your customized large language model to every customer channel without separate integrations.See how BotPenguin works →
How do I measure ROI after I customize LLM models for my business?
Compare pre-deployment baseline against post-deployment KPIs. Common metrics include reduction in support ticket volume, hours saved per employee, improved lead qualification rate, and faster document processing. High-volume repetitive tasks deliver the clearest ROI from LLM customization.
Can customized large language models be deployed on WhatsApp and other messaging channels?
Yes. Customized large language models are channel-agnostic and connect to WhatsApp, Instagram, Facebook Messenger, Telegram, and website chat through an API layer. BotPenguin handles these integrations so you do not have to build them separately. Explore BotPenguin →
Your Competitors Are Already Building Custom LLMs. Are You?
Stop relying on generic AI that doesn't know your business. Build a custom LLM trained on your data and deploy it across every customer channel with BotPenguin.

![Custom LLM Development_ Step-by-Step Guide [2026]](https://cdn-cms.botpenguin.com/cms/1776685288535_CustomLLMDevelopmentStepbyStepGuide2026.webp)